This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon Introduction Analyzing texts is far more complicated than analyzing typical tabulated data (e.g. retail data) because texts fall under unstructured data. Different people express themselves quite differently when it comes to […].
In the modern digital era, this particular area has evolved to give rise to a discipline known as DataScience. DataScience offers a comprehensive and systematic approach to extracting actionable insights from complex and unstructured data.
Read a comprehensive SQL guide for data analysis; Learn how to choose the right clustering algorithm for your data; Find out how to create a viral DataViz using the data from DataScience Skills poll; Enroll in any of 10 Free Top Notch NaturalLanguageProcessing Courses; and more.
Wie sich mit DataScience die Profitabilität des Kreditkartengeschäfts einer Bank nachhaltig steigern lässt. Das Vorgehen Um die verschiedenen Kundengruppen zu identifizieren, sollten die Kund:innen mithilfe einer Clustering-Analyse in klar voneinander abgegrenzte Segmente eingeteilt werden.
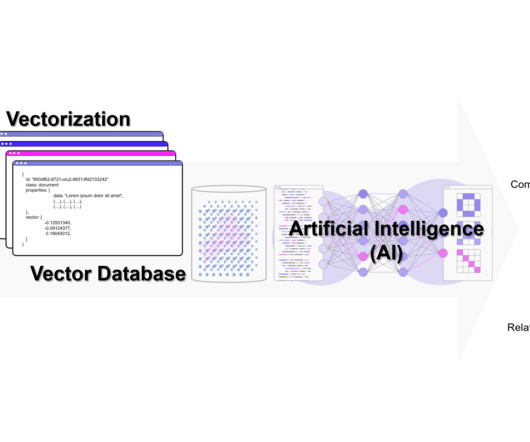
Moreover, organized storage of data facilitates data analysis, enabling retrieval of useful insights and data patterns. It also facilitates integration with different applications to enhance their functionality with organized access to data. A file records vectors that belong to each cluster.
In this blog post, we’ll explore five project ideas that can help you build expertise in computer vision, naturallanguageprocessing (NLP), sales forecasting, cancer detection, and predictive maintenance using Python. A project idea in this area could be to create a sales forecasting model using Python and Pandas.
What is datascience? Datascience is analyzing and predicting data, It is an emerging field. Some of the applications of datascience are driverless cars, gaming AI, movie recommendations, and shopping recommendations. These data models predict outcomes of new data. Where to start?
Industry Adoption: Widespread Implementation: AI and datascience are being adopted across various industries, including healthcare, finance, retail, and manufacturing, driving increased demand for skilled professionals. This is used for tasks like clustering, dimensionality reduction, and anomaly detection.
Datascience bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of datascience. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
Data scientists are continuously advancing with AI tools and technologies to enhance their capabilities and drive innovation in 2024. The integration of AI into datascience has revolutionized the way data is analyzed, interpreted, and utilized. – Example: Data scientists can employ H2O.ai
This post is a bitesize walk-through of the 2021 Executive Guide to DataScience and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Team Building the right datascience team is complex. Download the free, unabridged version here.
der k-Nächste-Nachbarn -Prädiktionsalgorithmus (Regression/Klassifikation) oder K-Means-Clustering. Die Texte müssen in diese transformiert werden, eventuell auch nach diesen in Cluster eingeteilt und für verschiedene Trainingsszenarien separiert werden. appeared first on DataScience Blog.
Looking back ¶ When we started DrivenData in 2014, the application of datascience for social good was in its infancy. There was rapidly growing demand for datascience skills at companies like Netflix and Amazon. Weve run 75+ datascience competitions awarding more than $4.7
The data is obtained from the Internet via APIs and web scraping, and the job titles and the skills listed in them are identified and extracted from them using NaturalLanguageProcessing (NLP) or more specific from Named-Entity Recognition (NER).
Well, it’s NaturalLanguageProcessing which equips the machines to work like a human. But there is much more to NLP, and in this blog, we are going to dig deeper into the key aspects of NLP, the benefits of NLP and NaturalLanguageProcessing examples. What is NLP? However, the road is not so smooth.
As a global leader in agriculture, Syngenta has led the charge in using datascience and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. His primary focus lies in using the full potential of data, algorithms, and cloud technologies to drive innovation and efficiency.
BERT (Bidirectional Encoder Representations from Transformers) BERT is a revolutionary transformer-based model that underwent extensive pre-training on vast amounts of text data. Its prowess lies in naturallanguageprocessing (NLP) tasks like sentiment analysis, question-answering, and text classification.
Imagine asking a question in plain English and instantly getting a detailed report or a visual representation of your data—this is what GenAI can do. It’s not just for tech experts anymore; GenAI democratizes datascience, allowing anyone to extract insights from data easily.
Naturallanguageprocessing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader datascience expertise.
Hence, acting as a translator it converts human language into a machine-readable form. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings. Their impact on ML tasks has made them a cornerstone of AI advancements.
Faiss is a library for efficient similarity search and clustering of dense vectors. They are used in a variety of AI applications, such as image search, naturallanguageprocessing, and recommender systems. Vector embeddings are a powerful tool for representing and manipulating data.
Exploring Disease Mechanisms : Vector databases facilitate the identification of patient clusters that share similar disease progression patterns. Here are a few key components of the discussed process described below: Feature engineering : Transforming raw clinical data into meaningful numerical representations suitable for vector space.
To achieve this, Lumi developed a classification model based on BERT (Bidirectional Encoder Representations from Transformers) , a state-of-the-art naturallanguageprocessing (NLP) technique. They fine-tuned this model using their proprietary dataset and in-house datascience expertise. Follow her on LinkedIn.
Transformers are a type of neural network that are well-suited for naturallanguageprocessing tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language. They are typically trained on clusters of computers or even on cloud computing platforms.
Being an important component of DataScience, the use of statistical methods are crucial in training algorithms in order to make classification. Certainly, these predictions and classification help in uncovering valuable insights in data mining projects. It can also be used for determining the optimal number of clusters.
It is an AI framework and a type of naturallanguageprocessing (NLP) model that enables the retrieval of information from an external knowledge base. Facebook AI similarity search (FAISS) FAISS is used for similarity search and clustering dense vectors. Let’s take a deeper look into understanding RAG.
How this machine learning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (cluster analysis - CA) and classification are two important tasks that occur in our daily lives. 3 feature visual representation of a K-means Algorithm.
TensorFlow First on the AI tool list, we have TensorFlow which is an open-source software library for numerical computation using data flow graphs. It is used for machine learning, naturallanguageprocessing, and computer vision tasks. For example, Scikit-learn was used by Spotify to improve its recommendation engine.
There are several techniques used in intelligent data classification, including: Machine learning : Machine learning algorithms can be trained on large datasets to recognize patterns and categories within the data. Clustering algorithms work by assigning data points to clusters based on their similarity.
With IBM Watson NLP, IBM introduced a common library for naturallanguageprocessing, document understanding, translation, and trust. This tutorial walks you through the steps to serve pretrained Watson NLP models using Knative Serving in a Red Hat OpenShift cluster. For more information see [link].
While specific requirements may vary depending on the organization and the role, here are the key skills and educational background that are required for entry-level data scientists — Skillset Mathematical and Statistical Foundation Datascience heavily relies on mathematical and statistical concepts.
Summary: DataScience and AI are transforming the future by enabling smarter decision-making, automating processes, and uncovering valuable insights from vast datasets. Bureau of Labor Statistics predicts that employment for Data Scientists will grow by 36% from 2021 to 2031 , making it one of the fastest-growing professions.
What is R in DataScience? R is an open-source programming language that you can use for free and is compatible with different operating systems and platforms. As a programming language it provides objects, operators and functions allowing you to explore, model and visualise data. How is R Used in DataScience?
Hence, acting as a translator it converts human language into a machine-readable form. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings. Their impact on ML tasks has made them a cornerstone of AI advancements.
Summary: In 2024, mastering essential DataScience tools will be pivotal for career growth and problem-solving prowess. offer the best online DataScience courses tailored for beginners and professionals, focusing on practical learning and industry relevance. Why learn tools of DataScience? Join Pickl.AI
Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step. Amazon Redshift Serverless cluster. Just load your data and start querying. There is no need to set up and manage clusters. Loading data in Amazon Redshift Serverless. 1 Public subnet. 1 NAT gateway. Internet gateway.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and DataScience, highlighting their complementary roles in Data Analysis and intelligent decision-making. Introduction Artificial Intelligence (AI) and DataScience are revolutionising how we analyse data, make decisions, and solve complex problems.
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
With the expanding field of DataScience, the need for efficient and skilled professionals is increasing. You need to be highly proficient in programming languages to help businesses solve problems. Python is one of the widely used programming languages in the world having its own significance and benefits.
ML is a computer science, datascience and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
DataScience helps businesses uncover valuable insights and make informed decisions. But for it to be functional, programming languages play an integral role. Programming for DataScience enables Data Scientists to analyze vast amounts of data and extract meaningful information.
To learn more about how NYUTron was developed along with the limitations and possibilities of AI support tools for healthcare providers, CDS spoke with Lavender Jiang , PhD student at the NYU Center for DataScience and lead author of the study. Read our Q&A with Lavender below! The resources NYU has are unique and valuable.
By using the Livy REST APIs , SageMaker Studio users can also extend their interactive analytics workflows beyond just notebook-based scenarios, enabling a more comprehensive and streamlined datascience experience within the Amazon SageMaker ecosystem. This same interface is also used for provisioning EMR clusters.
In our test environment, we observed 20% throughput improvement and 30% latency reduction across multiple naturallanguageprocessing models. So far, we have migrated PyTorch and TensorFlow based Distil RoBerta-base, spaCy clustering, prophet, and xlmr models to Graviton3-based c7g instances.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content