This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional vs vector databases Datamodels Traditional databases: They use a relational model that consists of a structured tabular form. Data is contained in tables divided into rows and columns. Hence, the data is well-organized and maintains a well-defined relationship between different entities.
The onset of the pandemic has triggered a rapid increase in the demand and adoption of ML technology. Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machine learning.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. HBase is employed to offer real-time key-based access to data.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. It removes the undifferentiated heavy lifting involved in building and optimizing machine learning (ML) infrastructure for training foundation models (FMs).
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. What does a modern technology stack for streamlined ML processes look like? Why: Data Makes It Different. All ML projects are software projects.
Data scientists often lack focus, time, or knowledge about software engineering principles. As a result, poor code quality and reliance on manual workflows are two of the main issues in ML development processes. You need to think about and improve the data, the model, and the code, which adds layers of complexity.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. Metaflow’s coherent APIs simplify the process of building real-world ML/AI systems in teams.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Thomson Reuters , a global content and technology-driven company, has been using artificial intelligence and machine learning (AI/ML) in its professional information products for decades. parameter model would require 132B input tokens and take just under 7 days to finish training with 64 A100 GPUs (or 8 P4d instances).
Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance. Connecting to data is fundamental to all data work, which is why “get data'' is at the start of the Cycle of Visual Analysis. Gestalt properties including clusters are salient on scatters. Connectivity.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. The capabilities of Lake Formation simplify securing and managing distributed data lakes across multiple accounts through a centralized approach, providing fine-grained access control.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. Hugging Face is a popular open source hub for machine learning (ML) models. He has more than 8 years of experience in AI/ML and 23 years of overall software development and sales experience.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
and train models with a single click of a button. Advanced users will appreciate tunable parameters and full access to configuring how DataRobot processes data and builds models with composable ML. Access the full potential of your models by using DataRobot with your text data.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. How do I develop my body of work?
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2
With the emergence of machine learning (ML), developers now have an innovative approach for optimizing AngularJS performance. In this article, we’ll explore the concept of using ML to enhance AngularJS performance and provide practical tips for implementing ML strategies in your development process.
Solution overview This post demonstrates the use of SageMaker Training for running torchtune recipes through task-specific training jobs on separate compute clusters. SageMaker Training is a comprehensive, fully managed ML service that enables scalable model training. The following diagram illustrates the solution architecture.
Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance. Connecting to data is fundamental to all data work, which is why “get data'' is at the start of the Cycle of Visual Analysis. Gestalt properties including clusters are salient on scatters. Connectivity.
Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. Fundamental Programming Skills Strong programming skills are essential for success in ML.
Accordingly, Machine Learning allows computers to learn and act like humans by providing data. Apparently, ML algorithms ensure to train of the data enabling the new data input to make compelling predictions and deliver accurate results. There are two types, including clustering and Association.
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model.
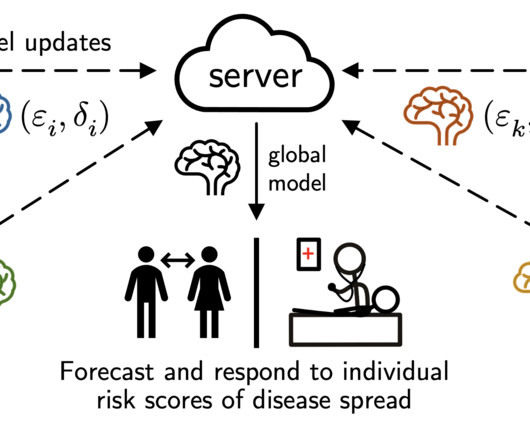
If local training minimizes the effect of data heterogeneity but enjoys no DP noise reduction, and contrarily for FedAvg, it is natural to wonder whether there are personalization methods that lie in between and achieve better utility. This is certainly not perfect as it ignores population-level modeling (e.g.
Based on our experience, manufacturing customers have the most success (in terms of adopting AI) with the following applications: Demand Forecasting Whether building better demand forecasts , optimizing logistics, scheduling production, or improving inventory management, ML-driven demand forecasting delivers real predictive value.
Source: [link] Similarly, while building any machine learning-based product or service, training and evaluating the model on a few real-world samples does not necessarily mean the end of your responsibilities. You need to make that model available to the end users, monitor it, and retrain it for better performance if needed.
ETL Design Pattern The ETL (Extract, Transform, Load) design pattern is a commonly used pattern in data engineering. It is used to extract data from various sources, transform the data to fit a specific datamodel or schema, and then load the transformed data into a target system such as a data warehouse or a database.
With the help of Snowflake clusters, organizations can effectively deal with both rush times and slowdowns since they ensure scalability upon demand. Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data.
Vector Embeddings for Developers: The Basics | Pinecone Used geometry concept to explain what is vector, and how raw data is transformed to embedding using embedding model. A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings.
The 8-billion-parameter model integrates grouped-query attention (GQA) for improved processing of longer data sequences, enhancing real-world application performance. Training involved a dataset of over 15 trillion tokens across two GPU clusters, significantly more than Meta Llama 2. Armando Diaz is a Solutions Architect at AWS.
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. What is Unstructured Data? Word2Vec , GloVe , and BERT are good sources of embedding generation for textual data.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. What is Unstructured Data?
ML-Based Approach: Rule-based approach fails to identify things like Irony and sarcasm, multiple types of negations, word ambiguity, and multipolarity in text. Due to this, businesses are now focusing on an ML-based approach, where different ML algorithms are trained on a large dataset of prelabeled text.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. You can learn more about the benefits of having a data pipeline in place here.
How implement modelsML fundamentals training and evaluation improve accuracy use library APIs Python and DevOps What when to use ML decide what models and components to train understand what application will use outputs for find best trade-offs select resources and libraries The “how” is everything that helps you execute the plan.
For instance, in a computation neuroscience startup, there are various teams – mathematicians, neuroscientists, AI/ML engineers, HR, etc. AI/ML engineers can use LLM as a code assistant to develop new models. At the same time, the AI/ML team needs an LLM to help design a novel neural network model.
One of the most prevalent complaints we hear from ML engineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets ML engineers build once, rerun, and reuse many times.
Although QLoRA helps optimize memory during fine-tuning, we will use Amazon SageMaker Training to spin up a resilient training cluster, manage orchestration, and monitor the cluster for failures. To take complete advantage of this multi-GPU cluster, we use the recent support of QLoRA and PyTorch FSDP. 24xlarge compute instance.
These models support mapping different data types like text, images, audio, and video into the same vector space to enable multi-modal queries and analysis. Because it’s serverless, it removes the operational complexities of provisioning, configuring, and tuning your OpenSearch clusters.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content