This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data mining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. Consequently, each brand of the decisiontree will yield a distinct result.
Naïve Bayes algorithms include decisiontrees , which can actually accommodate both regression and classification algorithms. Random forest algorithms —predict a value or category by combining the results from a number of decisiontrees.
From there, a machine learning framework like TensorFlow, H2O, or Spark MLlib uses the historical data to train analytic models with algorithms like decisiontrees, clustering, or neural networks. Tiered Storage enables long-term storage with low cost and the ability to more easily operate large Kafka clusters.
Public Datasets: Utilising publicly available datasets from repositories like Kaggle or government databases. DecisionTreesDecisiontrees recursively partition data into subsets based on the most significant attribute values. Web Scraping : Extracting data from websites and online sources.
” Data management and manipulation Data scientists often deal with vast amounts of data, so it’s crucial to understand databases, data architecture, and query languages like SQL. It involves developing algorithms that can learn from and make predictions or decisions based on data.
It leverages the power of technology to provide actionable insights and recommendations that support effective decision-making in complex business scenarios. At its core, decision intelligence involves collecting and integrating relevant data from various sources, such as databases, text documents, and APIs.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping. Data Cleaning: Raw data often contains errors, inconsistencies, and missing values.
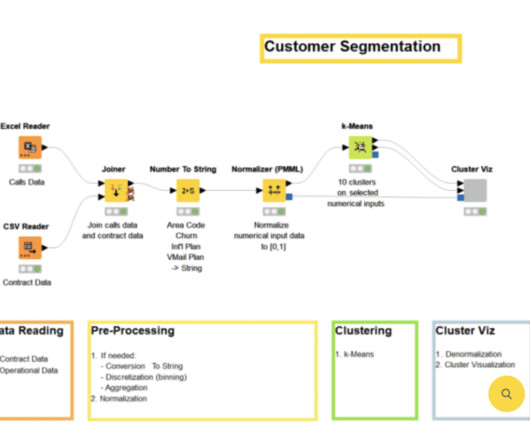
Clustering Metrics Clustering is an unsupervised learning technique where data points are grouped into clusters based on their similarities or proximity. Evaluation metrics include: Silhouette Coefficient - Measures the compactness and separation of clusters.
Clustering and dimensionality reduction are common tasks in unSupervised Learning. For example, clustering algorithms can group customers by purchasing behaviour, even if the group labels are not predefined. Decisiontrees are easy to interpret but prone to overfitting. Different algorithms are suited to different tasks.
It’s a highly versatile tool, supporting various data types, from simple Excel files to complex databases or big data technologies. It starts with KNIME, which can directly connect to your Snowflake data warehouse using its dedicated database Snowflake connector node. Oh–and it’s free.
Businesses need to analyse data as it streams in to make timely decisions. Variety It encompasses the different types of data, including structured data (like databases), semi-structured data (like XML), and unstructured formats (such as text, images, and videos). This diversity requires flexible data processing and storage solutions.
Think of “expert systems” from the 1980s, designed to mimic the decision-making ability of a human expert in a specific domain (like medical diagnosis or financial planning). These systems used vast databases of knowledge and complex if-then rules coded by humans.
Key Processes and Techniques in Data Analysis Data Collection: Gathering raw data from various sources (databases, APIs, surveys, sensors, etc.). Modeling: Build a logistic regression or decisiontree model to predict the likelihood of a customer churning based on various factors. This helps formulate hypotheses.
It systematically collects data from diverse sources such as databases, online repositories, sensors, and other digital platforms, ensuring a comprehensive dataset is available for subsequent analysis and insights extraction. These include databases, APIs, web scraping, and public datasets.
Data can be collected from various sources, such as databases, sensors, or the internet. Algorithms: Algorithms are used to develop AI models that can learn from data and make predictions or decisions. This data could be in the form of structured data (such as data in a database) or unstructured data (such as text, images, or audio).
SQL: Mastering Data Manipulation Structured Query Language (SQL) is a language designed specifically for managing and manipulating databases. While it may not be a traditional programming language, SQL plays a crucial role in Data Science by enabling efficient querying and extraction of data from databases.
There are majorly two categories of sampling techniques based on the usage of statistics, they are: Probability Sampling techniques: Clustered sampling, Simple random sampling, and Stratified sampling. Decisiontrees are more prone to overfitting. Some algorithms that have low bias are DecisionTrees, SVM, etc.
They can provide information, summaries and insights across many fields without the need for external databases in real-time applications. This is important for real-time decision-making tasks, like autonomous vehicles or high-frequency trading. AI Democratization - LLMs democratize access to AI by lowering the entry barrier.
DecisionTrees These trees split data into branches based on feature values, providing clear decision rules. Key techniques in unsupervised learning include: Clustering (K-means) K-means is a clustering algorithm that groups data points into clusters based on their similarities. databases, CSV files).
Clustering and anomaly detection are examples of unsupervised learning tasks. Reinforcement Learning Reinforcement learning focuses on teaching the model to make decisions by rewarding it for correct actions and penalising it for mistakes. Common applications include image recognition and fraud detection.
1 KNN 2 DecisionTree 3 Random Forest 4 Naive Bayes 5 Deep Learning using Cross Entropy Loss To some extent, Logistic Regression and SVM can also be leveraged to solve a multi-class classification problem by fitting multiple binary classifiers using a one-vs-all or one-vs-one strategy. A set of classes sometimes forms a group/cluster.
SQL stands for Structured Query Language, essential for querying and manipulating data stored in relational databases. The SELECT statement retrieves data from a database, while SELECT DISTINCT eliminates duplicate rows from the result set. What are the advantages and disadvantages of decisiontrees ?
It offers implementations of various machine learning algorithms, including linear and logistic regression , decisiontrees , random forests , support vector machines , clustering algorithms , and more. It is commonly used in MLOps workflows for deploying and managing machine learning models and inference services.
A typical pipeline may include: Data Ingestion: The process begins with ingesting raw data from different sources, such as databases, files, or APIs. This is an ensemble learning method that builds multiple decisiontrees and combines their predictions to improve accuracy and reduce overfitting. Create the ML model.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content