This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
What is an online transaction processing database (OLTP)? But the true power of OLTP databases lies beyond the mere execution of transactions, and delving into their inner workings is to unravel a complex tapestry of data management, high-performance computing, and real-time responsiveness.
From vCenter, administrators can configure and control ESXi hosts, datacenters, clusters, traditional storage, software-defined storage, traditional networking, software-defined networking, and all other aspects of the vSphere architecture. VMware “clustering” is purely for virtualization purposes.
By analysing existing single-cell RNA-sequencing databases and our patch-seq data, we identified nine molecularly distinct clusters of hippocampal astrocytes, among which we found a notable subpopulation that selectively expressed synaptic-like glutamate-release machinery and localized to discrete hippocampal sites.
Caching is performed on Amazon CloudFront for certain topics to ease the database load. Amazon Aurora PostgreSQL-Compatible Edition and pgvector Amazon Aurora PostgreSQL-Compatible is used as the database, both for the functionality of the application itself and as a vector store using pgvector.
In this post, we walk through step-by-step instructions to establish a cross-account connection to any Amazon Redshift node type (RA3, DC2, DS2) by connecting the Amazon Redshift cluster located in one AWS account to SageMaker Studio in another AWS account in the same Region using VPC peering.
The listing writer microservice publishes listing change events to an Amazon Simple Notification Service (Amazon SNS) topic, which an Amazon Simple Queue Service (Amazon SQS) queue subscribes to. The cluster comprises 3 cluster manager nodes (m6g.xlarge.search instance) dedicated to manage cluster operations.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. It can also be used for determining the optimal number of clusters.
Apache Kafka is a well-known open-source event store and stream processing platform and has grown to become the de facto standard for data streaming. A schema registry supports your Kafka cluster by providing a repository for managing and validating schemas within that cluster. What is a schema registry?
Its characteristics can be summarized as follows: Volume : Big Data involves datasets that are too large to be processed by traditional database management systems. databases), semi-structured data (e.g., Clusters : Clusters are groups of interconnected nodes that work together to process and store data.
Apache Kafka is an event streaming platform that collects, stores, and processes streams of data (events) in real-time and in an elastic, scalable, and fault-tolerant manner. Consumers read the events and process the data in real-time. The TensorFlow instance acts as a Kafka consumer to load new events into its memory.
Visualizing graph data doesn’t necessarily depend on a graph database… Working on a graph visualization project? You might assume that graph databases are the way to go – they have the word “graph” in them, after all. Do I need a graph database? It depends on your project. Unstructured? Under construction?
The implementation uses Slacks event subscription API to process incoming messages and Slacks Web API to send responses. The incoming event from Slack is sent to an endpoint in API Gateway, and Slack expects a response in less than 3 seconds, otherwise the request fails. Sonnet model for natural language processing.
MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. Make sure you have the following prerequisites: Create an S3 bucket Configure MongoDB Atlas cluster Create a free MongoDB Atlas cluster by following the instructions in Create a Cluster.
That’s why our data visualization SDKs are database agnostic: so you’re free to choose the right stack for your application. There have been a lot of new entrants and innovations in the graph database category, with some vendors slowly dipping below the radar, or always staying on the periphery. can handle many graph-type problems.
Apache Kafka Apache Kafka is a distributed event streaming platform used for building real-time data pipelines and streaming applications. It communicates with the Cluster Manager to allocate resources and oversee task progress. SparkContext: Facilitates communication between the Driver program and the Spark Cluster.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
Patrick Lewis “We definitely would have put more thought into the name had we known our work would become so widespread,” Lewis said in an interview from Singapore, where he was sharing his ideas with a regional conference of database developers. “We Retrieval-augmented generation combines LLMs with embedding models and vector databases.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster. Finally, select your read preference.
They are typically trained on clusters of computers or even on cloud computing platforms. LlamaIndex can be used to connect LLMs to a variety of data sources, including APIs, PDFs, documents, and SQL databases. Vector databases Vector databases are a type of database that is optimized for storing and querying vector data.
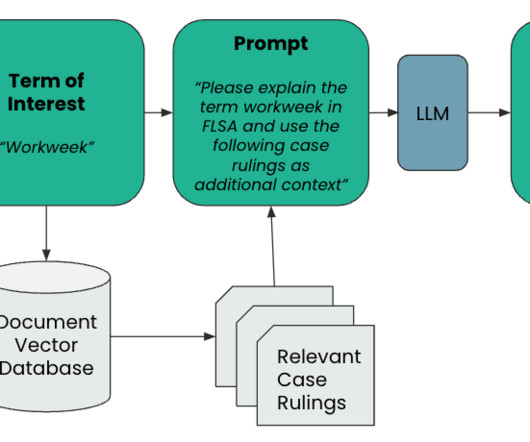
In other words, LLMs are not dynamic but rather static in nature, which prevents them from answering questions about recent events or information. This is done by creating a store of relevant knowledge, usually in the form of embeddings in a vector database, to supplement additional context for the LLM to consider when formulating a response.
We have contributed semantic conventions for database servers and provided the open source OpenTelemetry Database Data Collector, expanding OpenTelemetry and Instana’s support for monitoring database servers. We extended our coverage and currently, Instana supports SAP BTP Kyma cluster monitoring.
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. To retrieve data from database, you can use foundation models (FMs) offered by Amazon Bedrock, converting text into SQL queries with specified constraints.
It was built using a combination of in-house and external cloud services on Microsoft Azure for large language models (LLMs), Pinecone for vectorized databases, and Amazon Elastic Compute Cloud (Amazon EC2) for embeddings. This event-driven architecture provides immediate processing of new documents.
This process comprises two key components: event data and optical tracking data. Event data collection entails gathering the fundamental building blocks of the game. For the precision needed in shot speed calculations, we must ensure that the ball’s position aligns precisely with the moment of the event.
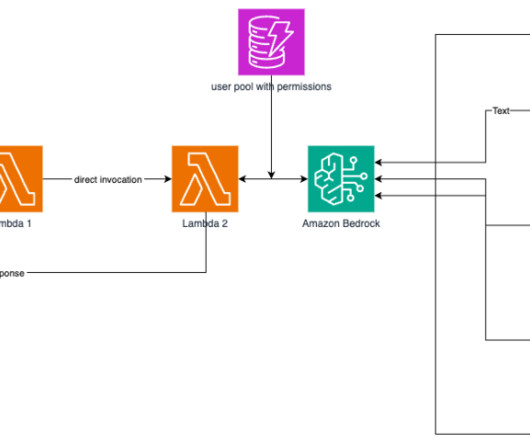
In this post, we describe how CBRE partnered with AWS Prototyping to develop a custom query environment allowing natural language query (NLQ) prompts by using Amazon Bedrock, AWS Lambda , Amazon Relational Database Service (Amazon RDS), and Amazon OpenSearch Service. A user sends a question (NLQ) as a JSON event.
The idea is to build computer programs that sift through databases automatically, seeking regularities or patterns. It is used to extract information from the raw data in databases… “ Overview. The unusual data points may point to a problem or rare event that can be subject to further investigation. Clustering.
Unlike traditional databases, Elasticsearch is optimised for search-related tasks, making it a popular choice for companies with vast amounts of unstructured data. A cluster consists of multiple nodes. Cluster : A collection of nodes working together. Each cluster has a unique name and can scale by adding more nodes.
Vary Real-world Events Real-world systems are subjected to a myriad of unpredictable events. These can range from spikes in traffic to the sudden loss of a database. To ensure our systems remain resilient amidst this flux, our chaos experiments must be a recurring event. Once identified, simulate them.
Classification is similar to clustering in a way that it also segments data records into different segments called classes. But unlike clustering, here the data analysts would have the knowledge of different classes or cluster. It is used to classify different data in different classes.
Apache Kafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. Apache’s architecture is made up of three categories—events, producers and consumers—and it relies heavily on application programming interfaces (APIs) to function.
The latest GPT4 model by OpenAI has knowledge only till April 2023 and any event that happened post that date, the information is not available to the model. Vectors are typically stored in Vector Databases which are best suited for searching. For this we use a special kind of database called the Vector Database.
Summary: Apache Cassandra and MongoDB are leading NoSQL databases with unique strengths. Introduction In the realm of database management systems, two prominent players have emerged in the NoSQL landscape: Apache Cassandra and MongoDB. MongoDB is another leading NoSQL database that operates on a document-oriented model.
Summary: MySQL is a widely used open-source relational database management system known for its reliability and performance. Overview of MySQL MySQL is one of the most popular relational database management systems (RDBMS) in the world, widely used for managing and organizing data.
AI computers are redefining how we think about computing Availability In the event of a failure in any of the machines within your distributed computing system, the overall functionality of the system will not be compromised. Each machine within the cluster is programmed to execute the same set of operations.
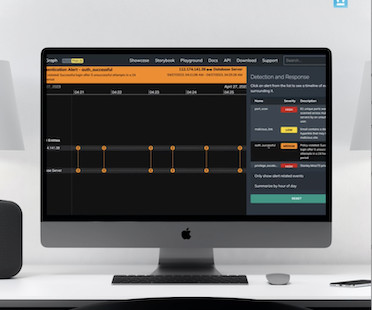
But instead of seeing the standard pie chart, a table of log files and some flashing IP addresses, you see this: A cyber security dashboard guaranteed to combat alert fatigue The KronoGraph timeline view displays millions of events in a single interactive visualization. We hover over these alerts to see the events which triggered them.
It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a data warehouse or a database. The company can use the Pub/Sub pattern to process customer events such as product views, add to cart, and checkout.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a data lake: a large and complex database of diverse datasets all stored in their original format.
They investigate these patterns and use them to predict – and, if possible, prevent – future events. Filtering by time updates the network chart automatically to show only relevant nodes It’ll be much easier to spot the location of events like the Tōhuko earthquake on a map, so let’s switch to map mode.
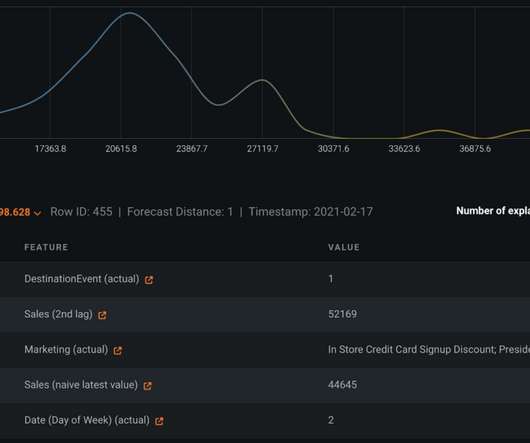
To understand how DataRobot AI Cloud and Big Query can align, let’s explore how DataRobot AI Cloud Time Series capabilities help enterprises with three specific areas: segmented modeling, clustering, and explainability. Enable Granular Forecasts with Clustering. This is where clustering comes in.
Scikit-learn covers various classification , regression , clustering , and dimensionality reduction algorithms. Engaging in these events fosters community, providing support and motivation as you advance your Python journey for Data Science. Scikit-learn Scikit-learn is the go-to library for Machine Learning in Python.
The Data Instana monitors 100% of every call trace, maintaining information about the infrastructure and application for API calls, database queries, messaging and much more. The Method Using causal AI, we can identify root causes of application-impacting faults by joining disparate data sources, such as calls, metrics, events and topology.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content