This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datascientists are continuously advancing with AI tools and technologies to enhance their capabilities and drive innovation in 2024. The integration of AI into data science has revolutionized the way data is analyzed, interpreted, and utilized. Have you used voice assistants like Siri or Alexa?
It also facilitates integration with different applications to enhance their functionality with organized access to data. In data science, databases are important for data preprocessing, cleaning, and integration. Datascientists often rely on databases to perform complex queries and visualize data.
t-SNE (t-distributed stochastic neighbor embedding) has become an essential tool in the realm of data analytics, standing out for its ability to unravel the complexities inherent in high-dimensional data. This enables researchers to identify clusters and similarities among the data points more intuitively.
The data is obtained from the Internet via APIs and web scraping, and the job titles and the skills listed in them are identified and extracted from them using NaturalLanguageProcessing (NLP) or more specific from Named-Entity Recognition (NER).
The agent uses naturallanguageprocessing (NLP) to understand the query and uses underlying agronomy models to recommend optimal seed choices tailored to specific field conditions and agronomic needs. What corn hybrids do you suggest for my field?”.
Statistical analysis and hypothesis testing Statistical methods provide powerful tools for understanding data. An Applied DataScientist must have a solid understanding of statistics to interpret data correctly. Machine learning algorithms Machine learning forms the core of Applied Data Science.
Some of the applications of data science are driverless cars, gaming AI, movie recommendations, and shopping recommendations. Since the field covers such a vast array of services, datascientists can find a ton of great opportunities in their field. Datascientists use algorithms for creating data models.
These methods analyze data without pre-labeled outcomes, focusing on discovering patterns and relationships. They often play a crucial role in clustering and segmenting data, helping businesses identify trends without prior knowledge of the outcome. Well-prepared data is essential for developing robust predictive models.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. It can also be used for determining the optimal number of clusters.
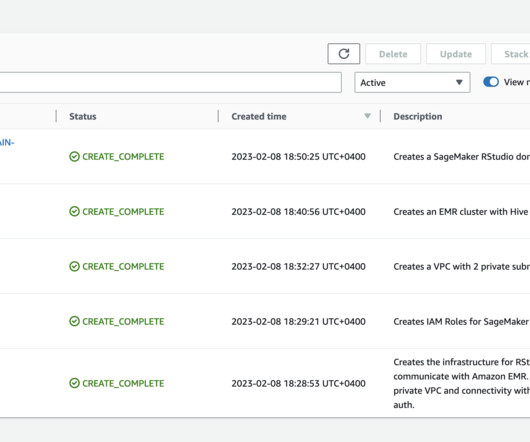
In this blog post, we will show you how to use both of these services together to efficiently perform analysis on massive data sets in the cloud while addressing the challenges mentioned above. Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step. Amazon Redshift Serverless cluster.
Seamless integration with SageMaker – As a built-in feature of the SageMaker platform, the EMR Serverless integration provides a unified and intuitive experience for datascientists and engineers. By unlocking the potential of your data, this powerful integration drives tangible business results.
With a range of role types available, how do you find the perfect balance of DataScientists , Data Engineers and Data Analysts to include in your team? The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data.
In conjunction with tools like RStudio on SageMaker, users are analyzing, transforming, and preparing large amounts of data as part of the data science and ML workflow. Datascientists and data engineers use Apache Spark, Hive, and Presto running on Amazon EMR for large-scale dataprocessing.
In this post, we explore the concept of querying data using naturallanguage, eliminating the need for SQL queries or coding skills. NaturalLanguageProcessing (NLP) and advanced AI technologies can allow users to interact with their data intuitively by asking questions in plain language.
And retailers frequently leverage data from chatbots and virtual assistants, in concert with ML and naturallanguageprocessing (NLP) technology, to automate users’ shopping experiences. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
During the iterative research and development phase, datascientists and researchers need to run multiple experiments with different versions of algorithms and scale to larger models. However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise.
Heres what we noticed from analyzing this data, highlighting whats remained the same over the years, and what additions help make the modern datascientist in2025. Data Science Of course, a datascientist should know data science! Joking aside, this does infer particular skills.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
For instance, today’s machine learning tools are pushing the boundaries of naturallanguageprocessing, allowing AI to comprehend complex patterns and languages. Scikit Learn Scikit Learn is a comprehensive machine learning tool designed for data mining and large-scale unstructured data analysis.
Amazon SageMaker provides a suite of built-in algorithms , pre-trained models , and pre-built solution templates to help datascientists and machine learning (ML) practitioners get started on training and deploying ML models quickly. They can process various types of input data, including tabular, image, and text.
What is still challenging Data science is iterative & the social sector under-invests in R&D. Datascientists can be hard to hire and support well (and its no fun being a lone datascientist). Deep learning - It is hard to overstate how deep learning has transformed data science.
By integrating LLMs, the WxAI team enables advanced capabilities such as intelligent virtual assistants, naturallanguageprocessing (NLP), and sentiment analysis, allowing Webex Contact Center to provide more personalized and efficient customer support. The following diagram illustrates the WxAI architecture on AWS.
Using the Neuron Distributed library with SageMaker SageMaker is a fully managed service that provides developers, datascientists, and practitioners the ability to build, train, and deploy machine learning (ML) models at scale. Using PyTorch Neuron gives datascientists the ability to track training progress in a TensorBoard.
Tools like LangChain , combined with a large language model (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart , simplify the implementation process. The model then uses a clustering algorithm to group the sentences into clusters. Suhas chowdary Jonnalagadda is a DataScientist at AWS Global Services.
This is a guest post co-authored with Ville Tuulos (Co-founder and CEO) and Eddie Mattia (DataScientist) of Outerbounds. Historically, naturallanguageprocessing (NLP) would be a primary research and development expense.
Answering one of the most common questions I get asked as a Senior DataScientist — What skills and educational background are necessary to become a datascientist? Photo by Eunice Lituañas on Unsplash To become a datascientist, a combination of technical skills and educational background is typically required.
Understanding these operations enables datascientists and Machine Learning engineers to design better algorithms and improve model accuracy. Example In NaturalLanguageProcessing (NLP), word embeddings are often represented as vectors. These cases illustrate the practical impact of Linear Algebra techniques.
To help you stay ahead of the curve, ODSC APAC this August 22nd-23rd will feature expert-led training sessions in both data science fundamentals and cutting-edge tools and frameworks. Check out a few of them below. Finally, you’ll explore how to handle missing values and training and validating your models using PySpark.
Datascientists and developers can quickly prototype and experiment with various ML use cases, accelerating the development and deployment of ML applications. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms.
Large language models (LLMs) are a class of foundational models (FM) that consist of layers of neural networks that have been trained on these massive amounts of unlabeled data. Large language models (LLMs) have taken the field of AI by storm.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the datascientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
OpenSearch Service currently has tens of thousands of active customers with hundreds of thousands of clusters under management processing trillions of requests per month. Matthew Rhodes is a DataScientist I working in the Amazon ML Solutions Lab. Prerequisites.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. SageMaker features and capabilities help developers and datascientists get started with naturallanguageprocessing (NLP) on AWS with ease.
Clustering. Another unsupervised learning method, clustering is the practice of assigning labels to unlabeled data using the patterns that exist in it. It assists in finding out structures in data that can group similar data points together. This technique is used for detecting fake news on social media as well.
Team / participant Features Models Data sources NASAPalooza Paper search, paper recommendation, doc upload, paper summarization, chatbot, people search, keyword extraction, topic trends, dataset analysis GPT-3.5 He also boasts several years of experience with NaturalLanguageProcessing (NLP). bge-small-en-v1.5
Neural networks are inspired by the structure of the human brain, and they are able to learn complex patterns in data. Deep Learning has been used to achieve state-of-the-art results in a variety of tasks, including image recognition, NaturalLanguageProcessing, and speech recognition.
The Bay Area Chapter of Women in Big Data (WiBD) hosted its second successful episode on the NLP (NaturalLanguageProcessing), Tools, Technologies and Career opportunities. Computational Linguistics is rule based modeling of naturallanguages. The event was part of the chapter’s technical talk series 2023.
Solving Machine Learning Tasks with MLCoPilot: Harnessing Human Expertise for Success Many of us have made use of large language models (LLMs) like ChatGPT to generate not only text and images but also code, including machine learning code. But what if LLMs could also engage in a cooperative approach?
These embeddings are useful for various naturallanguageprocessing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. About the Authors Kara Yang is a DataScientist at AWS Professional Services in the San Francisco Bay Area, with extensive experience in AI/ML.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, datascientists typically start their workflow by discovering relevant data sources and connecting to them.
The programming language can handle Big Data and perform effective data analysis and statistical modelling. Hence, you can use R for classification, clustering, statistical tests and linear and non-linear modelling. How is R Used in Data Science?
For any machine learning (ML) problem, the datascientist begins by working with data. This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process.
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from data preparation and model training to deployment and monitoring.
Amazon Bedrock Guardrails implements content filtering and safety checks as part of the query processing pipeline. Anthropic Claude LLM performs the naturallanguageprocessing, generating responses that are then returned to the web application. He specializes in generative AI, machine learning, and system design.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content