This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? By leveraging anomaly detection, we can uncover hidden irregularities in transaction data that may indicate fraudulent behavior.
For Prepare template , select Template is ready. Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file. Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster. For Template source , select Upload a template file.
In the first part of our Anomaly Detection 101 series, we learned the fundamentals of Anomaly Detection and saw how spectral clustering can be used for credit card fraud detection. This method helps in identifying fraudulent transactions by grouping similar data points and detecting outliers. detection of potential failures or issues).
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
Scikit Learn Scikit Learn is a comprehensive machine learning tool designed for data mining and large-scale unstructured data analysis. With an impressive collection of efficient tools and a user-friendly interface, it is ideal for tackling complex classification, regression, and cluster-based problems.
It’s essential to review and adhere to the applicable license terms before downloading or using these models to make sure they’re suitable for your intended use case. SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment.
Inside the managed training job in the SageMaker environment, the training job first downloads the mouse genome using the S3 URI supplied by HealthOmics. Datapreparation and loading into sequence store The initial step in our machine learning workflow focuses on preparing the data.
Amazon SageMaker distributed training jobs enable you with one click (or one API call) to set up a distributed compute cluster, train a model, save the result to Amazon Simple Storage Service (Amazon S3), and shut down the cluster when complete. In his spare time, he enjoys cycling, hiking, and complaining about datapreparation.
For Secret type , choose Credentials for Amazon Redshift cluster. Enter the credentials used to log in to access Amazon Redshift as a data source. Choose the Redshift cluster associated with the secrets. This mechanism makes sure that prompts are readily available, reducing the overhead associated with frequent downloads.
However, if there’s one thing we’ve learned from years of successful cloud data implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. Download a free PDF by filling out the form.
Users can download datasets in formats like CSV and ARFF. It is a central hub for researchers, data scientists, and Machine Learning practitioners to access real-world data crucial for building, testing, and refining Machine Learning models. CSV, ARFF) to begin the download. What is the UCI Machine Learning Repository?
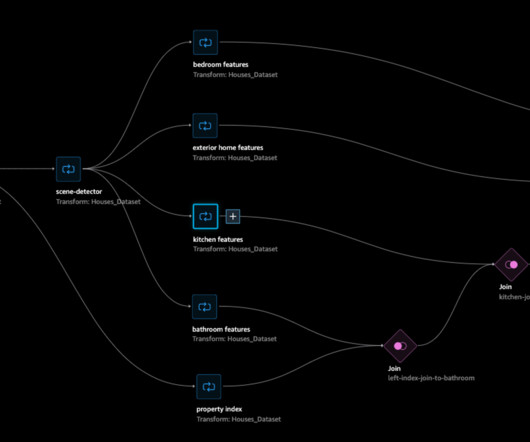
We selected the model with the most downloads at the time of this writing. 0, 1, 2 Reference architecture In this post, we use Amazon SageMaker Data Wrangler to ask a uniform set of visual questions for thousands of photos in the dataset. The next figure offers a view of how the full-scale data transformation job is run.
An AutoML tool applies a combination of different algorithms and various preprocessing techniques to your data. For example, it can scale the data, perform univariate feature selection, conduct PCA at different variance threshold levels, and apply clustering.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Check out the Kubeflow documentation.
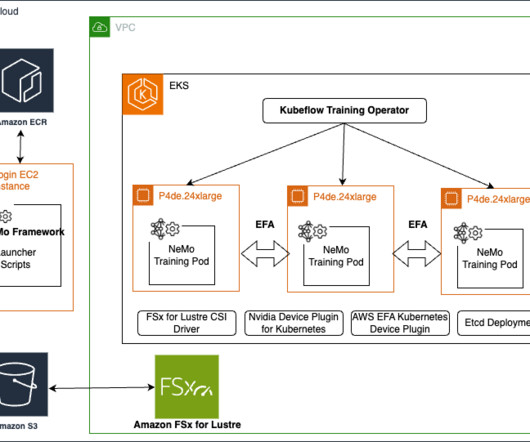
In this post, we present a step-by-step guide to run distributed training workloads on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster. The NVIDIA NeMo Framework provides a comprehensive set of tools, scripts, and recipes to support each stage of the LLM journey, from datapreparation to training and deployment.
You need data engineering expertise and time to develop the proper scripts and pipelines to wrangle, clean, and transform data. Afterward, you need to manage complex clusters to process and train your ML models over these large-scale datasets. These features can find temporal patterns in the data that can influence the baseFare.
Nobody else offers this same combination of choice of the best ML chips, super-fast networking, virtualization, and hyper-scale clusters. This typically involves a lot of manual work cleaning data, removing duplicates, enriching and transforming it.
We cover the setup process and provide a step-by-step guide to running a NeMo job on a SageMaker HyperPod cluster. It includes default configurations for compute cluster setup, datadownloading, and model hyperparameters autotuning, which can be adjusted to train on new datasets and models.
Data preprocessing Text data can come from diverse sources and exist in a wide variety of formats such as PDF, HTML, JSON, and Microsoft Office documents such as Word, Excel, and PowerPoint. Its rare to already have access to text data that can be readily processed and fed into an LLM for training.
Jump Right To The Downloads Section Understanding Network Intrusion and the Role of Anomaly Detection Imagine a scenario where a large financial institution suddenly notices an unusual spike in network traffic late at night. We will start by setting up libraries and datapreparation. Looking for the source code to this post?
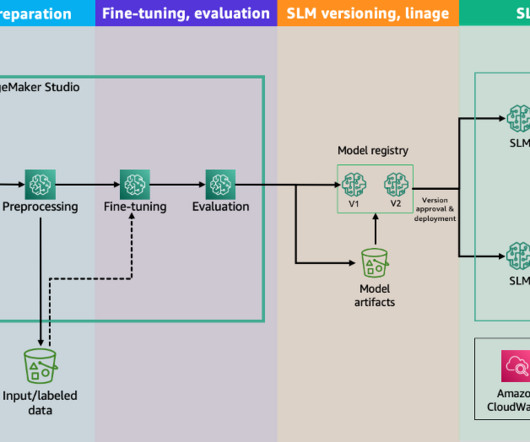
Solution overview This solution uses multiple features of SageMaker and Amazon Bedrock, and can be divided into four main steps: Data analysis and preparation – In this step, we assess the available data, understand how it can be used to develop solution, select data for fine-tuning, and identify required datapreparation steps.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content