This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
Scikit-learn can be used for a variety of data analysis tasks, including: Classification Regression Clustering Dimensionality reduction Feature selection Leveraging Scikit-learn in data analysis projects Scikit-learn can be used in a variety of data analysis projects. It is open-source, so it is free to use and modify.
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml For Prepare template , select Template is ready. Enter a stack name, such as Demo-Redshift. yaml locally. On the AWS CloudFormation console, choose Create stack.
As attendees circulate through the GAIZ, subject matter experts and Generative AI Innovation Center strategists will be on-hand to share insights, answer questions, present customer stories from an extensive catalog of reference demos, and provide personalized guidance for moving generative AI applications into production.
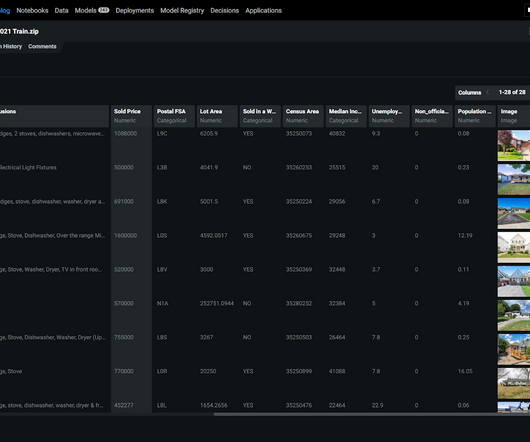
Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed. Data is split into a training dataset and a testing dataset. Details of the datapreparation code are in the following notebook.
Data scientists can best improve LLM performance on specific tasks by feeding them the right dataprepared in the right way. Representation models encode meaningful features from raw data for use in classification, clustering, or information retrieval tasks. Book a demo today.
And that’s really key for taking data science experiments into production. It won’t be a long demo, it’ll be a very quick demo of what you can do and how you can operationalize stuff in Snowflake. And finally, you’ll see that in action today. I don’t have a lot of time, so we’ll jump into it.
And that’s really key for taking data science experiments into production. It won’t be a long demo, it’ll be a very quick demo of what you can do and how you can operationalize stuff in Snowflake. And finally, you’ll see that in action today. I don’t have a lot of time, so we’ll jump into it.
The demo from the session highlights unique and differentiated capabilities that empower all users—from the analysts to the data scientists and even the person at the end of the journey who just needs to access an instant price estimate. Automated Feature Discovery is another differentiator that will have an impact in this use case.
Data scientists can best improve LLM performance on specific tasks by feeding them the right dataprepared in the right way. Representation models encode meaningful features from raw data for use in classification, clustering, or information retrieval tasks. Book a demo today.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Check out the Kubeflow documentation.
Again, what goes on in this component is subjective to the data scientist’s initial (manual) datapreparation process, the problem, and the data used. DEMO: End-to-end ML pipeline example In this example, you will build an ML pipeline with Kubeflow Pipelines based on the infamous Titanic ML competition on Kaggle.
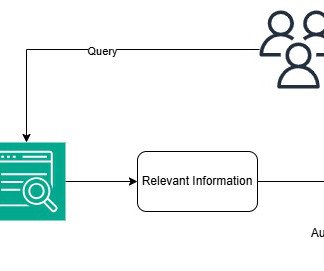
RAG retrieves data from a preexisting knowledge base (your data), combines it with the LLMs knowledge, and generates responses with more human-like language. However, in order for generative AI to understand your data, some amount of datapreparation is required, which involves a big learning curve. Choose Next.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content