This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
.” Unsupervised learning: In this type of learning, the model is trained on unlabeled data, and it must discover patterns or structures within the data itself. This is used for tasks like clustering, dimensionality reduction, and anomaly detection. Python Explain the steps involved in training a decisiontree.
Machine Learning models play a crucial role in this process, serving as the backbone for various applications, from image recognition to natural language processing. In this blog, we will delve into the fundamental concepts of datamodel for Machine Learning, exploring their types. regression, classification, clustering).
Significantly, Supervised Learning is practical in two types of tasks- Classification: the goal is to predict a categorical label for each input data point Regression: the goal is to predict a continuous value. Significantly, there are two types of Unsupervised Learning: Clustering: which involves grouping similar data points together.
Using different machine learning algorithms for performance optimization: Several machine learning algorithms can be used for performance optimization, including regression, clustering, and decisiontrees. Clustering algorithms can be used to group users based on behavior patterns and optimize performance for each group.
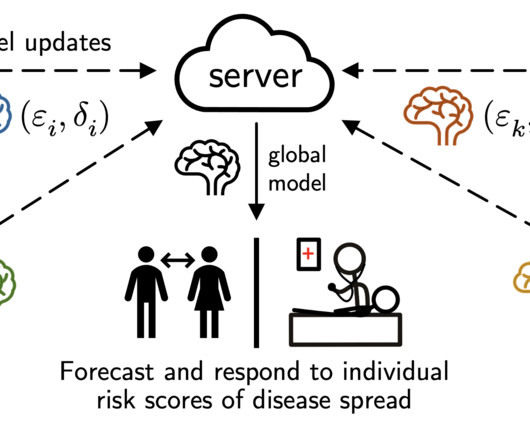
If local training minimizes the effect of data heterogeneity but enjoys no DP noise reduction, and contrarily for FedAvg, it is natural to wonder whether there are personalization methods that lie in between and achieve better utility. This is certainly not perfect as it ignores population-level modeling (e.g.
DecisionTrees These trees split data into branches based on feature values, providing clear decision rules. Unsupervised Learning Unsupervised learning involves training models on data without labels, where the system tries to find hidden patterns or structures.
Scikit-learn provides a consistent API for training and using machine learning models, making it easy to experiment with different algorithms and techniques. It also provides tools for model evaluation , including cross-validation, hyperparameter tuning, and metrics such as accuracy, precision, recall, and F1-score.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content