This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. To do so, you can use a vector database. Retrieve images stored in S3 bucket response = s3.list_objects_v2(Bucket=BUCKET_NAME)
What is an online transaction processing database (OLTP)? But the true power of OLTP databases lies beyond the mere execution of transactions, and delving into their inner workings is to unravel a complex tapestry of data management, high-performance computing, and real-time responsiveness.
I’m writing a book on Retrieval Augmented Generation (RAG) for Wiley Publishing, and vector databases are an inescapable part of building a performant RAG system. I selected Qdrant as the vector database for my book and this series. Source: Author You’ll need to create your cluster and get your API key.
For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The user query is used to retrieve relevant additional context from the vector database. The retrieved context and the user query are used to augment a prompt template.
It is a cloud-native approach, and it suits a small team that does not want to host, maintain, and operate a Kubernetes cluster alonewith all the resulting responsibilities (and costs). The source data is unstructured JSON, while the target is a structured, relational database. Database size limits of 10GB.
In this blog post, we’ll explore how to deploy LLMs such as Llama-2 using Amazon Sagemaker JumpStart and keep our LLMs up to date with relevant information through Retrieval Augmented Generation (RAG) using the Pinecone vector database in order to prevent AI Hallucination. Sign up for a free-tier Pinecone Vector Database.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
In this post, we walk through step-by-step instructions to establish a cross-account connection to any Amazon Redshift node type (RA3, DC2, DS2) by connecting the Amazon Redshift cluster located in one AWS account to SageMaker Studio in another AWS account in the same Region using VPC peering.
Install Java and Download Kafka: Install Java on the EC2 instance and download the Kafka binary: 4. It communicates with the Cluster Manager to allocate resources and oversee task progress. SparkContext: Facilitates communication between the Driver program and the Spark Cluster.
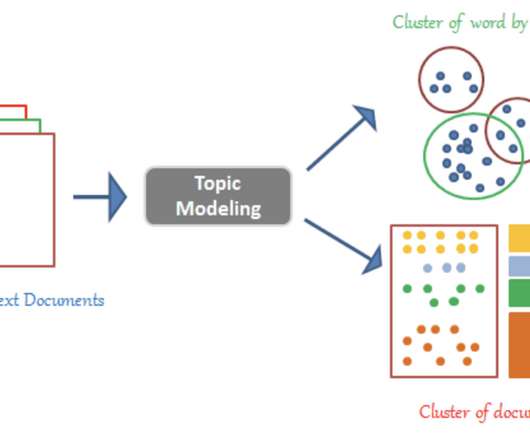
Latent Dirichlet Allocation (LDA) Topic Modeling LDA is a well-known unsupervised clustering method for text analysis. Then, the topic model applies a hierarchical clustering algorithm using conversation vectors from the output of the summary model. Collecting the dataset We collected the data from the Consumer complaint database.
For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas. This new feature enables you to perform various functions.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster. Finally, select your read preference.
This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. Complete the following steps: On the OpenSearch Service console, choose Dashboard under Managed clusters in the navigation pane. Choose your domains dashboard.
Download the free, unabridged version here. They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. Download the free, unabridged version here. Team How to determine the optimal team structure ?
What if you could automatically shard your PostgreSQL database across any number of servers and get industry-leading performance at scale without any special data modelling steps? You can shard your Citus database by creating a schema per tenant, as an alternative to distributing tables by a tenant ID column.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster.
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Enhanced Search and Retrieval Augmented Generation: Vector search systems work by matching queries with embeddings in a database.
The diverse and rich database of models brings unique challenges for choosing the most efficient deployment infrastructure that gives the best latency and performance. So far, we have migrated PyTorch and TensorFlow based Distil RoBerta-base, spaCy clustering, prophet, and xlmr models to Graviton3-based c7g instances.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. Claude 3 Sonnet is the next generation of state-of-the-art models from Anthropic.
If you don’t have a Spark environment set up in your Cloudera environment, you can easily set up a Dataproc cluster on Google Cloud Platform (GCP) or an EMR cluster on AWS to do hands-on on your own. Create a Dataproc Cluster: Click on Navigation Menu > Dataproc > Clusters. Click Create Cluster.
Unlike traditional databases, Elasticsearch is optimised for search-related tasks, making it a popular choice for companies with vast amounts of unstructured data. A cluster consists of multiple nodes. Cluster : A collection of nodes working together. Each cluster has a unique name and can scale by adding more nodes.
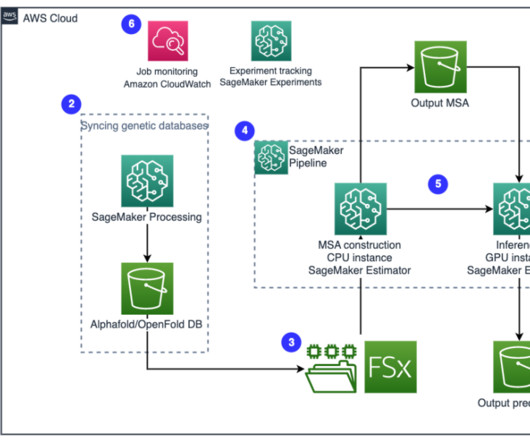
Genetic databases – A genetic database is one or more sets of genetic data stored together with software to enable users to retrieve genetic data. Several genetic databases are required to run AlphaFold and OpenFold algorithms, such as BFD , MGnify , PDB70 , PDB , PDB seqres , UniRef30 (FKA UniClust30) , UniProt , and UniRef90.
Download a free PDF by filling out the form. More on this topic later; but for now, keep in mind that the simplest method is to create a naming convention for database objects that allows you to identify the owner and associated budget. Want to save this guide for later? One day is usually adequate for development use.
Jump Right To The Downloads Section Face Recognition with Siamese Networks, Keras, and TensorFlow Deep learning models tend to develop a bias toward the data distribution on which they have been trained. Note that this entails a simple way multi-class classification problem for a database with personnel (here, persons or classes).
Summary: MySQL is a widely used open-source relational database management system known for its reliability and performance. Overview of MySQL MySQL is one of the most popular relational database management systems (RDBMS) in the world, widely used for managing and organizing data.
For example, when downloading files, hash values can verify that the file remains unchanged. Even if a database compromised, attackers cannot retrieve original passwords from hashes. This technique works well with numerical data but may not be suitable for all types of inputs or larger datasets due to potential clustering issues.
To get started, download the Anaconda installer from the official Anaconda website and follow the installation instructions for your operating system. Scikit-learn covers various classification , regression , clustering , and dimensionality reduction algorithms. Once Anaconda is installed, launch the Anaconda Navigator.
In the RAG-based approach we convert the user question into vector embeddings using an LLM and then do a similarity search for these embeddings in a pre-populated vector database holding the embeddings for the enterprise knowledge corpus. The notebook also ingests the data into another vector database called FAISS.
Since it’s open source, you can download it for free and host as many instances as you want without incurring license fees. You need to provide the necessary computing and database infrastructure, which someone has to set up and manage. However, hosting and operating an MLflow instance is not free. If you need the equivalent of an m5.large
Extract Data We will use Google Trends as a database to extract data, it is a public web-based tool that allows users to explore the popularity of search queries on Google. We have to create a database for the project: Figure 8: Creating a Dabase in pgAdmin4 Next, we have to write database’s name and save?. Windows NT 10.0;
Orchestration Tools: Kubernetes, Docker Swarm Purpose: Manages the deployment, scaling, and operation of application containers across clusters of hosts. ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch ✓ Easy one-click downloads for code, datasets, pre-trained models, etc. Download the code!
Users can download datasets in formats like CSV and ARFF. The publicly available repository offers datasets for various tasks, including classification, regression, clustering, and more. Clustering : Datasets that involve grouping data into clusters without predefined labels. CSV, ARFF) to begin the download.
How Snowflake Helps Achieve Real-Time Analytics Snowflake is the ideal platform to achieve real-time analytics for several reasons, but two of the biggest are its ability to manage concurrency due to the multi-cluster architecture of Snowflake and its robust connections to 3rd party tools like Kafka. p8 -pubout -out C:tmpnew_rsa_key_v1.pub
This architecture combines a general-purpose large language model (LLM) with a customer-specific document database, which is accessed through a semantic search engine. Because RAG uses a semantic search, it can find more relevant material in the database than just a keyword match alone. Choose Next. Choose Next.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. OpenSearch Service currently has tens of thousands of active customers with hundreds of thousands of clusters under management processing trillions of requests per month. Prerequisites.
Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters. Dolt Dolt is an open-source relational database system built on Git. The entire model can be downloaded to your source code’s runtime with a single line of code.
To understand this, imagine you have a pipeline that extracts weather information from an API, cleans the weather information, and loads it into a database. Airflow has four major components, which are The Scheduler The Worker A Database A web server The four major components work in sync to manage data pipelines in Apache Airflow.
The Lambda will download these previous predictions from Amazon S3. The notifications Lambda will get the information related to the prediction ID from DynamoDB, update the entry with status value to “completed” or “error,” and perform the necessary action depending on the callback mode saved in the database record.
Data can come from different sources, such as databases or directly from users, with additional sources, including platforms like GitHub, Notion, or S3 buckets. Vector Databases Vector databases help store unstructured data by storing the actual data and its vector representation. mp4,webm, etc.), and audio files (.wav,mp3,acc,
Typical unsupervised learning tasks include clustering (e.g., Data can be collected from various sources such as databases, APIs, web scraping, or sensors. Unsupervised Learning In unsupervised learning, the algorithm is fed an unlabelled dataset, and it attempts to discover hidden patterns or structures within the data.
Some of the Power BI visualisations you can create include clustered bar charts, common line charts, scatter charts, waterfall charts, pie charts, and treemap charts. You can click on this link to download the Power BI [link] Step 2: Connect to Data Once the installation is over, connect it to the data source in Power BI.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content