This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
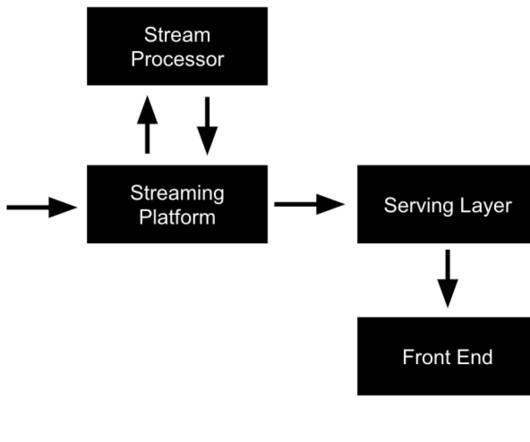
Building a Business with a Real-Time Analytics Stack, Streaming ML Without a DataLake, and Google’s PaLM 2 Building a Pizza Delivery Service with a Real-Time Analytics Stack The best businesses react quickly and with informed decisions. Here’s a use case of how you can use a real-time analytics stack to build a pizza delivery service.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Enter a stack name, such as Demo-Redshift. yaml locally.
Expo Hall ODSC events are more than just data science training and networking events. On both days, we had our AI Expo & Demo Hall where over a dozen of our partners set up to showcase their latest developments, tools, frameworks, and other offerings. You can read the recap here and watch the full keynote here.
Databricks Databricks is the developer of Delta Lake, an open-source project that brings reliability to datalakes for machine learning and other cases. Their platform was developed for working with Spark and provides automated cluster management and Python-style notebooks.
It won’t be a long demo, it’ll be a very quick demo of what you can do and how you can operationalize stuff in Snowflake. And so data scientists might be leveraging one compute service and might be leveraging an extracted CSV for their experimentation. The demo is actually very simple.
It won’t be a long demo, it’ll be a very quick demo of what you can do and how you can operationalize stuff in Snowflake. And so data scientists might be leveraging one compute service and might be leveraging an extracted CSV for their experimentation. The demo is actually very simple.
It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
The pipelines are interoperable to build a working system: Data (input) pipeline (data acquisition and feature management steps) This pipeline transports raw data from one location to another. Model/training pipeline This pipeline trains one or more models on the training data with preset hyperparameters. Kale v0.7.0.
When a query is constructed, it passes through a cost-based optimizer, then data is accessed through connectors, cached for performance and analyzed across a series of servers in a cluster. Because of its distributed nature, Presto scales for petabytes and exabytes of data.
An ML platform standardizes the technology stack for your data team around best practices to reduce incidental complexities with machine learning and better enable teams across projects and workflows. We ask this during product demos, user and support calls, and on our MLOps LIVE podcast. Data engineers are mostly in charge of it.
Snorkel Flow’s programmatic labeling process starts with labeling functions—essentially programmable rules to label data. Snorkel Flow users can build labeling functions according to various data features—from continuous variable thresholds to vector embedding clusters. Book a demo today.
Snorkel Flow’s programmatic labeling process starts with labeling functions—essentially programmable rules to label data. Snorkel Flow users can build labeling functions according to various data features—from continuous variable thresholds to vector embedding clusters. Book a demo today.
A lot of them are demos at that point, they’re still not products. You have your: feature store model registry data from a datalake The data is then moved across this workflow, modeled and then deployed, Now there’s a good link between your development environments and the production environment where it’s monitoring.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content