This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Python for DataScience is crucial for efficiently analysing large datasets. Introduction Python for DataScience has emerged as a pivotal tool in the data-driven world. Key Takeaways Python’s simplicity makes it ideal for DataAnalysis. in 2022, according to the PYPL Index.
What is datascience? Datascience is analyzing and predicting data, It is an emerging field. Some of the applications of datascience are driverless cars, gaming AI, movie recommendations, and shopping recommendations. These data models predict outcomes of new data. Where to start?
Machine learning engineer vs data scientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machine learning engineers and data scientists have gained prominence.
Summary: The DataScience and DataAnalysis life cycles are systematic processes crucial for uncovering insights from raw data. Quality data is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. billion INR by 2026, with a CAGR of 27.7%.
How this machine learning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (clusteranalysis - CA) and classification are two important tasks that occur in our daily lives. Thus, this type of task is very important for exploratorydataanalysis.
DataScience is a popular as well as vast field; till date, there are a lot of opportunities in this field, and most people, whether they are working professionals or students, everyone want a transition in datascience because of its scope. How much to learn? What to do next?
While specific requirements may vary depending on the organization and the role, here are the key skills and educational background that are required for entry-level data scientists — Skillset Mathematical and Statistical Foundation Datascience heavily relies on mathematical and statistical concepts.
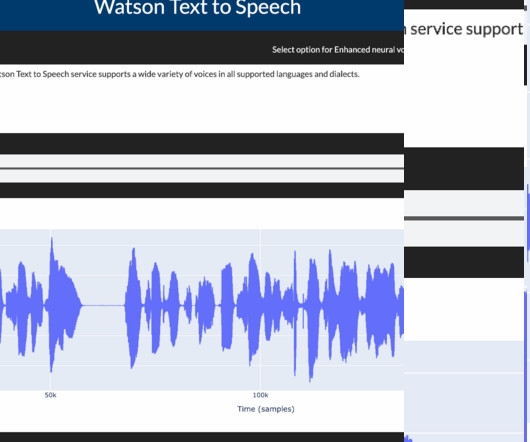
Data Processing and EDA (ExploratoryDataAnalysis) Speech synthesis services require that the data be in a JSON format. Text-to-speech service After the post request, you can save the audio output in your local directory or the cluster. Speech data output 3.
What is R in DataScience? As a programming language it provides objects, operators and functions allowing you to explore, model and visualise data. R allows you to conduct statistical analysis and offers capabilities of statistical and graphical representation. How is R Used in DataScience?
Tableau can help Data Scientists generate graphs, charts, maps and data-driven stories, etc for purpose of visualisation and analysing data. But What is Tableau for DataScience and what are its advantages and disadvantages? How Professionals Can Use Tableau for DataScience? Additionally.
DataScience interviews are pivotal moments in the career trajectory of any aspiring data scientist. Having the knowledge about the datascience interview questions will help you crack the interview. DataScience skills that will help you excel professionally.
ML is a computer science, datascience and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
With technological developments occurring rapidly within the world, Computer Science and DataScience are increasingly becoming the most demanding career choices. Moreover, with the oozing opportunities in DataScience job roles, transitioning your career from Computer Science to DataScience can be quite interesting.
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
Use DataRobot’s AutoML and AutoTS to tackle various datascience problems such as classification, forecasting, and regression. Not sure where to start with your massive trove of text data? Take advantage of DataRobot’s wide range of options for experimentation.
And importantly, starting naively annotating data might become a quick solution rather than thinking about how to make uses of limited labels if extracting data itself is easy and does not cost so much. In this case, original data distribution have two clusters of circles and triangles and a clear border can be drawn between them.
Together, data engineers, data scientists, and machine learning engineers form a cohesive team that drives innovation and success in data analytics and artificial intelligence. Their collective efforts are indispensable for organizations seeking to harness data’s full potential and achieve business growth.
These libraries, with their rich functionalities and comprehensive toolsets, have become the backbone of datascience and machine learning practices. These packages are built to handle various aspects of machine learning, including tasks such as classification, regression, clustering, dimensionality reduction, and more.
Data Collection: Based on the question or problem identified, you need to collect data that represents the problem that you are studying. ExploratoryDataAnalysis: You need to examine the data for understanding the distribution, patterns, outliers and relationships between variables.
This challenge asked participants to gather their own data on their favorite DeFi protocol. From there, participants were asked to conduct exploratorydataanalysis, explore recommendations to the protocol, and dive into key metrics and user retention rates that correlate and precede the success of a given protocol.
Many companies are now utilizing datascience and machine learning , but there’s still a lot of room for improvement in terms of ROI. The process begins with a careful observation of customer data and an assessment of whether there are naturally formed clusters in the data. billion in 2022, an increase of 21.3%
Machine Learning Machine Learning is a critical component of modern DataAnalysis, and Python has a robust set of libraries to support this: Scikit-learn This library helps execute Machine Learning models, automating the process of generating insights from large volumes of data.
F1 :: 2024 Strategy Analysis Poster ‘The Formula 1 Racing Challenge’ challenges participants to analyze race strategies during the 2024 season. They will work with lap-by-lap data to assess how pit stop timing, tire selection, and stint management influence race performance.
How to become a data scientist Data transformation also plays a crucial role in dealing with varying scales of features, enabling algorithms to treat each feature equally during analysis Noise reduction As part of data preprocessing, reducing noise is vital for enhancing data quality.
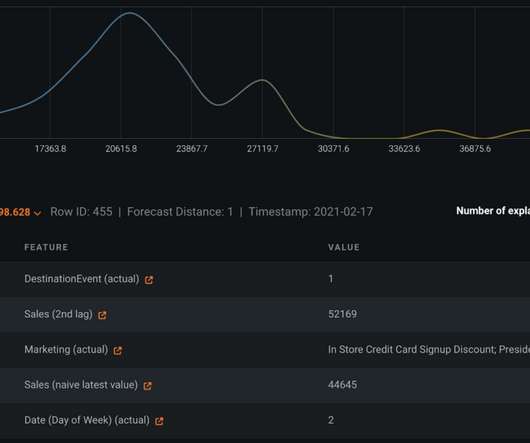
However, tedious and redundant tasks in exploratorydataanalysis, model development, and model deployment can stretch the time to value of your machine learning projects. Flexible BigQuery Data Ingestion to Fuel Time Series Forecasting. Enable Granular Forecasts with Clustering. This is where clustering comes in.
ExploratoryDataAnalysis (EDA) ExploratoryDataAnalysis (EDA) is an approach to analyse datasets to uncover patterns, anomalies, or relationships. The primary purpose of EDA is to explore the data without any preconceived notions or hypotheses.
Plotly allows developers to embed interactive features such as zooming, panning, and hover effects directly into the plots, making it ideal for ExploratoryDataAnalysis and dynamic reports. The library supports various chart types, from simple line graphs to complex 3D plots, making it versatile for any Data Visualisation task.
I would perform exploratorydataanalysis to understand the distribution of customer transactions and identify potential segments. Then, I would use clustering techniques such as k-means or hierarchical clustering to group customers based on similarities in their purchasing behaviour. What approach would you take?
As a data scientist at Cars4U, I had to come up with a pricing model that can effectively predict the price of used cars and can help the business in devising profitable strategies using differential pricing. In this analysis, I: provided summary statistics and exploratorydataanalysis of the data.
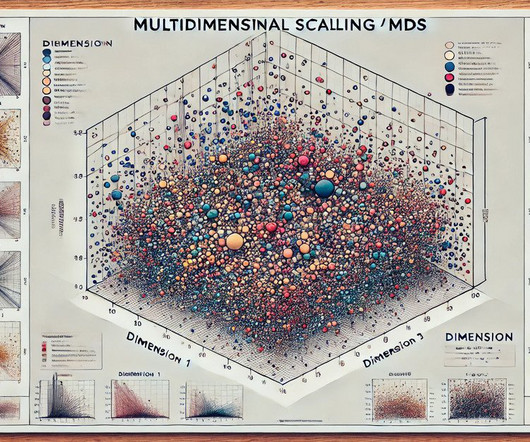
This step translates the high-dimensional data into a more manageable format. This representation reveals clusters, patterns, and relationships among the objects, enabling insights that might not be apparent in high-dimensional data.
In a typical MLOps project, similar scheduling is essential to handle new data and track model performance continuously. Load and Explore Data We load the Telco Customer Churn dataset and perform exploratorydataanalysis (EDA). Are there clusters of customers with different spending patterns? #3.
Top 15 Data Analytics Projects in 2023 for Beginners to Experienced Levels: Data Analytics Projects allow aspirants in the field to display their proficiency to employers and acquire job roles. Kaggle datasets) and use Python’s Pandas library to perform data cleaning, data wrangling, and exploratorydataanalysis (EDA).
Data visualization is an indispensable aspect of any datascience project, playing a pivotal role in gaining insights and communicating findings effectively. What is data visualization? Why do we choose Python data visualization tools for our projects? Are there many different types of data visualization methods?
Solvers submitted a wide range of methodologies to this end, including using open-source and third party LLMs (GPT, LLaMA), clustering (DBSCAN, K-Means), dimensionality reduction (PCA), topic modeling (LDA, BERT), sentence transformers, semantic search, named entity recognition, and more. and DistilBERT.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content