This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The use of RStudio on SageMaker and Amazon Redshift can be helpful for efficiently performing analysis on large data sets in the cloud. However, working with data in the cloud can present challenges, such as the need to remove organizational datasilos, maintain security and compliance, and reduce complexity by standardizing tooling.
The primary objective of this idea is to democratize data and make it transparent by breaking down datasilos that cause friction when solving business problems. What Components Make up the Snowflake Data Cloud?
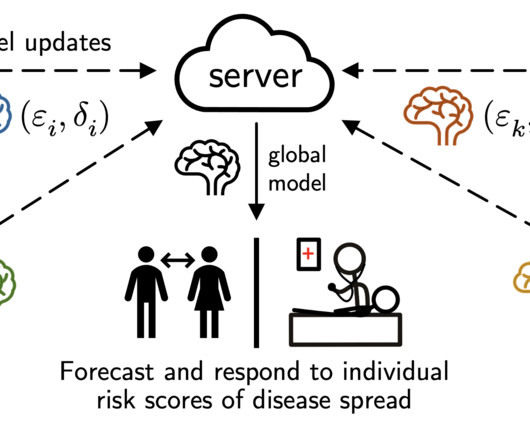
Unfortunately, while this data contains a wealth of useful information for disease forecasting, the data itself may be highly sensitive and stored in disparate locations (e.g., In this post we discuss our research on federated learning , which aims to tackle this challenge by performing decentralized learning across private datasilos.
For more information, refer to Releasing FedLLM: Build Your Own Large Language Models on Proprietary Data using the FedML Platform. FedML Octopus System hierarchy and heterogeneity is a key challenge in real-life FL use cases, where different datasilos may have different infrastructure with CPU and GPUs.
This is due to a fragmented ecosystem of datasilos, a lack of real-time fraud detection capabilities, and manual or delayed customer analytics, which results in many false positives. Snowflake Marketplace offers data from leading industry providers such as Axiom, S&P Global, and FactSet.
A 2019 survey by McKinsey on global data transformation revealed that 30 percent of total time spent by enterprise IT teams was spent on non-value-added tasks related to poor data quality and availability. The data lake can then refine, enrich, index, and analyze that data. And what about the Thor and Roxie clusters?
It also enables models to be trained on diverse data sources, potentially leading to better generalisation and performance. While traditional Machine Learning often involves datasilos and security concerns, Federated Learning offers a more privacy-preserving solution that can operate effectively across various environments.
A data mesh is a decentralized approach to data architecture that’s been gaining traction as a solution to the challenges posed by large and complex data ecosystems. It’s all about breaking down datasilos, empowering domain teams to take ownership of their data, and fostering a culture of data collaboration.
This evolution led to the emergence of multimodal databases that can store and process not only relational data but also all other types of data in their native form, including XML, HTML, JSON, Apache Avro and Parquet, and documents, with minimal transformation required.
Not only can phData provide development resources to aid your business, but we can also provide analytics engineers to derive insights from your data, visualization developers to create front-end facing applications, and our Elastic Platform Operations can ensure that your environment runs smoothly and continues to in the future.
The degree of positive results is generally clustered in companies with under 500 employees and companies with 1,000- 5,000 employees. The second most frequently selected response, at 47%, is using technology and processes to profile data and improve quality.
It combines internal, external, and third-party data for analysis and visualization while considering the geographical context in which data is collected. Spatial analytics solutions make it easy to combine, organize, manage, and query data from across datasilos.
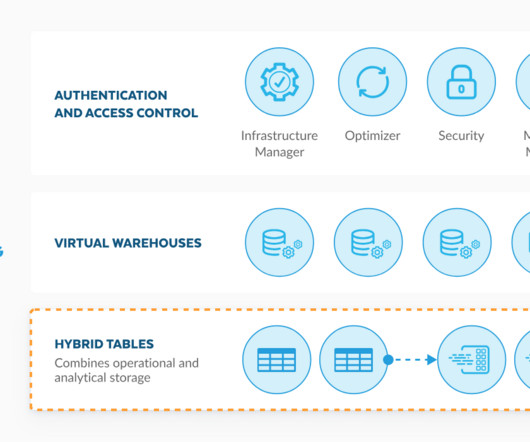
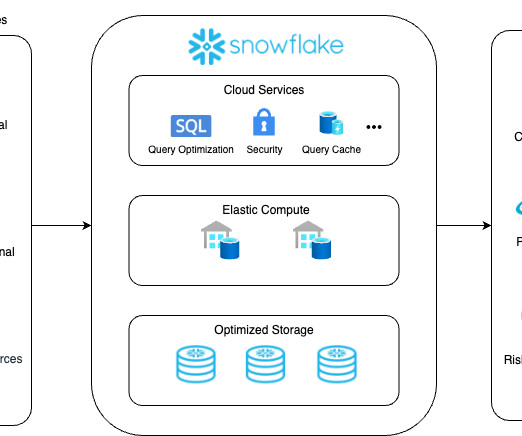
Understanding Snowflake Snowflake is a cloud-based data platform that organizations can use to simplify their data architectures and eliminate datasilos. There are four architectural layers to Snowflake’s platform: Optimized Storage – organizations can bring their unstructured, semi-structured, and structured data.
Here are some of the biggest challenges: SAP Infrastructure With over 10,000 tables, all with difficult to understand table and column names, SAP’s data model is extremely hard to work with. On top of this, SAP uses proprietary data formats such as clustered tables and calculated views that make it difficult to understand.
Can you identify any clusters or groups of NFTs within the collection based on their attributes or characteristics? About Ocean Protocol Ocean Protocol is an ecosystem of open source data sharing tools for the blockchain. Provide a visual overview of the NFT collections of your choice and its characteristics (e.g.
Analyzing real-world healthcare and life sciences (HCLS) data poses several practical challenges, such as distributed datasilos, lack of sufficient data at a single site for rare events, regulatory guidelines that prohibit data sharing, infrastructure requirement, and cost incurred in creating a centralized data repository.
Consider a scenario where a doctor is presented with a patient exhibiting a cluster of unusual symptoms. This can create datasilos and hinder the flow of information within a healthcare organization. Here’s where a CDSS steps in.
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of datasilos or the need to copy data between systems. Notice the subscribed asset is shared under the folder project.
Currently, organizations often create custom solutions to connect these systems, but they want a more unified approach that them to choose the best tools while providing a streamlined experience for their data teams. You can use Amazon SageMaker Lakehouse to achieve unified access to data in both data warehouses and data lakes.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content