This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Its robust ecosystem of libraries and frameworks tailored for Data Science, such as NumPy, Pandas, and Scikit-learn, contributes significantly to its popularity. Moreover, Python’s straightforward syntax allows DataScientists to focus on problem-solving rather than grappling with complex code.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Role of DataScientistsDataScientists are the architects of data analysis.
Answering one of the most common questions I get asked as a Senior DataScientist — What skills and educational background are necessary to become a datascientist? Photo by Eunice Lituañas on Unsplash To become a datascientist, a combination of technical skills and educational background is typically required.
It combines elements of statistics, mathematics, computer science, and domain expertise to extract meaningful patterns from large volumes of data. Role of DataScientists in Modern Industries DataScientists drive innovation and competitiveness across industries in today’s fast-paced digital world.
Data preprocessing ensures the removal of incorrect, incomplete, and inaccurate data from datasets, leading to the creation of accurate and useful datasets for analysis ( Image Credit ) Data completeness One of the primary requirements for data preprocessing is ensuring that the dataset is complete, with minimal missing values.
They will work with lap-by-lap data to assess how pit stop timing, tire selection, and stint management influence race performance. By conducting exploratory data analysis (EDA), they will identify relationships between these variables and generate insights on how strategy impacts race outcomes.
Exploratory Data Analysis (EDA) Exploratory Data Analysis (EDA) is an approach to analyse datasets to uncover patterns, anomalies, or relationships. The primary purpose of EDA is to explore the data without any preconceived notions or hypotheses.
Exploratory Data Analysis (EDA) EDA is a crucial preliminary step in understanding the characteristics of the dataset. Techniques such as statistical summaries, data visualisation, and correlation analysis help uncover patterns, anomalies, and relationships within the data.
Data Science projects require you perform different projects and track changes in your project using a version code. If you want to become an efficient DataScientist and grab that job role you’ve been looking for, you need to work on Github for Data Science projects.
To address this challenge, datascientists harness the power of machine learning to predict customer churn and develop strategies for customer retention. Continuous Experiment Tracking with Comet ML Comet ML is a versatile tool that helps datascientists optimize machine learning experiments.
Note : Now, Start joining Data Science communities on social media platforms. These communities will help you to be updated in the field, because there are some experienced datascientists posting the stuff, or you can talk with them so they will also guide you in your journey.
As a datascientist at Cars4U, I had to come up with a pricing model that can effectively predict the price of used cars and can help the business in devising profitable strategies using differential pricing. Bivariate EDA Contrary to intuition, Kilometers_Driven does not seem to have a relationship with the price.
Data Science interviews are pivotal moments in the career trajectory of any aspiring datascientist. Having the knowledge about the data science interview questions will help you crack the interview. Clustering algorithms such as K-means and hierarchical clustering are examples of unsupervised learning techniques.
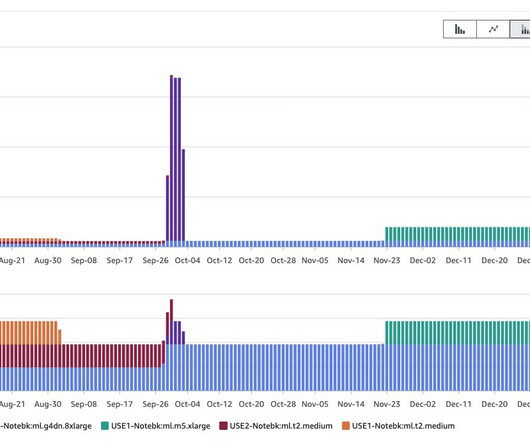
For ML model development, the size of a SageMaker notebook instance depends on the amount of data you need to load in-memory for meaningful exploratory data analyses (EDA) and the amount of computation required. We recommend starting small with general-purpose instances (such as T or M families) and scaling up as needed.
Data Science is the art and science of extracting valuable information from data. It encompasses data collection, cleaning, analysis, and interpretation to uncover patterns, trends, and insights that can drive decision-making and innovation.
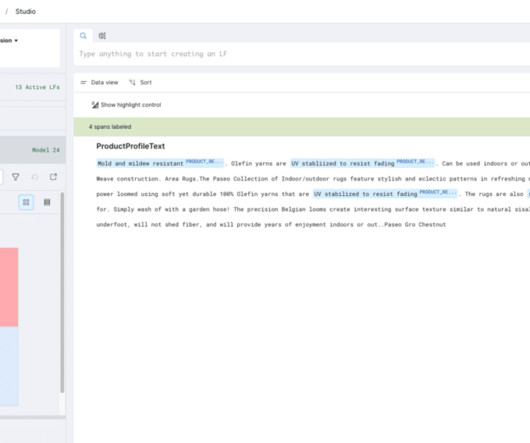
From there, we used Snorkel Flow to help identify and correct the model’s error modes in a data-centric development process. We corrected these via prompt where possible and then later via additional labeled data for fine-tuning. Built-in tools for EDA (filtering, sorting, clustering, tagging, etc.)
Then they use these patterns to understand the public’s behavior and predict the election results, thus making more informed political strategies based on population clusters. Now you need to perform some EDA and cleaning on the data after loading it into the notebook. We pay our contributors, and we don’t sell ads.
Solvers submitted a wide range of methodologies to this end, including using open-source and third party LLMs (GPT, LLaMA), clustering (DBSCAN, K-Means), dimensionality reduction (PCA), topic modeling (LDA, BERT), sentence transformers, semantic search, named entity recognition, and more. and DistilBERT. What motivated you to participate? :
Datascientists frame the business problem and the objective into a statistical solution and start with the very first step of data exploration. EDA, as it is popularly called, is the pivotal phase of the project where discoveries are made. Approvals from stakeholders ML projects are inherently iterative by nature.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content