This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Amazon’s Redshift Database is a cloud-based large data warehousing solution. Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system.
Built into Data Wrangler, is the Chat for data prep option, which allows you to use natural language to explore, visualize, and transform your data in a conversational interface. Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. A provisioned or serverless Amazon Redshift datawarehouse.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. or a later version) database.
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Some NoSQL databases are also utilized as platforms for data lakes.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.
What is an online transaction processing database (OLTP)? OLTP is the backbone of modern data processing, a critical component in managing large volumes of transactions quickly and efficiently. This approach allows businesses to efficiently manage large amounts of data and leverage it to their advantage in a highly competitive market.
Introduction Dedicated SQL pools offer fast and reliable data import and analysis, allowing businesses to access accurate insights while optimizing performance and reducing costs. DWUs (DataWarehouse Units) can customize resources and optimize performance and costs.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale.
Its ability to scale efficiently has allowed companies to harness the insights locked within their data, paving the way for enhanced analytics, predictive insights, and innovative applications across various industries. Hadoop is an open-source framework that supports distributed data processing across clusters of computers.
Data mining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
It is a cloud-native approach, and it suits a small team that does not want to host, maintain, and operate a Kubernetes cluster alonewith all the resulting responsibilities (and costs). The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the data pipelines.
Amazon Redshift is a fully managed, fast, secure, and scalable cloud datawarehouse. Organizations often want to use SageMaker Studio to get predictions from data stored in a datawarehouse such as Amazon Redshift. On the Name, review, and create page, enter a role name, review the settings, and choose Create role.
Data Management is considered to be a core function of any organization. Data management software helps in reducing the cost of maintaining the data by helping in the management and maintenance of the data stored in the database. There are various types of data management systems available.
Many of the RStudio on SageMaker users are also users of Amazon Redshift , a fully managed, petabyte-scale, massively parallel datawarehouse for data storage and analytical workloads. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. It utilises the Hadoop Distributed File System (HDFS) and MapReduce for efficient data management, enabling organisations to perform big data analytics and gain valuable insights from their data.
What Components Make up the Snowflake Data Cloud? This data mesh strategy combined with the end consumers of your data cloud enables your business to scale effectively, securely, and reliably without sacrificing speed-to-market. What is a Cloud DataWarehouse? Today, data lakes and datawarehouses are colliding.
A user can ask for data to be examined so that they can see a spreadsheet with all of an industry’s beach ball products that are sold in Florida in July, compare revenue statistics with all those for almost the same items in September, and compare other demand for a product in Florida during the same time period.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster. If you want to do the process in a low-code/no-code way, you can follow option C.
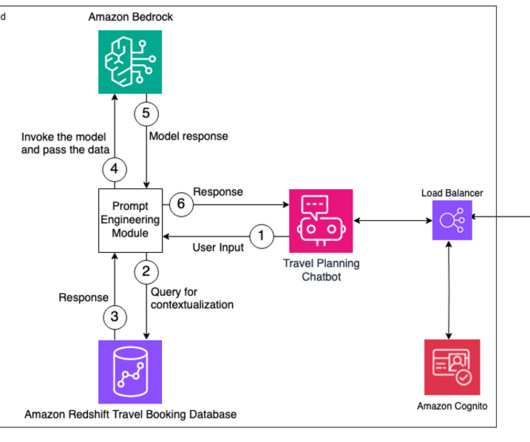
In this post, we discuss how to use the comprehensive capabilities of Amazon Bedrock to perform complex business tasks and improve the customer experience by providing personalization using the data stored in a database like Amazon Redshift. For example: ssh -i “id_rsa” ec2-user@ ec2-54-xxx-xxx-187.compute-1.amazonaws.com
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Datawarehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
Solution overview With SageMaker Studio JupyterLab notebook’s SQL integration, you can now connect to popular data sources like Snowflake, Athena, Amazon Redshift, and Amazon DataZone. For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem.
“ Vector Databases are completely different from your cloud datawarehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Are you interested in exploring Snowflake as a vector database? Contact phData Today!
Common databases appear unable to cope with the immense increase in data volumes. This is where the BigQuery datawarehouse comes into play. BigQuery operation principles Business intelligence projects presume collecting information from different sources into one database.
In today’s world, data-driven applications demand more flexibility, scalability, and auditability, which traditional datawarehouses and modeling approaches lack. This is where the Snowflake Data Cloud and data vault modeling comes in handy. What is Data Vault Modeling?
Understanding Data Vault Modeling Created in the 1990s by a team at Lockheed Martin, data vault modeling is a hybrid approach that combines traditional relational datawarehouse models with newer big data architectures to build a datawarehouse for enterprise-scale analytics.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
When a query is constructed, it passes through a cost-based optimizer, then data is accessed through connectors, cached for performance and analyzed across a series of servers in a cluster. Because of its distributed nature, Presto scales for petabytes and exabytes of data.
It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a datawarehouse or a database. First, the data is extracted from the various sources and brought into a staging area.
Datawarehouses are a critical component of any organization’s technology ecosystem. The next generation of IBM Db2 Warehouse brings a host of new capabilities that add cloud object storage support with advanced caching to deliver 4x faster query performance than previously, while cutting storage costs by 34x 1.
The Snowflake Data Cloud has been a market leader for database systems that are built for the cloud and support an unlimited number of warehouses. For a small amount of data, increasing the warehouse size does work, but when you are in the multi-terabyte range, it might not always work. .”
Its visual interface allows you to design workflows, handle data extraction and transformation, and apply statistical methods or machine learning algorithms. It’s a highly versatile tool, supporting various data types, from simple Excel files to complex databases or big data technologies. Oh–and it’s free.
ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing datawarehouses. Prior to the cloud, setting up and operating a cluster that can handle workloads like this would have been a major technical challenge.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to data modeling, making it easier to ensure data quality and consistency across the ML pipelines.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, datawarehouses, and data lakes.
Velocity It indicates the speed at which data is generated and processed, necessitating real-time analytics capabilities. Businesses need to analyse data as it streams in to make timely decisions. This diversity requires flexible data processing and storage solutions.
They encompass all the origins from which data is collected, including: Internal Data Sources: These include databases, enterprise resource planning (ERP) systems, customer relationship management (CRM) systems, and flat files within an organization. Data can be structured (e.g., databases), semi-structured (e.g.,
Also Read: Top 10 Data Science tools for 2024. It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. This process helps organisations manage large volumes of data efficiently.
It acts as a catalogue, providing information about the structure and location of the data. · Hive Query Processor It translates the HiveQL queries into a series of MapReduce jobs. · Hive Execution Engine It executes the generated query plans on the Hadoop cluster. It manages the execution of tasks across different environments.
Setting up the Information Architecture Setting up an information architecture during migration to Snowflake poses challenges due to the need to align existing data structures, types, and sources with Snowflake’s multi-cluster, multi-tier architecture.
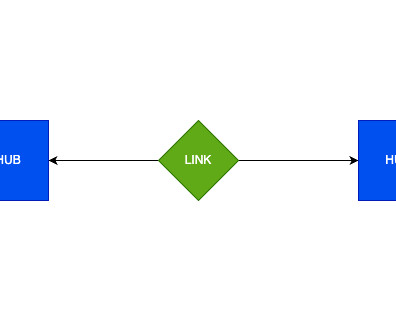
What is a Data Vault Architecture? Created in the 1990s by a team at Lockheed Martin, Data Vault Modeling is a hybrid approach that combines traditional relational datawarehouse models with newer big data architectures to build a datawarehouse for enterprise-scale analytics. Contact phData!
It was designed first and foremost with the cloud in mind, leveraging the scalability to tackle many of the challenges faced with traditional data warehousing solutions. Snowflake is built on a unique architecture known as the multi-cluster shared data architecture, which separates compute resources from storage.
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a datawarehouse or data lake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content