This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. Flipping the paradigm: Using AI to enhance dataquality What if we could change the way we think about dataquality?
A Mixture Model Approach for Clustering Time Series Data By Shenggang Li This article explores a mixture model approach for clustering time series data, particularly focusing on financial and biological applications. Our must-read articles 1.
This article was published as a part of the Data Science Blogathon. Introduction In machine learning, the data is an essential part of the training of machine learning algorithms. The amount of data and the dataquality highly affect the results from the machine learning algorithms.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. It utilises the Hadoop Distributed File System (HDFS) and MapReduce for efficient data management, enabling organisations to perform big data analytics and gain valuable insights from their data.
Each source system had their own proprietary rules and standards around data capture and maintenance, so when trying to bring different versions of similar data together such as customer, address, product, or financial data, for example there was no clear way to reconcile these discrepancies. A data lake!
Beyond Scale: DataQuality for AI Infrastructure The trajectory of AI over the past decade has been driven largely by the scale of data available for training and the ability to process it with increasingly powerful compute & experimental models. Author(s): Richie Bachala Originally published on Towards AI.
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build data pipelines, and prepare data for analysis and consumption by other applications. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
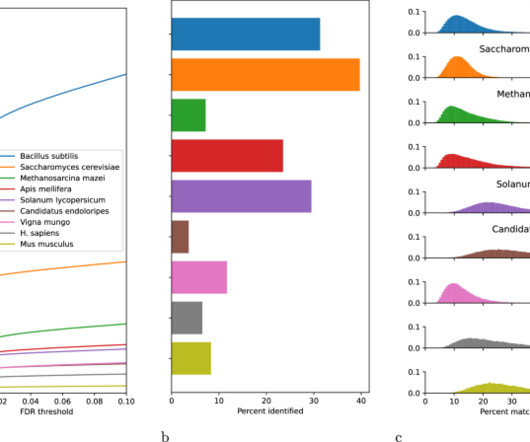
Training machine learning models for tasks such as de novo sequencing or spectral clustering requires large collections of confidently identified spectra. The dataset is based on a previously described benchmark but has been re-processed to ensure consistent dataquality and enforce separation of training and test peptides.
This framework creates a central hub for feature management and governance with enterprise feature store capabilities, making it straightforward to observe the data lineage for each feature pipeline, monitor dataquality , and reuse features across multiple models and teams.
Analyze the obtained sample data. Cluster Sampling Definition and applications Cluster sampling involves dividing a population into clusters or groups and selecting entire clusters at random for inclusion in the sample. Select clusters randomly from the population. Analyze the obtained sample data.
This means a schema forms a well-defined contract between a producing application and a consuming application, allowing consuming applications to parse and interpret the data in the messages they receive correctly. A schema registry supports your Kafka cluster by providing a repository for managing and validating schemas within that cluster.
However, there are also challenges that businesses must address to maximise the various benefits of data-driven and AI-driven approaches. Dataquality : Both approaches’ success depends on the data’s accuracy and completeness. Adapt models to new data and include the latest trends or patterns.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue DataQuality , Amazon Redshift ML , and Amazon QuickSight. You can review the recommendations and augment rules from over 25 included dataquality rules.
Introduction: The Reality of Machine Learning Consider a healthcare organisation that implemented a Machine Learning model to predict patient outcomes based on historical data. However, once deployed in a real-world setting, its performance plummeted due to dataquality issues and unforeseen biases. predicting house prices).
This blog post will go through how data professionals may use SageMaker Data Wrangler’s visual interface to locate and connect to existing Amazon EMR clusters with Hive endpoints. Solution overview With SageMaker Studio setups, data professionals can quickly identify and connect to existing EMR clusters.
In this blog post, we will delve into the mechanics of the Grubbs test, its application in anomaly detection, and provide a practical guide on how to implement it using real-world data. In quality control, an outlier could indicate a defect in a manufacturing process.
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. We can analyze activities by identifying stops made by the user or mobile device by clustering pings using ML models in Amazon SageMaker.
On the Import data page, for Data Source , choose DocumentDB and Add Connection. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster. Note that SageMaker Canvas will prepopulate the drop-down menu with clusters in the same VPC as your SageMaker domain.
It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
The outputs of this template are as follows: An S3 bucket for the data lake. An EMR cluster with EMR runtime roles enabled. Associating runtime roles with EMR clusters is supported in Amazon EMR 6.9. The EMR cluster should be created with encryption in transit. internal in the certificate subject definition.
Hadoop systems and data lakes are frequently mentioned together. Data is loaded into the Hadoop Distributed File System (HDFS) and stored on the many computer nodes of a Hadoop cluster in deployments based on the distributed processing architecture. It may be easily evaluated for any purpose.
Unlike supervised learning, where the algorithm is trained on labeled data, unsupervised learning allows algorithms to autonomously identify hidden structures and relationships within data. These algorithms can identify natural clusters or associations within the data, providing valuable insights for demand forecasting.
This business intelligence project transforms raw data into actionable insights, amplifying data-driven lending practices. Global health expenditure analysis The global health expenditure analysis project harnesses clustering analysis through Power BI and PyCaret. Featured image credit : rawpixel.com/Freepik.
Data Virtualization can include web process automation tools and semantic tools that help easily and reliably extract information from the web, and combine it with corporate information, to produce immediate results. How does Data Virtualization manage dataquality requirements? In forecasting future events.
This is only clearer with this week’s news of Microsoft and OpenAI planning a >$100bn 5 GW AI data center for 2028. This would be its 5th generation AI training cluster. This can come from algorithmic improvements and more focus on pretraining dataquality, such as the new open-source DBRX model from Databricks.
Clustering Metrics Clustering is an unsupervised learning technique where data points are grouped into clusters based on their similarities or proximity. Evaluation metrics include: Silhouette Coefficient - Measures the compactness and separation of clusters.
Summary : This comprehensive guide delves into data anomalies, exploring their types, causes, and detection methods. It highlights the implications of anomalies in sectors like finance and healthcare, and offers strategies for effectively addressing them to improve dataquality and decision-making processes.
It is used to classify different data in different classes. Classification is similar to clustering in a way that it also segments data records into different segments called classes. But unlike clustering, here the data analysts would have the knowledge of different classes or cluster.
It shows dataquality and data governance rules and scores by asset to assess the trustworthiness of the data. Data governance of spatial data includes links to detailed maps, reading relative metadata, navigate the spatial data business assets in the impact or lineage view, and taking fast actions.
Here are some of the key advantages of Hadoop in the context of big data: Scalability: Hadoop provides a scalable solution for big data processing. It allows organizations to store and process massive amounts of data across a cluster of commodity hardware. Fault Tolerance: Hadoop is designed to be fault-tolerant.
MLOps facilitates automated testing mechanisms for ML models, which detects problems related to model accuracy, model drift, and dataquality. Data collection and preprocessing The first stage of the ML lifecycle involves the collection and preprocessing of data.
Data engineers play a crucial role in managing and processing big data Ensuring dataquality and integrity Dataquality and integrity are essential for accurate data analysis. Data engineers are responsible for ensuring that the data collected is accurate, consistent, and reliable.
This vault is an entirely new set of tables built off of the raw vault, akin to a separate layer in a data warehouse with “cleaned” data. Information Mart The information mart is the final stage, where the data is optimized for analysis and reporting. Pictured below is an example of a simple PIT table with a cluster key.
If you want an overview of the Machine Learning Process, it can be categorized into 3 wide buckets: Collection of Data: Collection of Relevant data is key for building a Machine learning model. It isn't easy to collect a good amount of qualitydata. You need to know two basic terminologies here, Features and Labels.
The learnings were both practical and provocative; from the necessity for trust, to the power of multi-disciplinary collaboration, to addressing the limitations of data that lead to misinformation and inequality. The Human face of data is part one of a three-part series: Data in the time of COVID-19: What have we learned? __.
Key Takeaways Big Data originates from diverse sources, including IoT and social media. Data lakes and cloud storage provide scalable solutions for large datasets. Processing frameworks like Hadoop enable efficient data analysis across clusters. What is Big Data? How Does Big Data Ensure DataQuality?
Key Takeaways Big Data originates from diverse sources, including IoT and social media. Data lakes and cloud storage provide scalable solutions for large datasets. Processing frameworks like Hadoop enable efficient data analysis across clusters. What is Big Data? How Does Big Data Ensure DataQuality?
It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle. The following code demonstrates how to track your experiments when executing your code on a SageMaker ephemeral cluster using the @remote decorator.
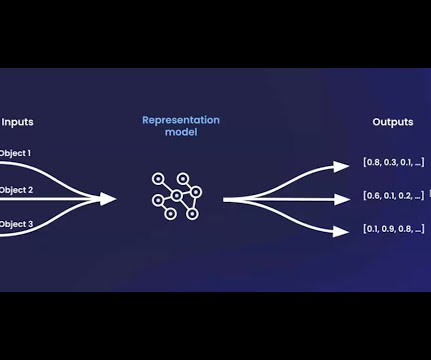
The discussion centered on the importance of dataquality and the role of data augmentation techniques in improving the robustness and effectiveness of representation models. Representation models are a class of machine learning models designed to capture and encode meaningful features from raw data.
Kafka clusters can be automatically scaled based on demand, with full encryption and access control. It includes a built-in schema registry to validate event data from applications as expected, improving dataquality and reducing errors.
Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. This process involves extracting data from multiple sources, transforming it into a consistent format, and loading it into the data warehouse. ETL is vital for ensuring dataquality and integrity.
Summary: Data mining functionalities encompass a wide range of processes, from data cleaning and integration to advanced techniques like classification and clustering. Introduction Data mining is a powerful process that involves analysing large datasets to discover patterns, trends, and useful information.
The discussion centered on the importance of dataquality and the role of data augmentation techniques in improving the robustness and effectiveness of representation models. Representation models are a class of machine learning models designed to capture and encode meaningful features from raw data.
This section explores the essential steps in preparing data for AI applications, emphasising dataquality’s active role in achieving successful AI models. Importance of Data in AI Qualitydata is the lifeblood of AI models, directly influencing their performance and reliability.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content