This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A provisioned or serverless Amazon Redshift data warehouse. For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. You can now view the predictions and download them as CSV. A SageMaker domain.
It is a cloud-native approach, and it suits a small team that does not want to host, maintain, and operate a Kubernetes cluster alonewith all the resulting responsibilities (and costs). The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines.
Apache Kafka plays a crucial role in enabling data processing in real-time by efficiently managing data streams and facilitating seamless communication between various components of the system. Apache Kafka Apache Kafka is a distributed event streaming platform used for building real-time datapipelines and streaming applications.
This post is a bitesize walk-through of the 2021 Executive Guide to Data Science and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Download the free, unabridged version here. Automation Automating datapipelines and models ➡️ 6.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file.
In this post, we discuss how to bring data stored in Amazon DocumentDB into SageMaker Canvas and use that data to build ML models for predictive analytics. Without creating and maintaining datapipelines, you will be able to power ML models with your unstructured data stored in Amazon DocumentDB.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
However, if there’s one thing we’ve learned from years of successful cloud data implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. Download a free PDF by filling out the form.
It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable. By default, it downloads the appropriate native binary based on your OS, CPU architecture, and CUDA version, making it almost effortless to use.
How Snowflake Helps Achieve Real-Time Analytics Snowflake is the ideal platform to achieve real-time analytics for several reasons, but two of the biggest are its ability to manage concurrency due to the multi-cluster architecture of Snowflake and its robust connections to 3rd party tools like Kafka.
When building your Processing Docker image, don't place any data required by your container in these directories. docker tag ${algorithm_name} ${fullname} docker push ${fullname} Running the SageMaker Processing job using the custom container Amazon SageMaker copies the data from S3 and then pulls the container.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
SciKit-Learn : A popular machine learning library with consistent APIs for regression, classification, clustering, dimensionality reduction, and model selection techniques. Central hubs like GitHub and GitLab along with dedicated data science notebooks enable exposure to real-world projects, accelerating practitioner skills.
Answering these questions allows data scientists to develop useful data products that start out simple and can be improved and made more complex over time until the long-term vision is achieved. At the strategy level, we are not interested in what technologies we will use for data warehousing, datapipelines, serving models, etc.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. The procedure loads a file into the database from S3, a copy of the processed data in the Snowflake.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















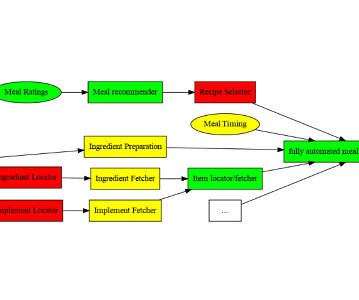







Let's personalize your content