This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A provisioned or serverless Amazon Redshift data warehouse. For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. A SageMaker domain. A QuickSight account (optional). Database name : Enter dev.
Set up a datapipeline that delivers predictions to HubSpot and automatically initiate offers within the business rules you set. DataRobot AI Cloud offers an out-of-the-box, end-to-end Time Series Clustering feature that augments your AI forecasting by identifying groups or clusters of series with identical behavior.
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. You can view and create EMR clusters directly through the SageMaker notebook.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml
In this post, we discuss how to bring data stored in Amazon DocumentDB into SageMaker Canvas and use that data to build ML models for predictive analytics. Without creating and maintaining datapipelines, you will be able to power ML models with your unstructured data stored in Amazon DocumentDB.
It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable. Thirdly, there are improvements to demos and the extension for Spark. There is also work to support streaming inference requests in DJL Serving.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production. Let’s go and talk about machine learning pipelining.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production. Let’s go and talk about machine learning pipelining.
We’ll explore how factors like batch size, framework selection, and the design of your datapipeline can profoundly impact the efficient utilization of GPUs. We need a well-optimized datapipeline to achieve this goal. The pipeline involves several steps.
We frequently see this with LLM users, where a good LLM creates a compelling but frustratingly unreliable first demo, and engineering teams then go on to systematically raise quality. AI applications have always required careful monitoring of both model outputs and datapipelines to run reliably. Systems can be dynamic.
Kedro Kedro is a Python library for building modular data science pipelines. Kedro assists you in creating data science workflows composed of reusable components, each with a “single responsibility,” to speed up datapipelining, improve data science prototyping, and promote pipeline reproducibility.
We frequently see this with LLM users, where a good LLM creates a compelling but frustratingly unreliable first demo, and engineering teams then go on to systematically raise quality. AI applications have always required careful monitoring of both model outputs and datapipelines to run reliably. Systems can be dynamic.
Boost productivity – Empowers knowledge workers with the ability to automatically and reliably summarize reports and articles, quickly find answers, and extract valuable insights from unstructured data. The following demo shows Agent Creator in action. He currently is working on Generative AI for data integration.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a datapipeline. Conclusion To get started today with SnapGPT, request a free trial of SnapLogic or request a demo of the product. He currently is working on Generative AI for data integration.
An ML platform standardizes the technology stack for your data team around best practices to reduce incidental complexities with machine learning and better enable teams across projects and workflows. We ask this during product demos, user and support calls, and on our MLOps LIVE podcast. Data engineers are mostly in charge of it.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


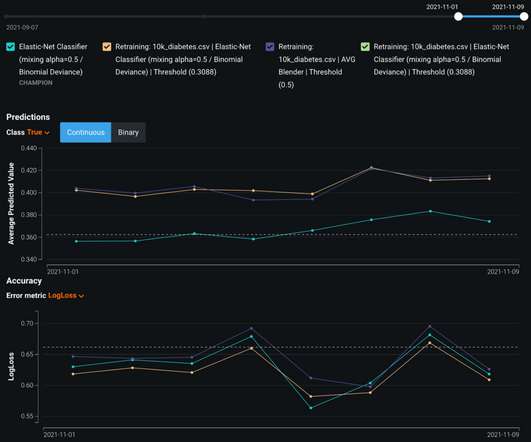



















Let's personalize your content