This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the rapidly evolving technological world, businesses are constantly contemplating the debate of traditional vs vector databases. Hence, databases are important for strategic data handling and enhanced operational efficiency. Hence, databases are important for strategic data handling and enhanced operational efficiency.
Traditional hea l t h c a r e databases struggle to grasp the complex relationships between patients and their clinical histories. Vector databases are revolutionizing healthcare data management. Unlike traditional, table-like structures, they excel at handling the intricate, multi-dimensional nature of patient information.
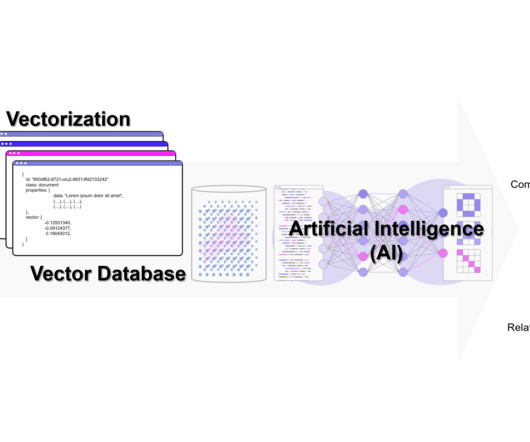
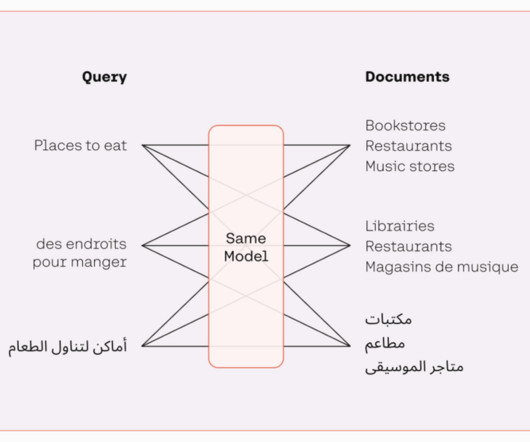
A vector database is a type of database that stores data as high-dimensional vectors. One way to think about a vector database is as a way of storing and organizing data that is similar to how the human brain stores and organizes memories. Pinecone is a vector database that is designed for machine learning applications.
der k-Nächste-Nachbarn -Prädiktionsalgorithmus (Regression/Klassifikation) oder K-Means-Clustering. Die Texte müssen in diese transformiert werden, eventuell auch nach diesen in Cluster eingeteilt und für verschiedene Trainingsszenarien separiert werden. Die Ähnlichkeitsbetrachtung erfolgt mit Distanzmessung im Vektorraum.
It is an AI framework and a type of naturallanguageprocessing (NLP) model that enables the retrieval of information from an external knowledge base. It integrates retrieval-based and generation-based approaches to provide a robust database for LLMs. Language translation Translation is a tricky process.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Its vector data store seamlessly integrates with operational data storage, eliminating the need for a separate database.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The user query is used to retrieve relevant additional context from the vector database. The user receives a more accurate response based on their query.
Transformers are a type of neural network that are well-suited for naturallanguageprocessing tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language. They are typically trained on clusters of computers or even on cloud computing platforms.
Databases are the unsung heroes of AI Furthermore, data archiving improves the performance of applications and databases. By removing infrequently accessed data from primary storage systems, organizations can improve the performance of their applications and databases, which can lead to increased productivity and efficiency.
Vector Databases 101: A Beginners Guide to Vector Search and Indexing Photo by Google DeepMind on Unsplash Introduction Alright, folks! The secret sauce behind all of this is vector search and vector databases, helping power similarity-based recommendations and retrieval! Traditional databases? They tap out.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. It can also be used for determining the optimal number of clusters.
The algorithm learns to find patterns or structure in the data by clustering similar data points together. WHAT IS CLUSTERING? Clustering is an unsupervised machine learning technique that is used to group similar entities. Those groups are referred to as clusters.
Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step. Amazon Redshift Serverless cluster. There is no need to set up and manage clusters. The CloudFormation script created a database called sagemaker. Let’s populate this database with tables for the RStudio user to query.
In this blog post, we’ll explore how to deploy LLMs such as Llama-2 using Amazon Sagemaker JumpStart and keep our LLMs up to date with relevant information through Retrieval Augmented Generation (RAG) using the Pinecone vector database in order to prevent AI Hallucination. Sign up for a free-tier Pinecone Vector Database.
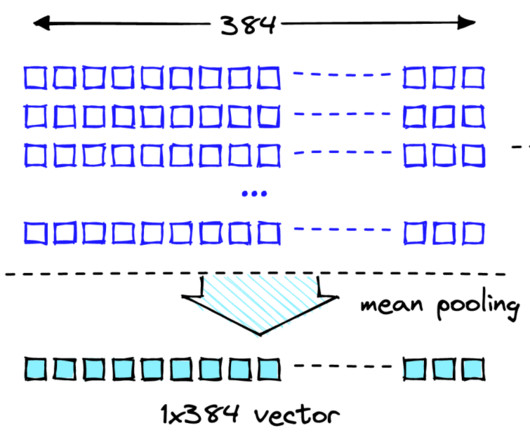
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. The example matches a user’s query to the closest entries in an in-memory vector database.
In our previous article on Retrieval Augmented Generation (RAG), we discussed the need for a Vector Database to retrieve additional information for our prompts. Today, we will dive into the inner workings of a Vector Database to better understand exactly how this technology functions. What is a Vector Database in Simple Terms?
Patrick Lewis “We definitely would have put more thought into the name had we known our work would become so widespread,” Lewis said in an interview from Singapore, where he was sharing his ideas with a regional conference of database developers. “We Retrieval-augmented generation combines LLMs with embedding models and vector databases.
The diverse and rich database of models brings unique challenges for choosing the most efficient deployment infrastructure that gives the best latency and performance. In our test environment, we observed 20% throughput improvement and 30% latency reduction across multiple naturallanguageprocessing models.
And retailers frequently leverage data from chatbots and virtual assistants, in concert with ML and naturallanguageprocessing (NLP) technology, to automate users’ shopping experiences. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
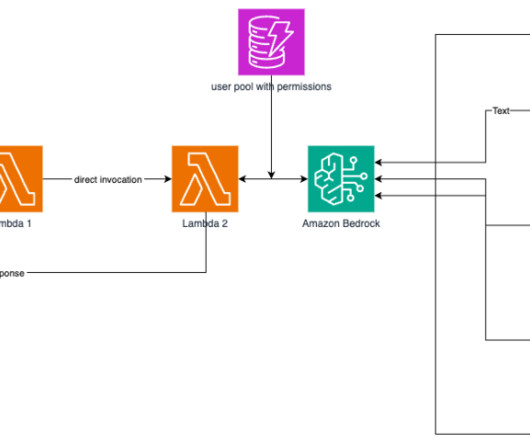
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. This same interface is also used for provisioning EMR clusters. The following diagram illustrates this solution.
Embeddings capture the information content in bodies of text, allowing naturallanguageprocessing (NLP) models to work with language in a numeric form. In this pattern, the recipe text is converted into embedding vectors using an embedding model, and stored in a vector database.
Solving Machine Learning Tasks with MLCoPilot: Harnessing Human Expertise for Success Many of us have made use of large language models (LLMs) like ChatGPT to generate not only text and images but also code, including machine learning code. Vector databases can store them and are designed for search and data mining.
It was built using a combination of in-house and external cloud services on Microsoft Azure for large language models (LLMs), Pinecone for vectorized databases, and Amazon Elastic Compute Cloud (Amazon EC2) for embeddings. Amazon Bedrock Guardrails implements content filtering and safety checks as part of the query processing pipeline.
Using RStudio on SageMaker and Amazon EMR together, you can continue to use the RStudio IDE for analysis and development, while using Amazon EMR managed clusters for larger data processing. In this post, we demonstrate how you can connect your RStudio on SageMaker domain with an EMR cluster. Choose Create stack.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas. This new feature enables you to perform various functions.
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Text splitting is breaking down a long document or text into smaller, manageable segments or “chunks” for processing.
Sonnet model for naturallanguageprocessing. Additionally, if a user tells the assistant something that should be remembered, we store this piece of information in a database and add it to the context every time the user initiates a request.
This is an open source dataset curated for financial naturallanguageprocessing (NLP) and is available on a GitHub repository. You don’t have to change to a vector database or make drastic changes to your infrastructure, and it only takes a few lines of code. Rerank is available in Amazon SageMaker.
The idea is to build computer programs that sift through databases automatically, seeking regularities or patterns. It is used to extract information from the raw data in databases… “ Overview. Clustering. For example, clustering is used to group a large set of documents into categories based on the content.
Unsupervised Learning Algorithms Unsupervised Learning Algorithms tend to perform more complex processing tasks in comparison to supervised learning. However, unsupervised learning can be highly unpredictable compared to natural learning methods. K-Means Clustering: K-means is a popular and widely used clustering algorithm.
With advances in machine learning, deep learning, and naturallanguageprocessing, the possibilities of what we can create with AI are limitless. However, the process of creating AI can seem daunting to those who are unfamiliar with the technicalities involved. What is required to build an AI system?
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. Claude 3 Sonnet is the next generation of state-of-the-art models from Anthropic.
RAG provides additional knowledge to the LLM through its input prompt space and its architecture typically consists of the following components: Indexing : Prepare a corpus of unstructured text, parse and chunk it, and then, embed each chunk and store it in a vector database.
Leveraging distributed storage and processing frameworks such as Apache Hadoop, Spark or Dask accelerates data ingestion, transformation and analysis. Additionally, using in-memory databases and caching mechanisms minimizes latency and improves data access speeds.
They bring deep expertise in machine learning , clustering , naturallanguageprocessing , time series modelling , optimisation , hypothesis testing and deep learning to the team. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data.
A RAG system uses a vector database to serve as a knowledge retriever. It must extract a query from a user’s prompt and send it to a vector database to reliably find as much semantic information as possible. A smaller vector size means a great amount of cost savings while storing them in a vector database.
He has deep ML experience in speech recognition, translation, naturallanguageprocessing, and advertising, and has published over 30 papers in these areas. Dustin Hillard is responsible for leading product development and technology innovation, systems teams, and corporate IT at eSentire.
We use Knowledge Bases for Amazon Bedrock to fetch from historical data stored as embeddings in the Amazon OpenSearch Service vector database. You can use Fargate with Amazon ECS to run containers without having to manage servers, clusters, or virtual machines. The vectorization process is implemented in code.
Deep Learning has been used to achieve state-of-the-art results in a variety of tasks, including image recognition, NaturalLanguageProcessing, and speech recognition. NaturalLanguageProcessing (NLP) This is a field of computer science that deals with the interaction between computers and human language.
A database that help index and search at blazing speed. Relational databases (like MySQL) or No-SQL databases (AWS DynamoDB) can store structured or even semi-structured data but there is one inherent problem. Unstructured data is hard to store in relational databases.
In the RAG-based approach we convert the user question into vector embeddings using an LLM and then do a similarity search for these embeddings in a pre-populated vector database holding the embeddings for the enterprise knowledge corpus. The notebook also ingests the data into another vector database called FAISS.
Processing frameworks like Hadoop enable efficient data analysis across clusters. This massive influx of data necessitates robust storage solutions and processing capabilities. This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos).
Processing frameworks like Hadoop enable efficient data analysis across clusters. This massive influx of data necessitates robust storage solutions and processing capabilities. This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content