This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Improve Cluster Balance with the CPD Scheduler — Part 1 The default Kubernetes (“k8s”) scheduler can be thought of as a sort of “greedy” scheduler, in that it always tries to place pods on the nodes that have the most free resources. This frequently exacerbates cluster imbalance. This can lead to performance problems and even outages.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. Dataset preparation for visual question and answering tasks The Meta Llama 3.2
Its agent for software development can solve complex tasks that go beyond code suggestions, such as building entire application features, refactoring code, or generating documentation. Attendees will learn practical applications of generative AI for streamlining and automating document-centric workflows. Hear from Availity on how 1.5
Scikit-learn can be used for a variety of data analysis tasks, including: Classification Regression Clustering Dimensionality reduction Feature selection Leveraging Scikit-learn in data analysis projects Scikit-learn can be used in a variety of data analysis projects.
Data scientists and data engineers use Apache Spark, Apache Hive, and Presto running on Amazon EMR for large-scale data processing. This blog post will go through how data professionals may use SageMaker Data Wrangler’s visual interface to locate and connect to existing Amazon EMR clusters with Hive endpoints.
The process begins with datapreparation, followed by model training and tuning, and then model deployment and management. Datapreparation is essential for model training and is also the first phase in the MLOps lifecycle. Unlike persistent endpoints, clusters are decommissioned when a batch transform job is complete.
Data preprocessing is essential for preparing textual data obtained from sources like Twitter for sentiment classification ( Image Credit ) Influence of data preprocessing on text classification Text classification is a significant research area that involves assigning natural language text documents to predefined categories.
For example, a use case that’s been moved from the QA stage to pre-production could be rejected and sent back to the development stage for rework because of missing documentation related to meeting certain regulatory controls. Datapreparation For this example, you will use the South German Credit dataset open source dataset.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
This helps with datapreparation and feature engineering tasks and model training and deployment automation. In both LSA and LDA, each document is treated as a collection of words only and the order of the words or grammatical role does not matter, which may cause some information loss in determining the topic.
We use the standard engineered features as input into the interaction encoder and feed the SBERT derived embedding into the query encoder and document encoder. Document encoder – The document encoder processes the information of each job listing. We enhance the embeddings through an SBERT model we fine-tuned.
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data.
Amazon SageMaker distributed training jobs enable you with one click (or one API call) to set up a distributed compute cluster, train a model, save the result to Amazon Simple Storage Service (Amazon S3), and shut down the cluster when complete. Finally, launching clusters can introduce operational overhead due to longer starting time.
Documented : Good model packaging includes clear code documentation that helps others understand how to use and modify the model if required. Documentation is critical to ensure that all teams can access the same information and collaborate effectively. To enhance collaboration and address model packaging challenges, neptune.ai
Datapreparation and loading into sequence store The initial step in our machine learning workflow focuses on preparing the data. e-]*)"} ] Finally, define a Pytorch estimator and submit a training job that refers to the data location obtained from the HealthOmics sequence store.
Table of Contents Introduction to PyCaret Benefits of PyCaret Installation and Setup DataPreparation Model Training and Selection Hyperparameter Tuning Model Evaluation and Analysis Model Deployment and MLOps Working with Time Series Data Conclusion 1. or higher and a stable internet connection for the installation process.
Thirty seconds is a good default for human users; if you find that queries are regularly queueing, consider making your warehouse a multi-cluster that scales on-demand. Cluster Count If your warehouse has to serve many concurrent requests, you may need to increase the cluster count to meet demand.
These environments ranged from individual laptops and desktops to diverse on-premises computational clusters and cloud-based infrastructure. Access to AWS environments SageMaker and associated AI/ML services are accessed with security guardrails for datapreparation, model development, training, annotation, and deployment.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
Applications : Stock price prediction and financial forecasting Analysing sales trends over time Demand forecasting in supply chain management Clustering Models Clustering is an unsupervised learning technique used to group similar data points together. Popular clustering algorithms include k-means and hierarchical clustering.
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
Unsupervised Learning Unsupervised learning involves training models on data without labels, where the system tries to find hidden patterns or structures. This type of learning is used when labelled data is scarce or unavailable. Data Transformation Transforming dataprepares it for Machine Learning models.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD.
Some LLMs also offer methods to produce embeddings for entire sentences or documents, capturing their overall meaning and semantic relationships. These outputs, stored in vector databases like Weaviate, allow Prompt Enginers to directly access these embeddings for tasks like semantic search, similarity analysis, or clustering.
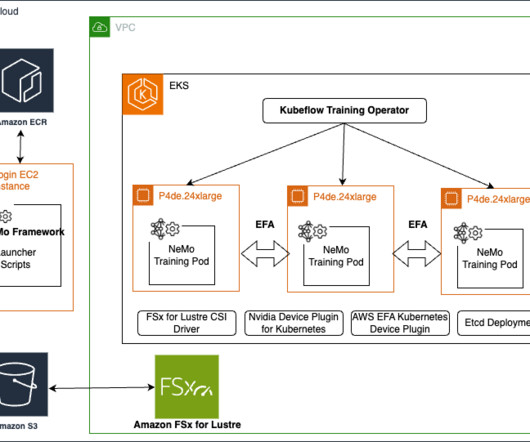
In this post, we present a step-by-step guide to run distributed training workloads on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster. The NVIDIA NeMo Framework provides a comprehensive set of tools, scripts, and recipes to support each stage of the LLM journey, from datapreparation to training and deployment.
Again, what goes on in this component is subjective to the data scientist’s initial (manual) datapreparation process, the problem, and the data used. Learn more about Metaflow in the documentation and get started through the tutorials or resource pages. Check out the documentation to get started.
Nobody else offers this same combination of choice of the best ML chips, super-fast networking, virtualization, and hyper-scale clusters. This typically involves a lot of manual work cleaning data, removing duplicates, enriching and transforming it. And we’ll continue to add more models to the Titan family over time.
Techniques such as embedding models like BERT are used to calculate similarity and rank documents based on relevance. Here, the documents are re-ranked based on their relevance, and the top documents are selected, which are then fed into the LLM for response generation.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines. Additionally, Feast promotes feature reuse, so the time spent on datapreparation is reduced greatly.
We cover the setup process and provide a step-by-step guide to running a NeMo job on a SageMaker HyperPod cluster. It includes default configurations for compute cluster setup, data downloading, and model hyperparameters autotuning, which can be adjusted to train on new datasets and models.
RAG retrieves data from a preexisting knowledge base (your data), combines it with the LLMs knowledge, and generates responses with more human-like language. However, in order for generative AI to understand your data, some amount of datapreparation is required, which involves a big learning curve.
Data preprocessing Text data can come from diverse sources and exist in a wide variety of formats such as PDF, HTML, JSON, and Microsoft Office documents such as Word, Excel, and PowerPoint. Its rare to already have access to text data that can be readily processed and fed into an LLM for training.
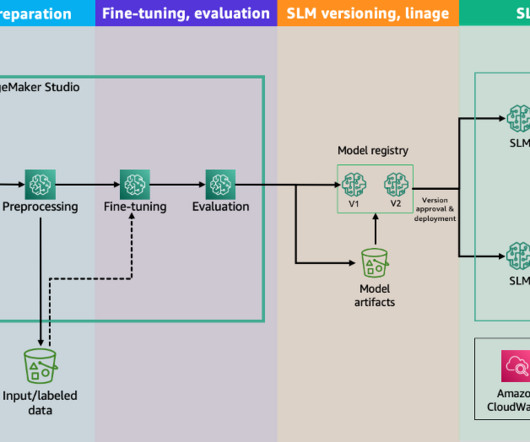
Solution overview This solution uses multiple features of SageMaker and Amazon Bedrock, and can be divided into four main steps: Data analysis and preparation – In this step, we assess the available data, understand how it can be used to develop solution, select data for fine-tuning, and identify required datapreparation steps.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content