This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis.
A provisioned or serverless Amazon Redshift data warehouse. For this post we’ll use a provisioned Amazon Redshift cluster. Basic knowledge of a SQL query editor. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. A SageMaker domain.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. It supports various data types and offers advanced features like data sharing and multi-cluster warehouses.
It is a cloud-native approach, and it suits a small team that does not want to host, maintain, and operate a Kubernetes cluster alonewith all the resulting responsibilities (and costs). The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines.
Apache Kafka plays a crucial role in enabling data processing in real-time by efficiently managing data streams and facilitating seamless communication between various components of the system. Apache Kafka Apache Kafka is a distributed event streaming platform used for building real-time datapipelines and streaming applications.
A lot of Open-Source ETL tools house a graphical interface for executing and designing DataPipelines. It can be used to manipulate, store, and analyze data of any structure. It generates Java code for the DataPipelines instead of running Pipeline configurations through an ETL Engine.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster.
Automation Automating datapipelines and models ➡️ 6. First, let’s explore the key attributes of each role: The Data Scientist Data scientists have a wealth of practical expertise building AI systems for a range of applications. The Data Engineer Not everyone working on a data science project is a data scientist.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Data warehouses and data lakes feel cumbersome and datapipelines just aren't agile enough.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Thirty seconds is a good default for human users; if you find that queries are regularly queueing, consider making your warehouse a multi-cluster that scales on-demand. Cluster Count If your warehouse has to serve many concurrent requests, you may need to increase the cluster count to meet demand.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building datapipelines.
Its PostgreSQL foundation ensures compatibility with most SQL clients. Architecture At its core, Redshift consists of clusters made up of compute nodes, coordinated by a leader node that manages communications, parses queries, and executes plans by distributing tasks to the compute nodes.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. They are crucial in ensuring data is readily available for analysis and reporting.
That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your datapipelines in a clean and efficient way. The most important reason for using DBT in Data Vault 2.0
IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run datapipelines. Key Features: Graphical Framework: Allows users to design datapipelines with ease using a graphical user interface. Read More: Advanced SQL Tips and Tricks for Data Analysts.
HPCC Systems and Spark also differ in that they work with distinct parts of the big datapipeline. Spark is more focused on data science, ingestion, and ETL, while HPCC Systems focuses on ETL and data delivery and governance. You describe HPCC Systems as a complete data lake platform. Can you get more granular?
It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Data warehouses and data lakes feel cumbersome and datapipelines just aren't agile enough.
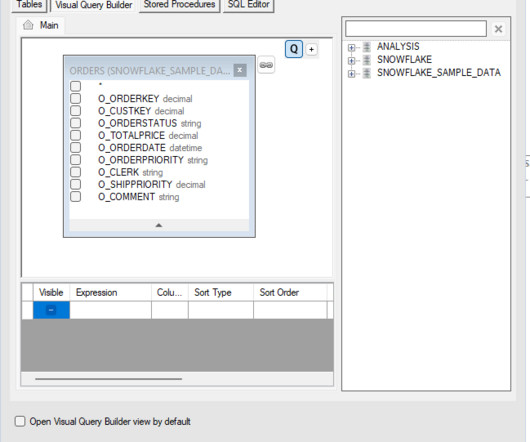
Under the Visual Query Builder , this pop-up window displays all databases, schemas, tables, and views accessible to the role defined, along with the option to write SQL directly when switching to the SQL Editor tab. In the showcased example, data manipulation involves datasets with over 100 million records.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
Setting up the Information Architecture Setting up an information architecture during migration to Snowflake poses challenges due to the need to align existing data structures, types, and sources with Snowflake’s multi-cluster, multi-tier architecture. Essentially, it functions like Google Translate — but for SQL dialects.
Kafka helps simplify the communication between customers and businesses, using its datapipeline to accurately record events and keep records of orders and cancellations—alerting all relevant parties in real-time.
Snowpark is the set of libraries and runtimes in Snowflake that securely deploy and process non-SQL code, including Python, Java, and Scala. A DataFrame is like a query that must be evaluated to retrieve data. An action causes the DataFrame to be evaluated and sends the corresponding SQL statement to the server for execution.
Introduction to LangChain for Including AI from Large Language Models (LLMs) Inside Data Applications and DataPipelines This article will provide an overview of LangChain, the problems it addresses, its use cases, and some of its limitations. Python : Great for including AI in Python-based software or datapipelines.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. With the help of Snowflake clusters, organizations can effectively deal with both rush times and slowdowns since they ensure scalability upon demand.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines.
Hive is a data warehouse tool built on Hadoop that enables SQL-like querying to analyse large datasets. What is the Difference Between Structured and Unstructured Data? Structured data is organised in tabular formats like databases, while unstructured data, such as images or videos, lacks a predefined format.
Snowflake stores and manages data in the cloud using a shared disk approach, which simplifies data management. The shared-nothing architecture ensures that users don’t have to worry about distributing data across multiple cluster nodes. This includes tasks such as data cleansing, enrichment, and aggregation.
This evolved into the phData Toolkit , a collection of high-quality data applications to help you migrate, validate, optimize, and secure your data. Operational Risks: Uncover operational risks such as data loss or failures in the event of an unforeseen outage or disaster. The Toolkit offers tools that range in capabilities.
SciKit-Learn : A popular machine learning library with consistent APIs for regression, classification, clustering, dimensionality reduction, and model selection techniques. Switching contexts across tools like Pandas, SciKit-Learn, SQL databases, and visualization engines creates cognitive burden.
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. In contrast, such traditional query languages struggle to interpret unstructured data. This text has a lot of information, but it is not structured.
Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well. While knowing Python, R, and SQL is expected, youll need to go beyond that. Employers arent just looking for people who can program.
To establish trust between the data producers and data consumers, SageMaker Catalog also integrates the data quality metrics and data lineage events to track and drive transparency in datapipelines. Create a SageMaker Unified Studio domain and three projects using the SQL analytics project profile.
It offers implementations of various machine learning algorithms, including linear and logistic regression , decision trees , random forests , support vector machines , clustering algorithms , and more. Apache Airflow Apache Airflow is an open-source workflow orchestration tool that can manage complex workflows and datapipelines.
Orchestrators are concerned with lower-level abstractions like machines, instances, clusters, service-level grouping, replication, and so on. Along with the schedulers, they are integral to managing the regular workflows your data scientists run and how the tasks in those workflows communicate with the ML platform.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. JV_STAGING_TBL} Here is what the outline of the pipeline looks like. Contact phData Today!
Essential technical skills Data preparation and mining: Proficiency in cleaning and organizing data effectively. Predictive modeling and machine learning: Familiarity with programming languages like Python, R, and SQL. Data visualization and storytelling: The ability to communicate findings clearly and effectively.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content