This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datamining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging datamining to gain a competitive edge, improve decision-making, and optimize operations.
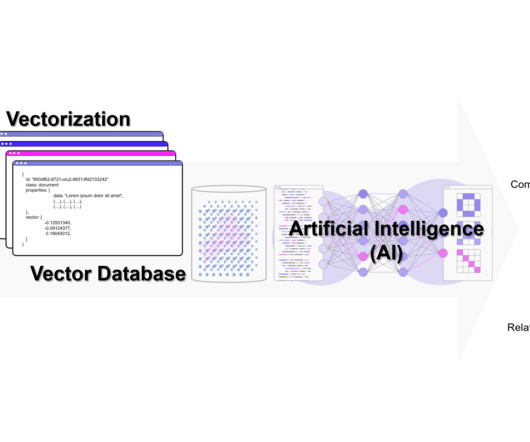
Vektor-Datenbanken sind ein weiterer Typ von Datenbank, die unter Einsatz von AI (DeepLearning, n-grams, …) Wissen in Vektoren übersetzen und damit vergleichbarer und wieder auffindbarer machen. der k-Nächste-Nachbarn -Prädiktionsalgorithmus (Regression/Klassifikation) oder K-Means-Clustering.
With that being said, let’s have a closer look at how unsupervised machine learning is omnipresent in all industries. What Is Unsupervised Machine Learning? If you’ve ever come across deeplearning, you might have heard about two methods to teach machines: supervised and unsupervised. Source ].
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
Here are the chronological steps for the data science journey. First of all, it is important to understand what data science is and is not. Data science should not be used synonymously with datamining. Mathematics, statistics, and programming are pillars of data science. Clustering (Unsupervised).
It is widely used for building and training machine learning models, particularly neural networks. – Example: Data scientists can utilize TensorFlow to develop and train deeplearning models for image recognition tasks. offers an open-source platform for scalable machine learning and deeplearning.
Artificial Intelligence graduate certificate by STANFORD SCHOOL OF ENGINEERING Artificial Intelligence graduate certificate; taught by Andrew Ng, and other eminent AI prodigies; is a popular course that dives deep into the principles and methodologies of AI and related fields. Generative AI with LLMs course by AWS AND DEEPLEARNING.AI
Photo by Aditya Chache on Unsplash DBSCAN in Density Based Algorithms : Density Based Spatial Clustering Of Applications with Noise. Earlier Topics: Since, We have seen centroid based algorithm for clustering like K-Means.Centroid based : K-Means, K-Means ++ , K-Medoids. & One among the many density based algorithms is “DBSCAN”.
The data is obtained from the Internet via APIs and web scraping, and the job titles and the skills listed in them are identified and extracted from them using Natural Language Processing (NLP) or more specific from Named-Entity Recognition (NER).
Evolutionary computing has been successfully applied to various problem domains, including optimization, machine learning, scheduling, datamining, and many others. These algorithms can automatically identify relevant features or combinations of features that maximize the predictive power of machine learning models.
Top 10 Best Data Science Project on Github 1. Face Recognition One of the most effective Github Projects on Data Science is a Face Recognition project that makes use of DeepLearning and Histogram of Oriented Gradients (HOG) algorithm. You will need to use the K-clustering method for this GitHub datamining project.
Scikit Learn Scikit Learn is a comprehensive machine learning tool designed for datamining and large-scale unstructured data analysis. With an impressive collection of efficient tools and a user-friendly interface, it is ideal for tackling complex classification, regression, and cluster-based problems.
Solving Machine Learning Tasks with MLCoPilot: Harnessing Human Expertise for Success Many of us have made use of large language models (LLMs) like ChatGPT to generate not only text and images but also code, including machine learning code. Vector databases can store them and are designed for search and datamining.
Recommendation Techniques Datamining techniques are incredibly valuable for uncovering patterns and correlations within data. Figure 5 provides an overview of the various datamining techniques commonly used in recommendation engines today, and we’ll delve into each of these techniques in more detail.
Matching von Zahlungsdaten zur Doppelzahlungserkennung oder die Vorhersage von Prozesszeiten), können mit Machine Learning bzw. DeepLearning auch anspruchsvollere Varianten-Cluster und Anomalien erkannt werden.
Unsupervised Learning Algorithms Unsupervised Learning Algorithms tend to perform more complex processing tasks in comparison to supervised learning. However, unsupervised learning can be highly unpredictable compared to natural learning methods. It can be either agglomerative or divisive.
Mastering programming, statistics, Machine Learning, and communication is vital for Data Scientists. A typical Data Science syllabus covers mathematics, programming, Machine Learning, datamining, big data technologies, and visualisation. What does a typical Data Science syllabus cover?
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deeplearning. Scikit-learn: A simple and efficient tool for datamining and data analysis, particularly for building and evaluating machine learning models.
A Complete Guide about K-Means, K-Means ++, K-Medoids & PAM’s in K-Means Clustering. A Complete Guide about K-Means, K-Means ++, K-Medoids & PAM’s in K-Means Clustering. To address such tasks and uncover behavioral patterns, we turn to a powerful technique in Machine Learning called Clustering. K = No of clusters.
It is mainly used for deeplearning applications. PyTorch PyTorch is a popular, open-source, and lightweight machine learning and deeplearning framework built on the Lua-based scientific computing framework for machine learning and deeplearning algorithms.
Topic Modeling Topic modeling is a text-mining technique used to uncover underlying themes or topics within a large collection of documents. It helps in discovering hidden patterns and organizing text data into meaningful clusters. Cluster similar documents based on their content and explore relationships between topics.
Synergy Between Artificial Intelligence and Data Science AI and Data Science complement each other through their unique but interconnected roles in data processing and analysis. Data Science involves extracting insights from structured and unstructured data using statistical methods, datamining, and visualisation techniques.
Summary : This article equips Data Analysts with a solid foundation of key Data Science terms, from A to Z. Introduction In the rapidly evolving field of Data Science, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
Moving the machine learning models to production is tough, especially the larger deeplearning models as it involves a lot of processes starting from data ingestion to deployment and monitoring. It provides different features for building as well as deploying various deeplearning-based solutions.
Applications: It is extensively used for statistical analysis, data visualisation, and machine learning tasks such as regression, classification, and clustering. PyTorch Functionality: PyTorch is an open-source machine learning library for Python developed by Facebook’s AI research group.
Once the data is acquired, it is maintained by performing data cleaning, data warehousing, data staging, and data architecture. Data processing does the task of exploring the data, mining it, and analyzing it which can be finally used to generate the summary of the insights extracted from the data.
It leverages algorithms to parse data, learn from it, and make predictions or decisions without being explicitly programmed. From decision trees and neural networks to regression models and clustering algorithms, a variety of techniques come under the umbrella of machine learning.
The startup cost is now lower to deploy everything from a GPU-enabled virtual machine for a one-off experiment to a scalable cluster for real-time model execution. Deeplearning - It is hard to overstate how deeplearning has transformed data science.
We cover the setup process and provide a step-by-step guide to running a NeMo job on a SageMaker HyperPod cluster. They are scalable and optimized for GPUs, making them ideal for curating natural language data to train or fine-tune LLMs. Prerequisites First, you deploy a SageMaker HyperPod cluster before running the job.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content