This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datamining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging datamining to gain a competitive edge, improve decision-making, and optimize operations.
What is an online transaction processing database (OLTP)? OLTP is the backbone of modern data processing, a critical component in managing large volumes of transactions quickly and efficiently. This approach allows businesses to efficiently manage large amounts of data and leverage it to their advantage in a highly competitive market.
This data alone does not make any sense unless it’s identified to be related in some pattern. Datamining is the process of discovering these patterns among the data and is therefore also known as Knowledge Discovery from Data (KDD). Machine learning provides the technical basis for datamining.
Amidst the buzz surrounding big data technologies, one thing remains constant: the use of Relational Database Management Systems (RDBMS). The foundation of data – RDBMS as the bedrock Imagine building a skyscraper without a solid foundation—it would crumble under its own weight.
Each of the following datamining techniques cater to a different business problem and provides a different insight. Knowing the type of business problem that you’re trying to solve will determine the type of datamining technique that will yield the best results. It is highly recommended in the retail industry analysis.
Data Management is considered to be a core function of any organization. Data management software helps in reducing the cost of maintaining the data by helping in the management and maintenance of the data stored in the database. There are various types of data management systems available.
By creating backups of the archived data, organizations can ensure that their data is safe and recoverable in case of a disaster or data breach. Databases are the unsung heroes of AI Furthermore, data archiving improves the performance of applications and databases.
Certainly, these predictions and classification help in uncovering valuable insights in datamining projects. ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. Both the hierarchical clustering and contentious clustering methods are seen as dendrogram.
Since Hadoop is designed to work with large computer clusters made from inexpensive commodity-grade PC hardware, it’s uniquely attractive to smaller businesses that need the same kind of power found at larger organizations without the upfront infrastructure investment. Creating One Centralized Storage Location.
Data warehouse, also known as a decision support database, refers to a central repository, which holds information derived from one or more data sources, such as transactional systems and relational databases. The data collected in the system may in the form of unstructured, semi-structured, or structured data.
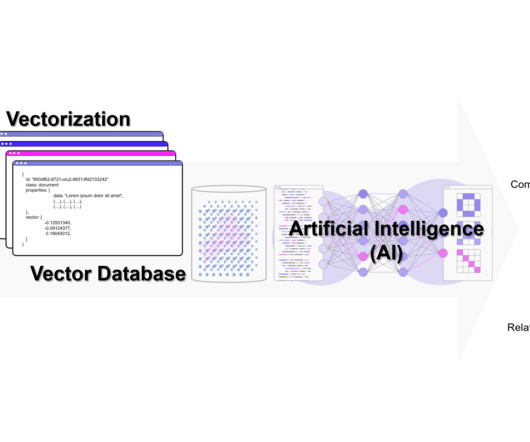
Meme shared by bin4ry_d3struct0r TAI Curated section Article of the week Building a YoutubeGPT with LangChain, Gradio, and Vector Database by Yanli Liu This article discusses the GenAI Application Development Stack, a key to creating customized AI solutions. It also explores key components like LangChain, Gradio, and Vector Database.
They’re looking to hire experienced data analysts, data scientists and data engineers. With big data careers in high demand, the required skillsets will include: Apache Hadoop. Software businesses are using Hadoop clusters on a more regular basis now. NoSQL and SQL. Machine Learning. Apache Spark. Other coursework.
Photo by Aditya Chache on Unsplash DBSCAN in Density Based Algorithms : Density Based Spatial Clustering Of Applications with Noise. Earlier Topics: Since, We have seen centroid based algorithm for clustering like K-Means.Centroid based : K-Means, K-Means ++ , K-Medoids. & One among the many density based algorithms is “DBSCAN”.
This code can cover a diverse array of tasks, such as creating a KMeans cluster, in which users input their data and ask ChatGPT to generate the relevant code. In the realm of data science, seasoned professionals often carry out research to comprehend how similar issues have been tackled in the past.
Common databases appear unable to cope with the immense increase in data volumes. This is where the BigQuery data warehouse comes into play. BigQuery operation principles Business intelligence projects presume collecting information from different sources into one database. BigQuery for Marketing: What Makes it Special?
There are different kinds of unsupervised learning algorithms, including clustering, anomaly detection, neural networks, etc. The algorithms will perform the task using unsupervised learning clustering, allowing the dataset to divide into groups based on the similarities between images. It can be either agglomerative or divisive.
Use cases include visualising distributions, relationships, and categorical data, effortlessly enhancing the aesthetics of your plots. It offers simple and efficient tools for datamining and Data Analysis. Scikit-learn covers various classification , regression , clustering , and dimensionality reduction algorithms.
Unveiling the Magic: The Core of Association Rule Mining At its core, ARM is a machine learning technique that identifies frequently occurring itemsets within a large dataset. Imagine a grocery store database meticulously recording customer purchases. No, ARM algorithms can be implemented within various datamining software tools.
At its core, decision intelligence involves collecting and integrating relevant data from various sources, such as databases, text documents, and APIs. This data is then analyzed using statistical methods, machine learning algorithms, and datamining techniques to uncover meaningful patterns and relationships.
Mastering programming, statistics, Machine Learning, and communication is vital for Data Scientists. A typical Data Science syllabus covers mathematics, programming, Machine Learning, datamining, big data technologies, and visualisation. SQL is indispensable for database management and querying.
Summary : This article equips Data Analysts with a solid foundation of key Data Science terms, from A to Z. Introduction In the rapidly evolving field of Data Science, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
Understanding Unstructured Data Unstructured data refers to data that does not have a predefined format or organization. Unlike structured data, which resides in databases and spreadsheets, unstructured data poses challenges due to its complexity and lack of standardization. within the text.
Pandas: A powerful library for data manipulation and analysis, offering data structures and operations for manipulating numerical tables and time series data. Scikit-learn: A simple and efficient tool for datamining and data analysis, particularly for building and evaluating machine learning models.
How to become a data scientist Data transformation also plays a crucial role in dealing with varying scales of features, enabling algorithms to treat each feature equally during analysis Noise reduction As part of data preprocessing, reducing noise is vital for enhancing data quality.
Scikit-Learn Scikit-Learn, or simply called SKLearn, is the most popular machine learning framework that supports various algorithms for classification, regression, and clustering. It is one of the most commonly used frameworks for datamining and analysis in the current scenario. Allows clustering of unstructured data.
SQL: Mastering Data Manipulation Structured Query Language (SQL) is a language designed specifically for managing and manipulating databases. While it may not be a traditional programming language, SQL plays a crucial role in Data Science by enabling efficient querying and extraction of data from databases.
The startup cost is now lower to deploy everything from a GPU-enabled virtual machine for a one-off experiment to a scalable cluster for real-time model execution. Deep learning - It is hard to overstate how deep learning has transformed data science. Data science processes are canonically illustrated as iterative processes.
Scikit-learn Scikit-learn is a machine learning library in Python that is majorly used for datamining and data analysis. It offers implementations of various machine learning algorithms, including linear and logistic regression , decision trees , random forests , support vector machines , clustering algorithms , and more.
Once the data is acquired, it is maintained by performing data cleaning, data warehousing, data staging, and data architecture. Data processing does the task of exploring the data, mining it, and analyzing it which can be finally used to generate the summary of the insights extracted from the data.
der k-Nächste-Nachbarn -Prädiktionsalgorithmus (Regression/Klassifikation) oder K-Means-Clustering. Die Texte müssen in diese transformiert werden, eventuell auch nach diesen in Cluster eingeteilt und für verschiedene Trainingsszenarien separiert werden. Die Ähnlichkeitsbetrachtung erfolgt mit Distanzmessung im Vektorraum.
Datamining has emerged as a vital tool in todays data-driven environment, enabling organizations to extract valuable insights from vast amounts of information. As businesses generate and collect more data than ever before, understanding how to uncover patterns and trends becomes essential for making informed decisions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content