This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In contemporary times, datascience has emerged as a substantial and progressively expanding domain that has an impact on virtually every sphere of human ingenuity: be it commerce, technology, healthcare, education, governance, and beyond. This piece will concentrate on the elemental constituents constituting datascience.
Top statistical techniques – DataScience Dojo Counterfactual causal inference: Counterfactual causal inference is a statistical technique that is used to evaluate the causal significance of historical events. This technique is often used in cases where the data is contaminated with errors or outliers.
Python is a powerful and versatile programming language that has become increasingly popular in the field of datascience. One of the main reasons for its popularity is the vast array of libraries and packages available for data manipulation, analysis, and visualization.
Learn how to apply state-of-the-art clustering algorithms efficiently and boost your machine-learning skills.Image source: unsplash.com. This is called clustering. In DataScience, clustering is used to group similar instances together, discovering patterns, hidden structures, and fundamental relationships within a dataset.
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) datascience. This week, we continue that metaphorical (learning) journey with a fun fact. Better yet, a riddle. IoT, Web 3.0,
Common Classification Algorithms: Logistic Regression: A popular choice for binary classification, it uses a mathematical function to model the probability of a data point belonging to a particular class. Decision Trees: These work by asking a series of yes/no questions based on data features to classify data points.
Python is a powerful and versatile programming language that has become increasingly popular in the field of datascience. One of the main reasons for its popularity is the vast array of libraries and packages available for data manipulation, analysis, and visualization.
Being an important component of DataScience, the use of statistical methods are crucial in training algorithms in order to make classification. Certainly, these predictions and classification help in uncovering valuable insights in data mining projects. Hyperplanes are useful in separating the data points into groups.
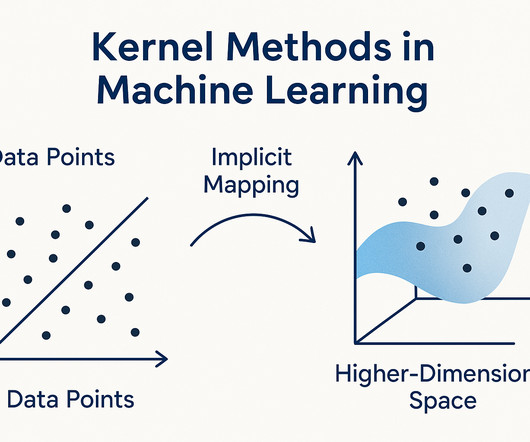
Learn how they work and how to apply them in real-world projects through Pickl.AIs datascience courses. Introduction Machine learning often struggles when the data isnt in a straight lineliterally! This is where kernel methods in machine learning come in like superheroes.
SmartCore SmartCore is a machine learning library written in Rust that provides a variety of algorithms for regression, classification, clustering, and more. The library encompasses both conventional and advanced machine learning techniques, including linear regression, k-means clustering, random forests, and supportvectormachines.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? By leveraging anomaly detection, we can uncover hidden irregularities in transaction data that may indicate fraudulent behavior.
Comparison with Other Classification Techniques Associative classification differs from traditional classification methods like decision trees and supportvectormachines (SVM). Understanding these differences can help determine when to use each technique based on the nature of the data and the problem at hand.
DataScience interviews are pivotal moments in the career trajectory of any aspiring data scientist. Having the knowledge about the datascience interview questions will help you crack the interview. DataScience skills that will help you excel professionally.
In data mining, popular algorithms include decision trees, supportvectormachines, and k-means clustering. This is similar as you consider many factors while you pay someone for essay , which may include referencing, evidence-based argument, cohesiveness, etc.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and DataScience, highlighting their complementary roles in Data Analysis and intelligent decision-making. Introduction Artificial Intelligence (AI) and DataScience are revolutionising how we analyse data, make decisions, and solve complex problems.
What is machine learning? ML is a computer science, datascience and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. Here, we’ll discuss the five major types and their applications.
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
With the expanding field of DataScience, the need for efficient and skilled professionals is increasing. Its efficacy may allow kids from a young age to learn Python and explore the field of DataScience. Its efficacy may allow kids from a young age to learn Python and explore the field of DataScience.
Hey guys, in this blog we will see some of the most asked DataScience Interview Questions by interviewers in [year]. Datascience has become an integral part of many industries, and as a result, the demand for skilled data scientists is soaring. What is DataScience?
The feature space reduction is performed by aggregating clusters of features of balanced size. This clustering is usually performed using hierarchical clustering. The idea is to sort the labels into clusters to create a meta-label space.
Common Machine Learning Algorithms Machine learning algorithms are not limited to those mentioned below, but these are a few which are very common. Linear Regression Decision Trees SupportVectorMachines Neural Networks Clustering Algorithms (e.g.,
Anomalies are not inherently bad, but being aware of them, and having data to put them in context, is integral to understanding and protecting your business. The challenge for IT departments working in datascience is making sense of expanding and ever-changing data points.
Examples of supervised learning models include linear regression, decision trees, supportvectormachines, and neural networks. Common examples include: Linear Regression: It is the best Machine Learning model and is used for predicting continuous numerical values based on input features.
The surge of digitization and its growing penetration across the industry spectrum has increased the relevance of text mining in DataScience. Text mining is primarily a technique in the field of DataScience that encompasses the extraction of meaningful insights and information from unstructured textual data.
SVM-based classifier: Amazon Titan Embeddings In this scenario, it is likely that user interactions belonging to the three main categories ( Conversation , Services , and Document_Translation ) form distinct clusters or groups within the embedding space. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
The datascience job market is rapidly evolving, reflecting shifts in technology and business needs. Heres what we noticed from analyzing this data, highlighting whats remained the same over the years, and what additions help make the modern data scientist in2025. Joking aside, this does infer particular skills.
Scikit-learn: Scikit-learn is an open-source library that provides a range of tools for building and training machine learning models, including classification, regression, and clustering. R: R is a programming language that is widely used in datascience and AI development.
Bioinformatics: A Haven for Data Scientists and Machine Learning Engineers: Bioinformatics offers an unparalleled opportunity for data scientists and machine learning engineers to apply their expertise in solving complex biological problems.
Statistical methods, machine learning algorithms, and data mining techniques are employed to extract meaningful insights from the collected data. This analysis may involve feature engineering, dimensionality reduction, clustering, classification, regression, or other statistical modeling approaches.
left: neutral pose — do nothing | right: fist — close gripper | Photos from myo-readings-dataset left: extension — move forward | right: flexion — move backward | Photos from myo-readings-dataset This project uses the scikit-learn implementation of a SupportVectorMachine (SVM) trained for gesture recognition.
Applications : Stock price prediction and financial forecasting Analysing sales trends over time Demand forecasting in supply chain management Clustering Models Clustering is an unsupervised learning technique used to group similar data points together. Popular clustering algorithms include k-means and hierarchical clustering.
Decision Trees These trees split data into branches based on feature values, providing clear decision rules. SupportVectorMachines (SVM) SVMs are powerful classifiers that separate data into distinct categories by finding an optimal hyperplane. They are handy for high-dimensional data.
Big Data Technologies and Tools A comprehensive syllabus should introduce students to the key technologies and tools used in Big Data analytics. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content