This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Retrieval Augmented Generation generally consists of Three major steps, I will explain them briefly down below – Information Retrieval The very first step involves retrieving relevant information from a knowledge base, database, or vector database, where we store the embeddings of the data from which we will retrieve information.
Additionally, we dive into integrating common vector database solutions available for Amazon Bedrock Knowledge Bases and how these integrations enable advanced metadata filtering and querying capabilities.
For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2.
Each of these demos can be adapted to a number of industries and customized to specific needs. You can also watch the complete library of demos here. Output structured data is stored in a database, accessible for reporting or downstream applications. Watch the smart call center analysis app demo.
Visualizing graph data doesn’t necessarily depend on a graph database… Working on a graph visualization project? You might assume that graph databases are the way to go – they have the word “graph” in them, after all. Do I need a graph database? It depends on your project. Unstructured? Under construction?
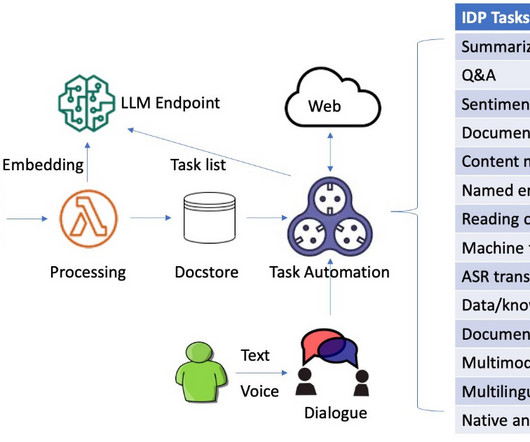
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The following demo shows Agent Creator in action. Chunker Snap – Segments large texts into manageable pieces.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
What if you could automatically shard your PostgreSQL database across any number of servers and get industry-leading performance at scale without any special data modelling steps? And if you want to see demos of some of this functionality, be sure to join us for the livestream of the Citus 12.0 Updates page. Let’s dive in!
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Enter a stack name, such as Demo-Redshift. This is the maximum allowed number of domains in each supported Region.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster. Choose Add connection.
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Enhanced Search and Retrieval Augmented Generation: Vector search systems work by matching queries with embeddings in a database.
Amazon Titan Text Embeddings is a text embeddings model that converts natural language text—consisting of single words, phrases, or even large documents—into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
In this blog, we’ll review the DataRobot new Time Series clustering feature, which gives you a creative edge to build time series forecasting models by automatically grouping series that are identical to each other and then building models tailored to these groups. You can also connect to Snowflake, Azure, Redshift and many other databases.
Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first EOM contract with the database company Hyperion—that’s when I was hired. Let’s take a look at each. .
These controllers allow Kubernetes users to provision AWS resources like buckets, databases, or message queues simply by using the Kubernetes API. Prerequisites To follow along, you should have a Kubernetes cluster with the SageMaker ACK controller v1.2.9 Release v1.2.9 Now you also can use them with SageMaker Operators for Kubernetes.
In this post, we describe how CBRE partnered with AWS Prototyping to develop a custom query environment allowing natural language query (NLQ) prompts by using Amazon Bedrock, AWS Lambda , Amazon Relational Database Service (Amazon RDS), and Amazon OpenSearch Service. Embeddings were generated using Amazon Titan.
When a query is constructed, it passes through a cost-based optimizer, then data is accessed through connectors, cached for performance and analyzed across a series of servers in a cluster. They stood up a file-based data lake alongside their analytical database. Uber has made the Presto query engine connect to real-time databases.
We use Cohere Command and AI21 Labs Jurassic-2 Mid for this demo. DynamoDB table An application running on AWS uses an Amazon Aurora Multi-AZ DB cluster deployment for its database. Enable read-through caching on the Aurora database. Create a second Aurora database and link it to the primary database as a read replica.
The database used for this competition is based on the Perfumery Materials & Performance dataset by Leffingwell & Associates and the Good Scents Company Information system. Upon further reflection of the embeddings, it’s possible to see clusters of particular molecules. Request a demo. See DataRobot in Action.
To understand how DataRobot AI Cloud and Big Query can align, let’s explore how DataRobot AI Cloud Time Series capabilities help enterprises with three specific areas: segmented modeling, clustering, and explainability. Enable Granular Forecasts with Clustering. This is where clustering comes in.
Additionally, we have recently announced a partnership and integration with Snowflake to expand deployment options by bringing models directly into the database. To see a demo or to learn how it can be applied to your current use cases, reach out to your DataRobot account team or request a demo today. Request a Demo.
Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. In 2004, Tableau got both an initial series A of venture funding and Tableau’s first OEM contract with the database company Hyperion—that’s when I was hired. Let’s take a look at each. .
We’re working with super-large GPU clusters and are looking at training runs that take weeks or months. Retrieval Augmented Generation (RAG) systems add a vector database and embeddings to the mix, which require dedicated observability tooling. Pretraining is undoubtedly the most expensive activity.
We frequently see this with LLM users, where a good LLM creates a compelling but frustratingly unreliable first demo, and engineering teams then go on to systematically raise quality. Systems can be dynamic. Machine learning models are inherently limited because they are trained on static datasets, so their “knowledge” is fixed.
Our graph visualization SDKs include performance demos, so you can run layouts of thousands of chart items and monitor the frames per second (FPS) rate for comparison. Format: Open source automatic graph drawing/design tool that uses a simple graph description language (DOT) for nodes, edges, clusters etc. Cytoscape.js
or GPT-4 arXiv, OpenAlex, CrossRef, NTRS lgarma Topic clustering and visualization, paper recommendation, saved research collections, keyword extraction GPT-3.5 Currently, published research may be spread across a variety of different publishers, including free and open-source ones like those used in many of this challenge's demos (e.g.
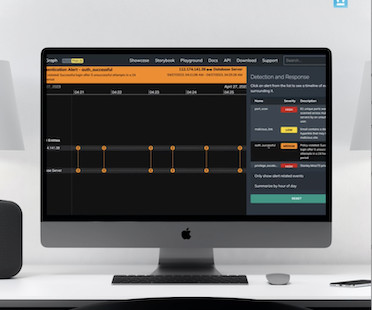
Here, you can find information on the actions and the corresponding workload, such as the container cluster, the namespace and the risk posed to the workload (which, in this case, is transaction congestion): Figure 5 In Figure 6 below, you can see how Turbonomic provides the rationale behind taking the action.
This architecture combines a general-purpose large language model (LLM) with a customer-specific document database, which is accessed through a semantic search engine. Because RAG uses a semantic search, it can find more relevant material in the database than just a keyword match alone. Choose Next. Choose Next.
Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters. Dolt Dolt is an open-source relational database system built on Git. Check out the Kubeflow documentation.
Let’s jump ahead to a few days later, when a red alert shows our database server exchanging a huge number of packets with an external entity. Request full access to our KronoGraph SDK, demos and live-coding playground. What other activity on this file server happened immediately before or after the policy violation?
FREE: The ultimate guide to graph visualization Proven strategies for building successful graph visualization applications GET YOUR FREE GUIDE The earthquakes data source The data I used is from the USGS’s National Earthquake Information Center (NEIC), whose extensive databases of seismic information are freely available. Tōhoku earthquake.
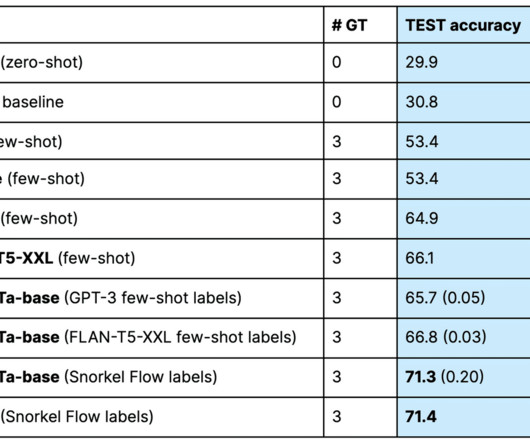
For example, a health insurance company may want their question answering bot to answer questions using the latest information stored in their enterprise document repository or database, so the answers are accurate and reflect their unique business rules. In this demo, we use a Jumpstart Flan T5 XXL model endpoint.
For example, if a data team wants to use an LLM to examine financial documents—something the model may perform poorly on out of the box—the team can fine-tune it on something like the Financial Documents Clustering data set. This information could come from: A vector database such as FAISS or Pinecone. Book a demo today.
This adaptability makes them versatile tools for a variety of industries, from legal document analysis to customer care (For a demo of how to fine-tune a OSS LLM, check out the github repo here ). They can provide information, summaries and insights across many fields without the need for external databases in real-time applications.
It won’t be a long demo, it’ll be a very quick demo of what you can do and how you can operationalize stuff in Snowflake. And then once they’re done with that, it’s very easy to package up, and you’ll see that in the demo today. The demo is actually very simple.
It won’t be a long demo, it’ll be a very quick demo of what you can do and how you can operationalize stuff in Snowflake. And then once they’re done with that, it’s very easy to package up, and you’ll see that in the demo today. The demo is actually very simple.
If we asked whether their companies were using databases or web servers, no doubt 100% of the respondents would have said “yes.” And there are tools for archiving and indexing prompts for reuse, vector databases for retrieving documents that an AI can use to answer a question, and much more. We expect others to follow.
Finally, we store these vectors in a vector database for similarity search. As an alternative, you can use FAISS , an open-source vector clustering solution for storing vectors. One of the key features is its ability to interface with external sources of information, such as the web, databases, and APIs.
With Dr. Jon Krohn you’ll also get hands-on code demos in Jupyter notebooks and strategic advice for overcoming common pitfalls. Here, Weaviate will be introduced as an open-source vector search database with unique features for serving millions of users worldwide.
SQL stands for Structured Query Language, essential for querying and manipulating data stored in relational databases. The SELECT statement retrieves data from a database, while SELECT DISTINCT eliminates duplicate rows from the result set. Additional Benefits Free demo sessions. How do you join tables in SQL?
To keep the system requirements to a minimum, data is stored in an SQLite database by default. Try the live demo! However, the unsupervised algorithm won’t usually return clusters that map neatly to the labels you care about. It’s easy to use a different SQL backend, or to specify a custom storage solution.
The startup cost is now lower to deploy everything from a GPU-enabled virtual machine for a one-off experiment to a scalable cluster for real-time model execution. An example of the Concept to Clinic demo application, which is the kind of user-facing tool that the open source community does not build and maintain on its own.
Clustering health aspects ? We also have some cool Healthsea demos hosted on Hugging Face spaces ? Healthsea Demo Visualization of 1 million analyzed reviews with Healthsea ✨ Healthsea Pipeline Visualization of individual processing steps of the Healthsea pipeline ? You can try out a demo of the Benepar parser here.
All the steps in this demo are available in the accompanying notebook Fine-tuning text generation GPT-J 6B model on a domain specific dataset. We serve developers and enterprises of all sizes through AWS, which offers a broad set of global compute, storage, database, and other service offerings.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content