This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
The primary aim is to make sense of the vast amounts of data generated daily by combining statistical analysis, programming, and data visualization. It is divided into three primary areas: datapreparation, data modeling, and data visualization.
PyTorch PyTorch is another open-source software library for numerical computation using data flow graphs. It is similar to TensorFlow, but it is designed to be more Pythonic. Scikit-learn Scikit-learn is an open-source machine learning library for Python. TensorFlow was also used by Netflix to improve its recommendation engine.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
We cover two approaches: using the Amazon SageMaker Studio UI for a no-code solution, and using the SageMaker Python SDK. FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. Fine-tune using the SageMaker Python SDK You can also fine-tune Meta Llama 3.2 Vision models.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from datapreparation and training to model deployment as automated workflows. In the next section, we highlight key code snippets from each step.
This session covers the technical process, from datapreparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation. Explore how this powerful tool streamlines the entire ML lifecycle, from datapreparation to model deployment.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
If you are prompted to choose a kernel, choose Data Science as the image and Python 3 as the kernel, then choose Select. as the image and Glue Python [PySpark and Ray] as the kernel, then choose Select. The environment preparation process may take some time to complete.
DataPreparation — Collect data, Understand features 2. Visualize Data — Rolling mean/ Standard Deviation— helps in understanding short-term trends in data and outliers. The rolling mean is an average of the last ’n’ data points and the rolling standard deviation is the standard deviation of the last ’n’ points.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Scikit Learn Scikit Learn is a comprehensive machine learning tool designed for data mining and large-scale unstructured data analysis. With an impressive collection of efficient tools and a user-friendly interface, it is ideal for tackling complex classification, regression, and cluster-based problems.
This allows scientists and model developers to focus on model development and rapid experimentation rather than infrastructure management Pipelines offers the ability to orchestrate complex ML workflows with a simple Python SDK with the ability to visualize those workflows through SageMaker Studio. tag = "latest" container_image_uri = "{0}.dkr.ecr.{1}.amazonaws.com/{2}:{3}".format(account_id,
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. Python script that serves as the entry point. client('s3') # Get the region name session = boto3.Session()
Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed. Data is split into a training dataset and a testing dataset. Details of the datapreparation code are in the following notebook.
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. Python is a High-level, Procedural, and object-oriented language; it is also a vast language itself, and covering the whole of Python is one the worst mistakes we can make in the data science journey.
Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. This growth signifies Python’s increasing role in ML and related fields.
Snowpark is the set of libraries and runtimes in Snowflake that securely deploy and process non-SQL code, including Python, Java, and Scala. On the server side, runtimes include Python, Java, and Scala in the warehouse model or Snowpark Container Services (public preview).
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. GPU PBAs, 4% other PBAs, 4% FPGA, and 0.5%
The expeditious and efficient construction, deployment, and scalability of machine learning models assume utmost importance in unearthing the untapped potential of data-driven decision-making. This extensive repertoire includes classification, regression, clustering, natural language processing, and anomaly detection.
Thirty seconds is a good default for human users; if you find that queries are regularly queueing, consider making your warehouse a multi-cluster that scales on-demand. Cluster Count If your warehouse has to serve many concurrent requests, you may need to increase the cluster count to meet demand.
The platform can assign specific roles to team members involved in the packaging process and grant them access to relevant aspects such as datapreparation, training, deployment, and monitoring. Developers can deploy their models on a cluster of servers and use Kubernetes to manage the resources needed for training and inference.
An AutoML tool applies a combination of different algorithms and various preprocessing techniques to your data. For example, it can scale the data, perform univariate feature selection, conduct PCA at different variance threshold levels, and apply clustering.
Feature engineering We perform two sets of feature engineering processes to extract valuable information from the raw data and feed it into the corresponding towers in the model: standard feature engineering and fine-tuned SBERT embeddings. Standard feature engineering Our datapreparation process begins with standard feature engineering.
Jupyter notebooks can differentiate between SQL and Python code using the %%sm_sql magic command, which must be placed at the top of any cell that contains SQL code. This command signals to JupyterLab that the following instructions are SQL commands rather than Python code. Choose the Redshift cluster associated with the secrets.
It is a central hub for researchers, data scientists, and Machine Learning practitioners to access real-world data crucial for building, testing, and refining Machine Learning models. The publicly available repository offers datasets for various tasks, including classification, regression, clustering, and more.
Applications : Stock price prediction and financial forecasting Analysing sales trends over time Demand forecasting in supply chain management Clustering Models Clustering is an unsupervised learning technique used to group similar data points together. Popular clustering algorithms include k-means and hierarchical clustering.
Augmented Analytics Combining Artificial Intelligence with traditional analytics allows businesses to gain insights more quickly by automating datapreparation processes. Programming Skills Proficiency in programming languages like Python and R is essential for Data Science professionals.
Additionally, you will work closely with cross-functional teams, translating complex data insights into actionable recommendations that can significantly impact business strategies and drive overall success. Also Read: Explore data effortlessly with Python Libraries for (Partial) EDA: Unleashing the Power of Data Exploration.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring. and Pandas or Apache Spark DataFrames.
Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance. UnSupervised Learning Unlike Supervised Learning, unSupervised Learning works with unlabeled data. The algorithm tries to find hidden patterns or groupings in the data.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD.
By implementing efficient data pipelines , organisations can enhance their data processing capabilities, reduce time spent on datapreparation, and improve overall data accessibility. Data Storage Solutions Data storage solutions are critical in determining how data is organised, accessed, and managed.
These outputs, stored in vector databases like Weaviate, allow Prompt Enginers to directly access these embeddings for tasks like semantic search, similarity analysis, or clustering. PythonPython’s prominence is expected. Kubernetes: A long-established tool for containerized apps.
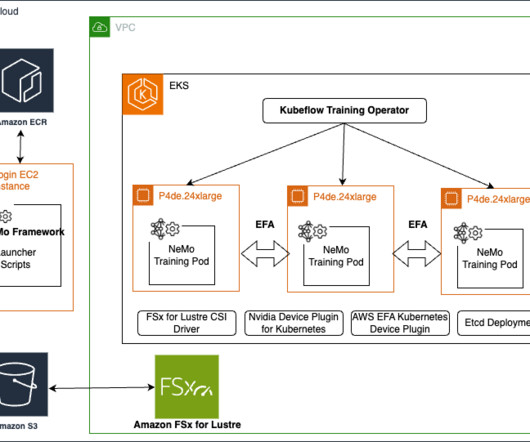
In this post, we present a step-by-step guide to run distributed training workloads on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster. The NVIDIA NeMo Framework provides a comprehensive set of tools, scripts, and recipes to support each stage of the LLM journey, from datapreparation to training and deployment.
Again, what goes on in this component is subjective to the data scientist’s initial (manual) datapreparation process, the problem, and the data used. Metaflow differs from other pipelining frameworks because it can load and store artifacts (such as data and models) as regular Python instance variables.
Nobody else offers this same combination of choice of the best ML chips, super-fast networking, virtualization, and hyper-scale clusters. This typically involves a lot of manual work cleaning data, removing duplicates, enriching and transforming it.
Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code. An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
We cover the setup process and provide a step-by-step guide to running a NeMo job on a SageMaker HyperPod cluster. is a flexible, IDE-independent Python-based framework that enables flexible integration in each developers workflow. In this blog post, we explore how to integrate NeMo 2.0 NeMo Framework 2.0
This strategic decision was driven by several factors: Efficient datapreparation Building a high-quality pre-training dataset is a complex task, involving assembling and preprocessing text data from various sources, including web sources and partner companies. The team opted for fine-tuning on AWS.
RAG retrieves data from a preexisting knowledge base (your data), combines it with the LLMs knowledge, and generates responses with more human-like language. However, in order for generative AI to understand your data, some amount of datapreparation is required, which involves a big learning curve.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content