This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
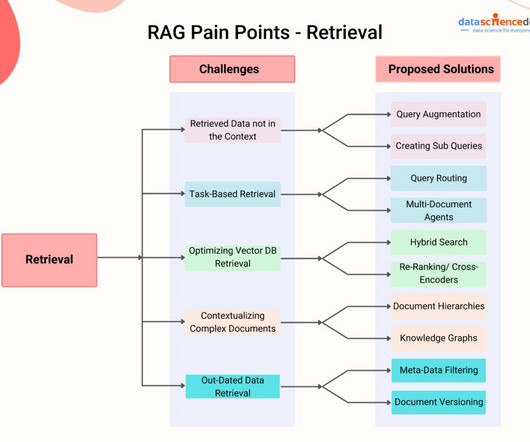
Retrieval Augmented Generation generally consists of Three major steps, I will explain them briefly down below – Information Retrieval The very first step involves retrieving relevant information from a knowledge base, database, or vector database, where we store the embeddings of the data from which we will retrieve information.
A vector database is a type of database that stores data as high-dimensional vectors. One way to think about a vector database is as a way of storing and organizing data that is similar to how the human brain stores and organizes memories. Pinecone is a vector database that is designed for machine learning applications.
Additionally, we dive into integrating common vector database solutions available for Amazon Bedrock Knowledge Bases and how these integrations enable advanced metadata filtering and querying capabilities. Using the query embedding and the metadata filter, relevant documents are retrieved from the knowledge base.
What is an online transaction processing database (OLTP)? But the true power of OLTP databases lies beyond the mere execution of transactions, and delving into their inner workings is to unravel a complex tapestry of data management, high-performance computing, and real-time responsiveness.
I’m writing a book on Retrieval Augmented Generation (RAG) for Wiley Publishing, and vector databases are an inescapable part of building a performant RAG system. I selected Qdrant as the vector database for my book and this series. Check out the documentation to learn how to get set up locally. Copy that and keep it safe.
It provides a wide range of tools for supervised and unsupervised learning, including linear regression, k-means clustering, and support vector machines. It is designed to simplify the process of working with databases by providing a consistent and high-level interface.
This article breaks down what Late Chunking is, why its essential for embedding larger or more intricate documents, and how to build it into your search pipeline using Chonkie and KDB.AI When you have a document that spans thousands of words, encoding it into a single embedding often isnt optimal. as the vector store. Image By Author.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. This same interface is also used for provisioning EMR clusters. The following diagram illustrates this solution.
Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB. This NoSQL database is optimized for rapid access, making sure the knowledge base remains responsive and searchable.
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. For documentation retrieval, Retrieval Augmented Generation (RAG) stands out as a key tool. Virginia) AWS Region. The following diagram illustrates the solution architecture.
Usually, the ingestion stage consists of the following steps: Collect data Chunk data Generate vector embeddings of chunks Store vector embeddings and chunks in a vector database The efficiency and effectiveness of the data ingestion phase significantly influence the overall performance of the system. Finding the optimal balance is crucial.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Set up the database access and network access. Delete the MongoDB Atlas cluster.
A users question is used as the query to retrieve relevant documents from a database. The documents returned by the search are added to the prompt that is passed to the LLM together with the users question. Overview of a baseline RAG system. The LLM uses the information in the prompt to generate an answer.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The user query is used to retrieve relevant additional context from the vector database. The retrieved context and the user query are used to augment a prompt template.
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. For more information on managing credentials securely, see the AWS Boto3 documentation.
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. This event-driven architecture provides immediate processing of new documents.
You can then run searches for the top K documents in an index that are most similar to a given query vector, which could be a question, keyword, or content (such as an image, audio clip, or text) that has been encoded by the same ML model. A right-sized cluster will keep this compressed index in memory.
Document Vectors With the success of word embeddings , it’s understood that entire documents can be represented in a similar way. Document Vectors With the success of word embeddings , it’s understood that entire documents can be represented in a similar way. Let’s create a table to hold our document vectors.
Data archiving is the systematic process of securely storing and preserving electronic data, including documents, images, videos, and other digital content, for long-term retention and easy retrieval. Databases are the unsung heroes of AI Furthermore, data archiving improves the performance of applications and databases.
While we understand the role and importance of embedding models in the world of vector databases, the selection of right model is crucial for the success of an AI application. Some common metrics of this evaluation include semantic relationships between words, word similarity in the embedding space, and word clustering.
It is a cloud-native approach, and it suits a small team that does not want to host, maintain, and operate a Kubernetes cluster alonewith all the resulting responsibilities (and costs). The source data is unstructured JSON, while the target is a structured, relational database. Database size limits of 10GB.
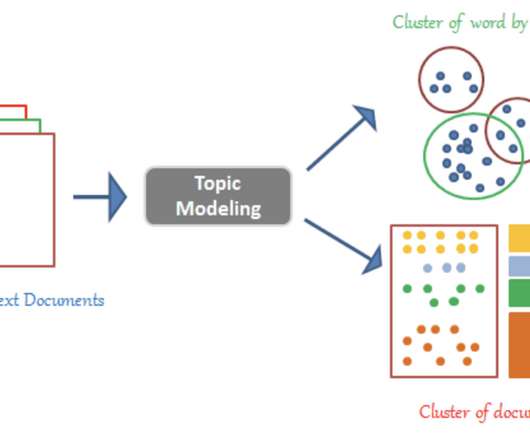
Using the topic modeling approach, a machine can sift through unlimited lists of unstructured content into similar documents. Latent Dirichlet Allocation (LDA) Topic Modeling LDA is a well-known unsupervised clustering method for text analysis. The LDA technique uses parametrized probability distributions for each document.
In this post, you’ll see an example of performing drift detection on embedding vectors using a clustering technique with large language models (LLMS) deployed from Amazon SageMaker JumpStart. In this pattern, the recipe text is converted into embedding vectors using an embedding model, and stored in a vector database.
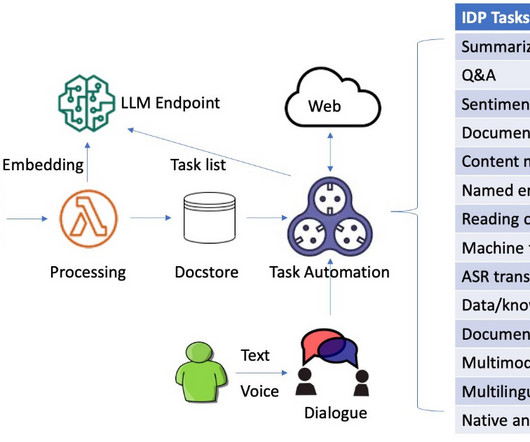
Intelligent document processing (IDP) is a technology that automates the processing of high volumes of unstructured data, including text, images, and videos. The system is capable of processing images, large PDF, and documents in other format and answering questions derived from the content via interactive text or voice inputs.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics.
In this blog post, we’ll explore how to deploy LLMs such as Llama-2 using Amazon Sagemaker JumpStart and keep our LLMs up to date with relevant information through Retrieval Augmented Generation (RAG) using the Pinecone vector database in order to prevent AI Hallucination. Sign up for a free-tier Pinecone Vector Database.
The algorithm learns to find patterns or structure in the data by clustering similar data points together. WHAT IS CLUSTERING? Clustering is an unsupervised machine learning technique that is used to group similar entities. Those groups are referred to as clusters.
In this post, we walk through step-by-step instructions to establish a cross-account connection to any Amazon Redshift node type (RA3, DC2, DS2) by connecting the Amazon Redshift cluster located in one AWS account to SageMaker Studio in another AWS account in the same Region using VPC peering.
CRDTs (Conflict Free Replicated Data Types) are behind tools like Google Docs, which lets multiple users edit a document simultaneously. Database Proliferation Years ago, I wrote that NoSQL wasn’t a database technology; it was a movement. There has been a proliferation of time series and graph databases.
That’s why our data visualization SDKs are database agnostic: so you’re free to choose the right stack for your application. There have been a lot of new entrants and innovations in the graph database category, with some vendors slowly dipping below the radar, or always staying on the periphery. can handle many graph-type problems.
MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. Make sure you have the following prerequisites: Create an S3 bucket Configure MongoDB Atlas cluster Create a free MongoDB Atlas cluster by following the instructions in Create a Cluster.
In our previous article on Retrieval Augmented Generation (RAG), we discussed the need for a Vector Database to retrieve additional information for our prompts. Today, we will dive into the inner workings of a Vector Database to better understand exactly how this technology functions. What is a Vector Database in Simple Terms?
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
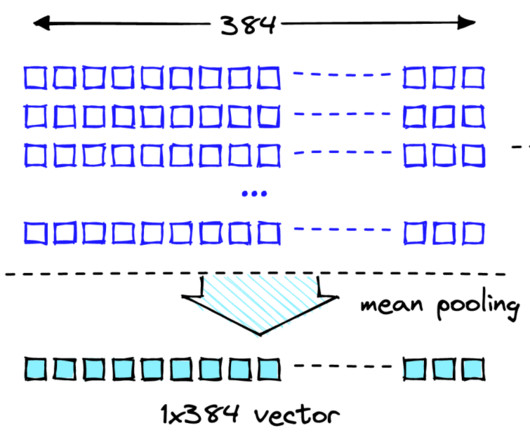
They don’t capture the full context of a document, making them less effective in dealing with unstructured data. Embeddings are generated by representational language models that translate text into numerical vectors and encode contextual information in a document. They provide ease of use and strong security and privacy controls.
This is done by creating a store of relevant knowledge, usually in the form of embeddings in a vector database, to supplement additional context for the LLM to consider when formulating a response. This could range from structured databases to unstructured data like blogs , news feeds, and more.
These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests. This approach allows for tailored responses and processes for different types of user needs, whether its a simple question, a document translation, or a complex inquiry about IDIADAs services.
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Text splitting is breaking down a long document or text into smaller, manageable segments or “chunks” for processing.
This code can cover a diverse array of tasks, such as creating a KMeans cluster, in which users input their data and ask ChatGPT to generate the relevant code. This is where the utilization of vector databases like Pinecone becomes valuable to store all the past experiences and aids as the memory for LLMs.
This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. You will create a connector to SageMaker with Amazon Titan Text Embeddings V2 to create embeddings for a set of documents with population statistics. Choose your domains dashboard.
This domain knowledge is traditionally captured in reference manuals, service bulletins, quality ticketing systems, engineering drawings, and more, but the quantity and complexity of documents is growing and takes time to learn. How can I trace the reasoning of my model back to source documents to build user trust?” “How
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content