This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
It integrates retrieval-based and generation-based approaches to provide a robust database for LLMs. By combining vector databases and LLM, the retrieval model has set up a standard for the search and navigation of data for generative AI. Access to a large and accurate database ensures that factually correct results are generated.
To address this, machine learning models attempt to predict how genes will behave under perturbation before actually conducting experiments. These models use knowledge graphs databases of known biological interactionsto infer how a new gene disruption might affect a cell.
Data mining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Association rule mining Association rule mining identifies interesting relations between variables in large databases.
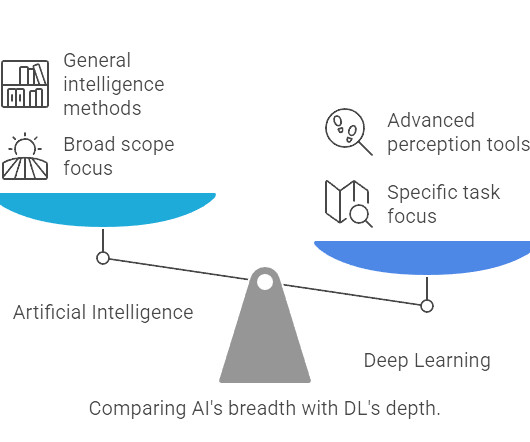
Summary: Artificial Intelligence (AI) and DeepLearning (DL) are often confused. AI vs DeepLearning is a common topic of discussion, as AI encompasses broader intelligent systems, while DL is a subset focused on neural networks. Is DeepLearning just another name for AI? Is all AI DeepLearning?
In this blog post, we’ll explore how to deploy LLMs such as Llama-2 using Amazon Sagemaker JumpStart and keep our LLMs up to date with relevant information through Retrieval Augmented Generation (RAG) using the Pinecone vector database in order to prevent AI Hallucination. Sign up for a free-tier Pinecone Vector Database.
Summary: Machine Learning and DeepLearning are AI subsets with distinct applications. Introduction In todays world of AI, both Machine Learning (ML) and DeepLearning (DL) are transforming industries, yet many confuse the two. Clustering and anomaly detection are examples of unsupervised learning tasks.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. The service uses deeplearning techniques to handle complex data patterns and enables businesses to generate accurate forecasts even with minimal historical data.
Deeplearning continues to be a hot topic as increased demands for AI-driven applications, availability of data, and the need for increased explainability are pushing forward. So let’s take a quick dive and see some big sessions about deeplearning coming up at ODSC East May 9th-11th.
To learn how to develop Face Recognition applications using Siamese Networks, just keep reading. Jump Right To The Downloads Section Face Recognition with Siamese Networks, Keras, and TensorFlow Deeplearning models tend to develop a bias toward the data distribution on which they have been trained.
The most common unsupervised learning method is cluster analysis, which uses clustering algorithms to categorize data points according to value similarity (as in customer segmentation or anomaly detection ).
Photo by Aditya Chache on Unsplash DBSCAN in Density Based Algorithms : Density Based Spatial Clustering Of Applications with Noise. Earlier Topics: Since, We have seen centroid based algorithm for clustering like K-Means.Centroid based : K-Means, K-Means ++ , K-Medoids. & One among the many density based algorithms is “DBSCAN”.
Amazon Titan Text Embeddings is a text embeddings model that converts natural language text—consisting of single words, phrases, or even large documents—into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity. Why do we need an embeddings model?
Data storage databases. Your SaaS company can automate time-consuming tasks like provisioning, patching, backup, recovery, and failure detection and repair with Amazon Aurora, a MySQL-compatible database from Amazon. AWS also offers developers the technology to develop smart apps using machine learning and complex algorithms.
The diverse and rich database of models brings unique challenges for choosing the most efficient deployment infrastructure that gives the best latency and performance. First, we started by benchmarking our workloads using the readily available Graviton DeepLearning Containers (DLCs) in a standalone environment.
Patrick Lewis “We definitely would have put more thought into the name had we known our work would become so widespread,” Lewis said in an interview from Singapore, where he was sharing his ideas with a regional conference of database developers. “We Retrieval-augmented generation combines LLMs with embedding models and vector databases.
Solving Machine Learning Tasks with MLCoPilot: Harnessing Human Expertise for Success Many of us have made use of large language models (LLMs) like ChatGPT to generate not only text and images but also code, including machine learning code. Vector databases can store them and are designed for search and data mining.
We continued our efforts in developing new algorithms for handling large datasets in various areas, including unsupervised and semi-supervised learning , graph-based learning , clustering , and large-scale optimization. Inspired by the success of multi-core processing (e.g., The big challenge here is to achieve fast (e.g.,
The architecture is built on a robust and secure AWS foundation: The architecture uses AWS services like Application Load Balancer , AWS WAF , and EKS clusters for seamless ingress, threat mitigation, and containerized workload management. The following diagram illustrates the WxAI architecture on AWS.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deeplearning. Tools and frameworks like Scikit-Learn, TensorFlow, and Keras are often covered.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster.
These controllers allow Kubernetes users to provision AWS resources like buckets, databases, or message queues simply by using the Kubernetes API. Prerequisites To follow along, you should have a Kubernetes cluster with the SageMaker ACK controller v1.2.9 Release v1.2.9 or above installed.
In programming, You need to learn two types of language. One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. There is one Query language known as SQL (Structured Query Language), which works for a type of database. Why do we need databases?
Photo by Resource Database on Unsplash Introduction Neural networks have been operating on graph data for over a decade now. There are three different types of learning tasks that are associated with GNN. Want to get the most up-to-date news on all things DeepLearning? GNNs also differ in their graph execution process.
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. Additionally, we’re using a custom Airflow operator called ECSTaskLogOperator that allows us to process Amazon CloudWatch logs using downstream systems.
Unsupervised Learning Algorithms Unsupervised Learning Algorithms tend to perform more complex processing tasks in comparison to supervised learning. However, unsupervised learning can be highly unpredictable compared to natural learning methods. It can be either agglomerative or divisive.
Vectors are typically stored in Vector Databases which are best suited for searching. APIs File Directories Databases And many more The first step is to extract the information present in these source locations. For this we use a special kind of database called the Vector Database. What is a Vector Database?
Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy data science projects. Check out the Kubeflow documentation.
Orchestration Tools: Kubernetes, Docker Swarm Purpose: Manages the deployment, scaling, and operation of application containers across clusters of hosts. Do you think learning computer vision and deeplearning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations?
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deeplearning to the team. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deeplearning. TensorFlow and Keras: TensorFlow is an open-source platform for machine learning. Web Scraping : Extracting data from websites and online sources.
A database that help index and search at blazing speed. Relational databases (like MySQL) or No-SQL databases (AWS DynamoDB) can store structured or even semi-structured data but there is one inherent problem. Unstructured data is hard to store in relational databases.
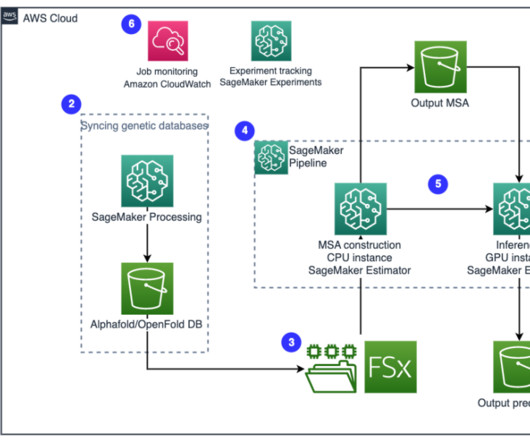
Recent advances in deeplearning methods for protein research have shown promise in using neural networks to predict protein folding with remarkable accuracy. Genetic databases – A genetic database is one or more sets of genetic data stored together with software to enable users to retrieve genetic data.
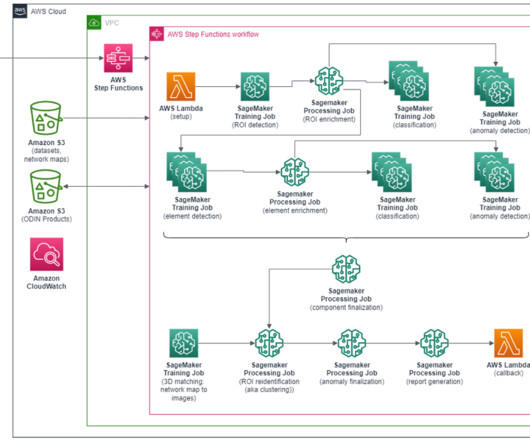
Examination of this data is critical for monitoring the state of the power grid, identifying infrastructure anomalies, and updating databases of installed assets, and it allows granular control of the infrastructure down to the material and status of the smallest insulator installed on a given pole.
It uses a vector database structure to efficiently store and query large volumes of data. OpenSearch Service currently has tens of thousands of active customers with hundreds of thousands of clusters under management processing hundreds of trillions of requests per month.
In the RAG-based approach we convert the user question into vector embeddings using an LLM and then do a similarity search for these embeddings in a pre-populated vector database holding the embeddings for the enterprise knowledge corpus. The notebook also ingests the data into another vector database called FAISS.
With advances in machine learning, deeplearning, and natural language processing, the possibilities of what we can create with AI are limitless. Develop AI models using machine learning or deeplearning algorithms. Data can be collected from various sources, such as databases, sensors, or the internet.
It is mainly used for deeplearning applications. PyTorch PyTorch is a popular, open-source, and lightweight machine learning and deeplearning framework built on the Lua-based scientific computing framework for machine learning and deeplearning algorithms.
Traditional AI can recognize, classify, and cluster, but not generate the data it is trained on. al 600+: Key technological concepts of generative AI 300+: DeepLearning — the core of any generative AI model: Deeplearning is a central concept of traditional AI that has been adopted and further developed in generative AI.
SVM-based classifier: Amazon Titan Embeddings In this scenario, it is likely that user interactions belonging to the three main categories ( Conversation , Services , and Document_Translation ) form distinct clusters or groups within the embedding space. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
This dataset comprises a multi-center critical care database collected from over 200 hospitals, which makes it ideal to test our FL experiments. We used the eICU Collaborative Research Database , a multi-center intensive care unit (ICU) database, comprising 200,859 patient unit encounters for 139,367 unique patients.
We used FSx for Lustre and Amazon Relational Database Service (Amazon RDS) for fast parallel data access. With a strong background in computer vision, data science, and deeplearning, he holds a postgraduate degree from IIT Bombay. Store data in an Amazon Simple Storage Service (Amazon S3) bucket.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content