This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional vs vector databases Datamodels Traditional databases: They use a relational model that consists of a structured tabular form. Data is contained in tables divided into rows and columns. Hence, the data is well-organized and maintains a well-defined relationship between different entities.
.” Unsupervised learning: In this type of learning, the model is trained on unlabeled data, and it must discover patterns or structures within the data itself. This is used for tasks like clustering, dimensionality reduction, and anomaly detection.
In the skills for data analyst list, programming skills are essential since they enable data analysts to create automated workflows that can process large volumes of data quickly and efficiently, freeing up time to focus on higher-value tasks such as datamodeling and visualization.
The primary aim is to make sense of the vast amounts of data generated daily by combining statistical analysis, programming, and data visualization. It is divided into three primary areas: data preparation, datamodeling, and data visualization.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. It removes the undifferentiated heavy lifting involved in building and optimizing machine learning (ML) infrastructure for training foundation models (FMs).
Since the field covers such a vast array of services, data scientists can find a ton of great opportunities in their field. Data scientists use algorithms for creating datamodels. These datamodels predict outcomes of new data. Data science is one of the highest-paid jobs of the 21st century.
Thomson Reuters knew they would need to run a series of experiments—training LLMs from 7B to more than 30B parameters, starting with an FM and continuous pre-training (using various techniques) with a mix of Thomson Reuters and general data. Chinchilla point 52b 132b 260b 600b 1.3t So, for example, a 6.6B
While a Cassandra table’s compaction strategy can be adjusted after its creation, doing so invites costly cluster performance penalties because Cassandra will need to rewrite all of that table’s data. Taking […]. The post A Primer to Optimizing Your Apache Cassandra Compaction Strategy appeared first on DATAVERSITY.
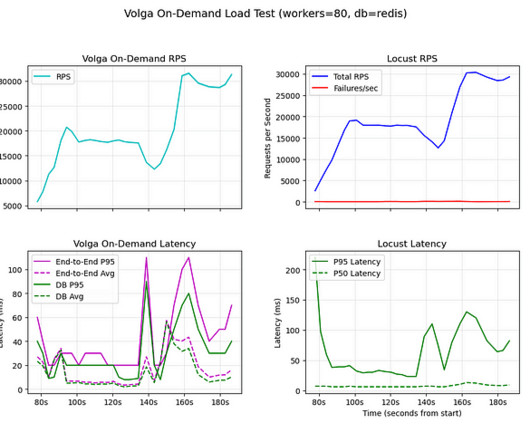
Tests setup We ran load tests on an Amazon EKS cluster using t2.medium medium instances (2 vCPUs, 4 GB RAM), hosting both the Locust deployment and the Ray cluster running Volga. Each Ray pod was mapped to a single EKS node to ensure resource isolation.
Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. Apache HBase was employed to offer real-time key-based access to data. This created a challenge for data scientists to become productive. HBase is employed to offer real-time key-based access to data.
It supports various data types and offers advanced features like data sharing and multi-cluster warehouses. Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). It allows data engineers to build, test, and maintain data pipelines in a version-controlled manner.
The capabilities of Lake Formation simplify securing and managing distributed data lakes across multiple accounts through a centralized approach, providing fine-grained access control. Solution overview We demonstrate this solution with an end-to-end use case using a sample dataset, the TPC datamodel. compute.internal.
and train models with a single click of a button. Advanced users will appreciate tunable parameters and full access to configuring how DataRobot processes data and builds models with composable ML. Explanations around data, models , and blueprints are extensive throughout the platform so you’ll always understand your results.
A data warehouse extracts data from a variety of sources and formats, including text files, excel sheets, multimedia files, and so on. The consolidated totals are saved in a datamodel in the HOLAP technique, while the particular data is maintained in a relational database.
They are a part of the data management system. A database consists of data structures or datamodels which are used to store and organize information. Datamodels help in storing and retrieving the data efficiently.
Flexibility and adaptability for evolving business requirements Simplified data integration and agility in datamodeling Incremental loading and historical data tracking capabilities Enhanced scalability and performance through parallel processing To get more information on the benefits of Data Vault with Snowflake, check out our blog!
NoSQL databases — NoSQL is a vast category that includes all databases that do not use SQL as their primary data access language. These databases do not comply with ACID properties which poses a threat to the consistency of the data stored in the database.
What if you could automatically shard your PostgreSQL database across any number of servers and get industry-leading performance at scale without any special datamodelling steps? Schema-based sharding has almost no datamodelling restrictions or special steps compared to unsharded PostgreSQL.
Model Selection: You need to choose an appropriate statistical model or technique that is based on the nature of the data and research question. This could be linear regression, logistic regression, clustering , time series analysis , etc. This may involve finding values that best represent to observed data.
Training steps To run the training, we use SLURM managed multi-node Amazon Elastic Compute Cloud ( Amazon EC2 ) Trn1 cluster, with each node containing a trn1.32xl instance. Next, we also evaluate the loss trajectory of the model training on AWS Trainium and compare it with the corresponding run on a P4d (Nvidia A100 GPU cores) cluster.
Machine Learning models play a crucial role in this process, serving as the backbone for various applications, from image recognition to natural language processing. In this blog, we will delve into the fundamental concepts of datamodel for Machine Learning, exploring their types. regression, classification, clustering).
Both databases are designed to handle large volumes of data, but they cater to different use cases and exhibit distinct architectural designs. Cassandra’s architecture is based on a peer-to-peer model where all nodes in the cluster are equal. Partition Key: Determines how data is distributed across nodes in the cluster.
Businesses today are grappling with vast amounts of data coming from diverse sources. To effectively manage and harness this data, many organizations are turning to a data vault—a flexible and scalable datamodeling approach that supports agile data integration and analytics.
Significantly, there are two types of Unsupervised Learning: Clustering: which involves grouping similar data points together. Effectively, some instances of unsupervised learning algorithms include k-means clustering, hierarchical clustering, principal component analysis (PCA), and association rule learning.
Besides easy access, using Trainium with Metaflow brings a few additional benefits: Infrastructure accessibility Metaflow is known for its developer-friendly APIs that allow ML/AI developers to focus on developing models and applications, and not worry about infrastructure.
When you design your datamodel, you’ll probably begin by sketching out your data in a graph format – representing entities as nodes and relationships as links. Working in a graph database means you can take that whiteboard model and apply it directly to your schema with relatively few adaptations.
The server aggregates these updates to build a global model, which is then sent back to all clients for further refinement. How It Works Model Training : Each client trains a model locally on its private data. The cluster servers then communicate with a central server to form the final global model.
Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance. Connecting to data is fundamental to all data work, which is why “get data'' is at the start of the Cycle of Visual Analysis. Gestalt properties including clusters are salient on scatters. Connectivity.
To set up this approach, a multi-cluster warehouse is recommended for stage loads, and separate multi-cluster warehouses can be used to run all loads in parallel. Variant columns can be used to store data that doesn’t fit neatly into traditional columns, such as nested data structures, arrays, or key-value pairs.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. This post delves into integrating Hugging Face’s PyAnnote for speaker diarization with Amazon SageMaker asynchronous endpoints. and requirements.txt files and save it as model.tar.gz : !
ETL Design Pattern The ETL (Extract, Transform, Load) design pattern is a commonly used pattern in data engineering. It is used to extract data from various sources, transform the data to fit a specific datamodel or schema, and then load the transformed data into a target system such as a data warehouse or a database.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to datamodeling, making it easier to ensure data quality and consistency across the ML pipelines.
Using different machine learning algorithms for performance optimization: Several machine learning algorithms can be used for performance optimization, including regression, clustering, and decision trees. Clustering algorithms can be used to group users based on behavior patterns and optimize performance for each group.
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. BigQuery supports various data ingestion methods, including batch loading and streaming inserts, while automatically optimizing query execution plans through partitioning and clustering.
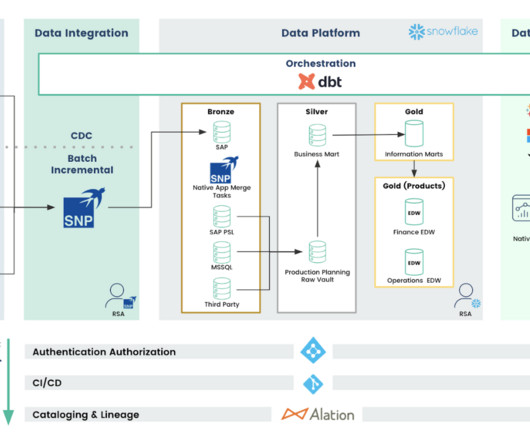
By centralizing SAP ERP data in Snowflake, organizations can gain deeper insights into key business metrics, trends, and performance indicators, enabling more informed decision-making, strategic planning, and operational optimization. Violations of license restrictions can result in penalties, additional fees, or even legal consequences.
As with most modeling challenges, the best solution is to work upstream, beginning with the Warehouse configuration, DataModeling approaches, and then identifying possible Sigma performance levels.
Python’s flexibility extends to its ability to handle a wide range of tasks, from quick scripting to complex datamodelling. This versatility makes Python perfect for developers who want to script applications, websites, or perform data-intensive tasks. It is particularly useful for complex Machine Learning tasks.
Multi-model databases combine graphs with two other NoSQL datamodels – document and key-value stores. RDF vs property graphs Another way to categorize graph databases is by their data structure. RDF vs property graphs Another way to categorize graph databases is by their data structure.
Solution overview This post demonstrates the use of SageMaker Training for running torchtune recipes through task-specific training jobs on separate compute clusters. SageMaker Training is a comprehensive, fully managed ML service that enables scalable model training. and more. linear: layers.31.mlp.w1,
Vector Embeddings for Developers: The Basics | Pinecone Used geometry concept to explain what is vector, and how raw data is transformed to embedding using embedding model. A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings.
Each node in my datamodel represents an earthquake, and each is colored and sized according to its magnitude: Red for a magnitude of 7+ (classed as ‘major’) Orange for a magnitude of 6 – 6.9 Filtering map data The network chart filtering we did earlier can also apply to map visualizations. Tōhoku earthquake.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
They are useful for big data analytics where flexibility is needed. DataModelingDatamodeling involves creating logical structures that define how data elements relate to each other. This includes: Dimensional Modeling : Organizes data into dimensions (e.g., time, product) and facts (e.g.,
Alternatively, you can create multiple streams and tasks from the same staging table to populate each data vault object using separate asynchronous flows. Data Vault Automation Working at scale can be challenging, especially when managing the datamodel. Implement Data Lineage and Traceability Path: Data Vault 2.0
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content