

How Booking.com modernized its ML experimentation framework with Amazon SageMaker
AWS Machine Learning Blog
FEBRUARY 12, 2024
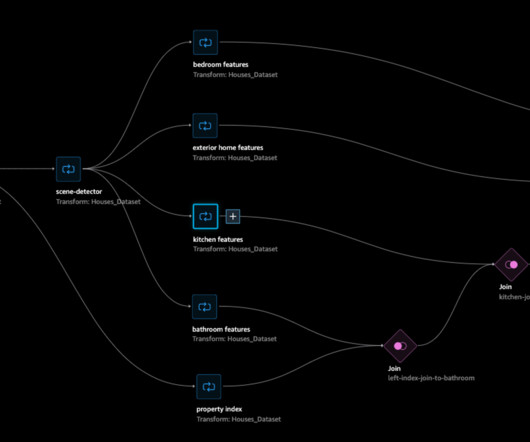
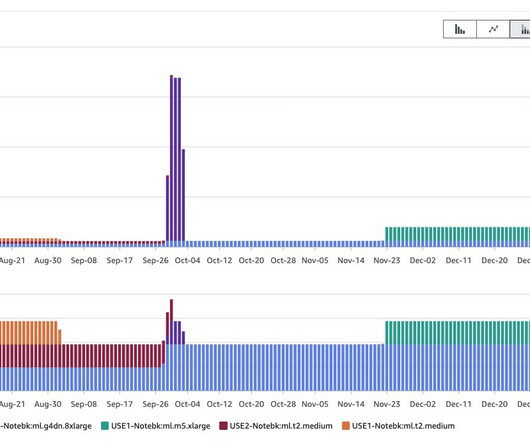
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.















































Let's personalize your content