This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. The data mining process The data mining process is structured into four primary stages: data gathering, datapreparation, data mining, and data analysis and interpretation.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? By leveraging anomaly detection, we can uncover hidden irregularities in transaction data that may indicate fraudulent behavior.
Introduction to DeepLearning Algorithms: Deeplearning algorithms are a subset of machine learning techniques that are designed to automatically learn and represent data in multiple layers of abstraction. This process is known as training, and it relies on large amounts of labeled data.
The process begins with datapreparation, followed by model training and tuning, and then model deployment and management. Datapreparation is essential for model training and is also the first phase in the MLOps lifecycle. Unlike persistent endpoints, clusters are decommissioned when a batch transform job is complete.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
In the first part of our Anomaly Detection 101 series, we learned the fundamentals of Anomaly Detection and saw how spectral clustering can be used for credit card fraud detection. This method helps in identifying fraudulent transactions by grouping similar data points and detecting outliers. That’s not the case.
Please refer to Part 1– to understand what is Sales Prediction/Forecasting, the Basic concepts of Time series modeling, and EDA I’m working on Part 3 where I will be implementing DeepLearning and Part 4 where I will be implementing a supervised ML model. DataPreparation — Collect data, Understand features 2.
Given this mission, Talent.com and AWS joined forces to create a job recommendation engine using state-of-the-art natural language processing (NLP) and deeplearning model training techniques with Amazon SageMaker to provide an unrivaled experience for job seekers. It’s designed to significantly speed up deeplearning model training.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deeplearning. TensorFlow and Keras: TensorFlow is an open-source platform for machine learning.
Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster. In the processing job API, provide this path to the parameter of submit_jars to the node of the Spark cluster that the processing job creates. We attached the IAM role to the Redshift cluster that we created earlier.
Scikit Learn Scikit Learn is a comprehensive machine learning tool designed for data mining and large-scale unstructured data analysis. With an impressive collection of efficient tools and a user-friendly interface, it is ideal for tackling complex classification, regression, and cluster-based problems.
SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment. He focuses on developing scalable machine learning algorithms. In this section, we cover how to discover these models in SageMaker Studio.
Recent years have shown amazing growth in deeplearning neural networks (DNNs). Amazon SageMaker distributed training jobs enable you with one click (or one API call) to set up a distributed compute cluster, train a model, save the result to Amazon Simple Storage Service (Amazon S3), and shut down the cluster when complete.
This session covers the technical process, from datapreparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation. In this builders’ session, learn how to pre-train an LLM using Slurm on SageMaker HyperPod. You must bring your laptop to participate.
SageMaker pipeline steps The pipeline is divided into the following steps: Train and test datapreparation – Terabytes of raw data are copied to an S3 bucket, processed using AWS Glue jobs for Spark processing, resulting in data structured and formatted for compatibility.
See also MLOps Problems and Best Practices Addressing model environments Use ONNX ONNX ( Open Neural Network Exchange) | Source ONNX (Open Neural Network Exchange), an open-source format for representing deeplearning models, was developed by Microsoft and is now managed by the Linux Foundation.
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
A Multiclass Classification is a class of problems where a given data point is classified into one of the classes from a given list. Traditional Machine Learning and DeepLearning methods are used to solve Multiclass Classification problems, but the model’s complexity increases as the number of classes increases.
For example, in neural networks, data is represented as matrices, and operations like matrix multiplication transform inputs through layers, adjusting weights during training. Without linear algebra, understanding the mechanics of DeepLearning and optimisation would be nearly impossible.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Monitor the performance of machine learning models.
Unsupervised Learning In this type of learning, the algorithm is trained on an unlabeled dataset, where no correct output is provided. Performance Metrics These are used to evaluate the performance of a machine-learning algorithm. Some popular libraries used for deeplearning are Keras , PyTorch , and TensorFlow.
SageMaker notably supports popular deeplearning frameworks, including PyTorch, which is integral to the solutions provided here. Datapreparation and loading into sequence store The initial step in our machine learning workflow focuses on preparing the data.
These environments ranged from individual laptops and desktops to diverse on-premises computational clusters and cloud-based infrastructure. Improve the quality and time to market for deeplearning models in diagnostic medical imaging.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD. What is MLOps?
Key Takeaways Machine Learning Models are vital for modern technology applications. Types include supervised, unsupervised, and reinforcement learning. Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance. Random Forests).
As with SageMaker notebooks, you can also feed AWS CUR data into QuickSight for reporting or visualization purposes. SageMaker Data Wrangler Amazon SageMaker Data Wrangler is a feature of Studio that helps you simplify the process of datapreparation and feature engineering from a low-code visual interface.
These outputs, stored in vector databases like Weaviate, allow Prompt Enginers to directly access these embeddings for tasks like semantic search, similarity analysis, or clustering. Knowledge in these areas enables prompt engineers to understand the mechanics of language models and how to apply them effectively.
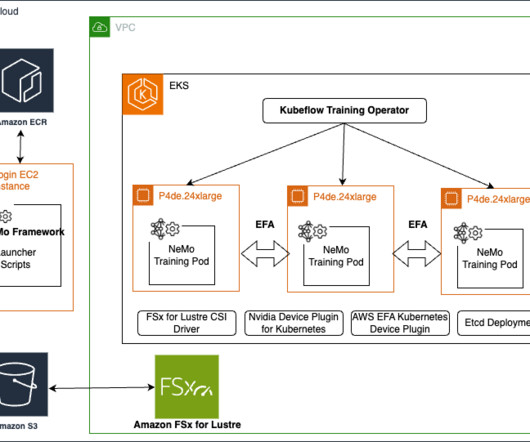
In this post, we present a step-by-step guide to run distributed training workloads on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster. The NVIDIA NeMo Framework provides a comprehensive set of tools, scripts, and recipes to support each stage of the LLM journey, from datapreparation to training and deployment.
It leverages algorithms to parse data, learn from it, and make predictions or decisions without being explicitly programmed. From decision trees and neural networks to regression models and clustering algorithms, a variety of techniques come under the umbrella of machine learning.
They classify, regress, or clusterdata based on learned patterns but do not create new data. In contrast, generative AI can handle unstructured data and produce new, original content, offering a more dynamic and creative approach to problem-solving. How is Generative AI Different from Traditional AI Models?
Databricks is getting up to 40% better price-performance with Trainium-based instances to train large-scale deeplearning models. Nobody else offers this same combination of choice of the best ML chips, super-fast networking, virtualization, and hyper-scale clusters.
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines.
We cover the setup process and provide a step-by-step guide to running a NeMo job on a SageMaker HyperPod cluster. It includes default configurations for compute cluster setup, data downloading, and model hyperparameters autotuning, which can be adjusted to train on new datasets and models.
We will start by setting up libraries and datapreparation. Course information: 86 total classes • 115+ hours of on-demand code walkthrough videos • Last updated: October 2024 ★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled I strongly believe that if you had the right teacher you could master computer vision and deeplearning.
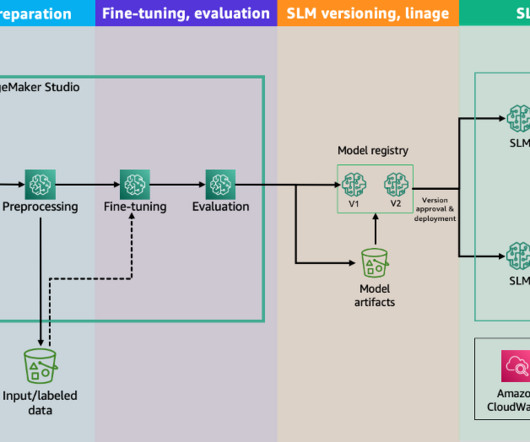
Solution overview This solution uses multiple features of SageMaker and Amazon Bedrock, and can be divided into four main steps: Data analysis and preparation – In this step, we assess the available data, understand how it can be used to develop solution, select data for fine-tuning, and identify required datapreparation steps.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content