This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Clustering algorithms play a vital role in the landscape of machine learning, providing powerful techniques for grouping various data points based on their intrinsic characteristics. Their effectiveness in working with unstructured data opens up a myriad of applications ranging from market segmentation to social media analysis.
Datascientists are continuously advancing with AI tools and technologies to enhance their capabilities and drive innovation in 2024. The integration of AI into data science has revolutionized the way data is analyzed, interpreted, and utilized. Have you used voice assistants like Siri or Alexa?
If you’ve found yourself asking, “How to become a datascientist?” In this detailed guide, we’re going to navigate the exciting realm of data science, a field that blends statistics, technology, and strategic thinking into a powerhouse of innovation and insights. What is a datascientist?
Standards and expectations are rapidly changing, especially in regards to the types of technology used to create data science projects. Most datascientists are using some form of DevOps interface these days. There are a lot of important nuances for datascientists using Kubernetes. Why Serverless in Kubernetes?
Machine learning engineer vs datascientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machine learning engineers and datascientists have gained prominence.
Python has become a popular programming language in the data science community due to its simplicity, flexibility, and wide range of libraries and tools. Work on projects Apply your knowledge by working on real-world data science projects.
Savvy datascientists are already applying artificial intelligence and machine learning to accelerate the scope and scale of data-driven decisions in strategic organizations. Datascientists are in demand: the U.S. Explore these 10 popular blogs that help datascientists drive better data decisions.
Learn about 33 tools to visualize data with this blog In this blog post, we will delve into some of the most important plots and concepts that are indispensable for any datascientist. 9 Data Science Plots – Data Science Dojo 1. Suppose you are a datascientist working for an e-commerce company.
Learn how to apply state-of-the-art clustering algorithms efficiently and boost your machine-learning skills.Image source: unsplash.com. This is called clustering. In Data Science, clustering is used to group similar instances together, discovering patterns, hidden structures, and fundamental relationships within a dataset.
One of the main reasons for its popularity is the vast array of libraries and packages available for data manipulation, analysis, and visualization. It supports large, multi-dimensional arrays and matrices of numerical data, as well as a large library of mathematical functions to operate on these arrays.
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing datascientists and ML engineers to build, train, and deploy ML models using geospatial data. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster.
It allows datascientists and machine learning engineers to interact with their data and models and to visualize and share their work with others with just a few clicks. SageMaker Canvas has also integrated with Data Wrangler , which helps with creating data flows and preparing and analyzing your data.
Unfortunately, you can’t have a friendly conversation with the data, but don’t worry, we have the next best solution. Cluster Sampling: The population is divided into clusters, and a random sample of clusters is selected, with all members in selected clusters included.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
t-SNE (t-distributed stochastic neighbor embedding) has become an essential tool in the realm of data analytics, standing out for its ability to unravel the complexities inherent in high-dimensional data. This enables researchers to identify clusters and similarities among the data points more intuitively.
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
It also facilitates integration with different applications to enhance their functionality with organized access to data. In data science, databases are important for data preprocessing, cleaning, and integration. Datascientists often rely on databases to perform complex queries and visualize data.
SageMaker HyperPod recipes help datascientists and developers of all skill sets to get started training and fine-tuning popular publicly available generative AI models in minutes with state-of-the-art training performance. The launcher will interface with your cluster with Slurm or Kubernetes native constructs.
DataRobot Core for Expert DataScientists: Build Fast and Deliver at Scale with a Code-First Experience. Launched today, DataRobot Core is a comprehensive offering aimed at giving datascientists the purpose-built technologies they need to deliver powerful AI solutions for their organizations quickly, with a code-first experience.
For datascientists, ML chips utilization and saturation are also relevant for capacity planning. The pattern is part of the AWS CDK Observability Accelerator , a set of opinionated modules to help you set observability for Amazon EKS clusters. Solution overview The following diagram illustrates the solution architecture.
Solve Your MLOps Problems with an Open Source Data Science Stack These are 10 common problems datascientists face in regard to MLOps alongside some open-source solutions to address them. Don’t miss our upcoming Data Primer live virtual training. But how do you go from a churn model to churn prevention? Learn more here.
Statistics: Unveiling the patterns within data Statistics serves as the bedrock of data science, providing the tools and techniques to collect, analyze, and interpret data. It equips datascientists with the means to uncover patterns, trends, and relationships hidden within complex datasets.
We have seen how Machine learning has revolutionized industries across the globe during the past decade, and Python has emerged as the language of choice for aspiring datascientists and seasoned professionals alike. Upgrade to access all of Medium. Scikit-learn is an open-source machine learning library built on Python.
Compensation at DeepSeek and High-Flyer is reportedly generous; senior datascientists at High-Flyer can earn up to 1.5 The firm allocated 70% of its revenue towards AI research, building two supercomputing AI clusters, including one consisting of 10,000 Nvidia A100 chips during 2020 and 2021.
Visualization for Clustering Methods Clustering methods are a big part of data science, and here’s a primer on how you can visualize them. Professor Mark A. Lemley on Generative AI and the Law Here’s what Mark A.
This also led to a backlog of data that needed to be ingested. Steep learning curve for datascientists: Many of Rockets datascientists did not have experience with Spark, which had a more nuanced programming model compared to other popular ML solutions like scikit-learn.
It allows datascientists to build models that can automate specific tasks. It provides a large cluster of clusters on a single machine. Spark is a general-purpose distributed data processing engine that can handle large volumes of data for applications like data analysis, fraud detection, and machine learning.
One of the main reasons for its popularity is the vast array of libraries and packages available for data manipulation, analysis, and visualization. It supports large, multi-dimensional arrays and matrices of numerical data, as well as a large library of mathematical functions to operate on these arrays.
Summary: The Gaussian Mixture Model (GMM) is a flexible probabilistic model that represents data as a mixture of multiple Gaussian distributions. It excels in soft clustering, handling overlapping clusters, and modelling diverse cluster shapes. EM algorithm iteratively optimizes GMM parameters for best data fit.
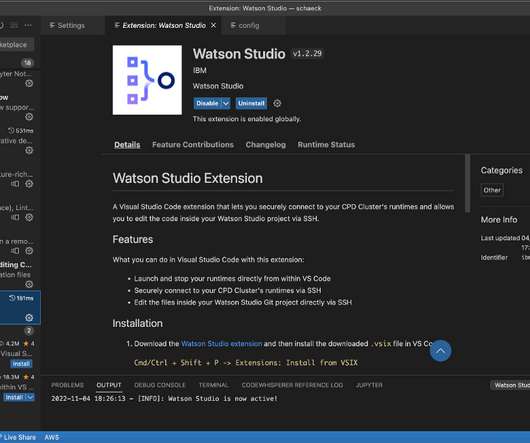
This article gives an overview of the code experience for datascientists in Watson Studio on Cloud Pak for Data 4.6. VS Code desktop integration lets datascientists use a familiar IDE to run and debug code that runs on the Cloud Pak for Datacluster. Users can work in the familiar VS Code IDE.
Skills required for data science It is a multi-faceted field that necessitates a range of competencies in statistics, programming, and data visualization. Proficiency in statistical analysis is essential for DataScientists to detect patterns and trends in data.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. It utilises the Hadoop Distributed File System (HDFS) and MapReduce for efficient data management, enabling organisations to perform big data analytics and gain valuable insights from their data.
Summary: Hierarchical clustering categorises data by similarity into hierarchical structures, aiding in pattern recognition and anomaly detection across various fields. It uses dendrograms to visually represent data relationships, offering intuitive insights despite challenges like scalability and sensitivity to outliers.
This blog lists down-trending data science, analytics, and engineering GitHub repositories that can help you with learning data science to build your own portfolio. What is GitHub? GitHub is a powerful platform for datascientists, data analysts, data engineers, Python and R developers, and more.
Statistical analysis and hypothesis testing Statistical methods provide powerful tools for understanding data. An Applied DataScientist must have a solid understanding of statistics to interpret data correctly. Machine learning algorithms Machine learning forms the core of Applied Data Science.
Launching a machine learning (ML) training cluster with Amazon SageMaker training jobs is a seamless process that begins with a straightforward API call, AWS Command Line Interface (AWS CLI) command, or AWS SDK interaction. The training data, securely stored in Amazon Simple Storage Service (Amazon S3), is copied to the cluster.
Clustering. ?lustering lustering is an approach where several data points are clustered according to the similarity between them, so they are easier to interpret and manage. ?lustering There are a number of ready-made BI solutions that allow you to group data. Let’s dig deeper. Predictive analytics.
Some of the applications of data science are driverless cars, gaming AI, movie recommendations, and shopping recommendations. Since the field covers such a vast array of services, datascientists can find a ton of great opportunities in their field. Datascientists use algorithms for creating data models.
Seamless integration with SageMaker – As a built-in feature of the SageMaker platform, the EMR Serverless integration provides a unified and intuitive experience for datascientists and engineers. By unlocking the potential of your data, this powerful integration drives tangible business results.
Hadoop systems and data lakes are frequently mentioned together. Data is loaded into the Hadoop Distributed File System (HDFS) and stored on the many computer nodes of a Hadoop cluster in deployments based on the distributed processing architecture. To preserve your digital assets, data must lastly be secured.
Orchestrate with Tecton-managed EMR clusters – After features are deployed, Tecton automatically creates the scheduling, provisioning, and orchestration needed for pipelines that can run on Amazon EMR compute engines. You can view and create EMR clusters directly through the SageMaker notebook.
One study found that 44% of companies that hire datascientists say the departments are seriously understaffed. Fortunately, datascientists can make due with fewer staff if they use their resources more efficiently, which involves leveraging the right tools. With OLAP, finding clusters and anomalies is simple.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








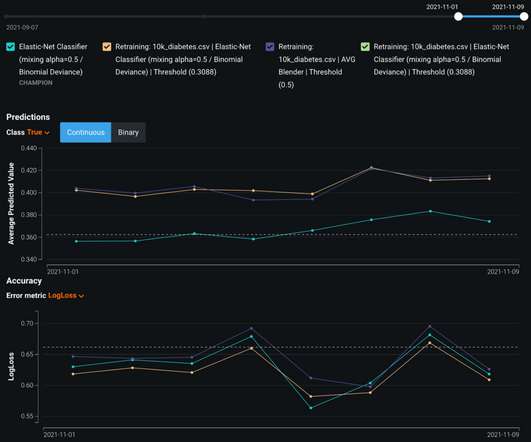













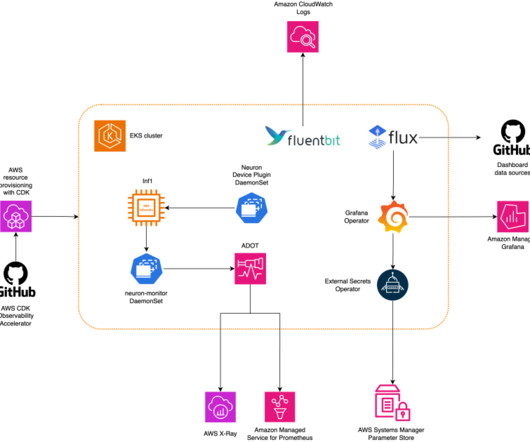
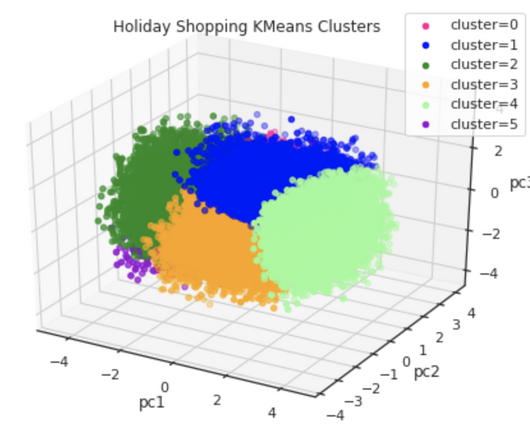























Let's personalize your content