This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the rapidly evolving technological world, businesses are constantly contemplating the debate of traditional vs vector databases. Hence, databases are important for strategic data handling and enhanced operational efficiency. Hence, databases are important for strategic data handling and enhanced operational efficiency.
Introduction Dedicated SQL pools offer fast and reliable data import and analysis, allowing businesses to access accurate insights while optimizing performance and reducing costs. A clustered column store index is created on a table with a clustered column store architecture.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
The package is particularly well-suited for working with tabular data, such as spreadsheets or SQL tables, and provides powerful data cleaning, transformation, and wrangling capabilities. It provides a wide range of tools for supervised and unsupervised learning, including linear regression, k-means clustering, and support vector machines.
Introduction Amazon’s Redshift Database is a cloud-based large data warehousing solution. Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system. This article was published as a part of the Data Science Blogathon.
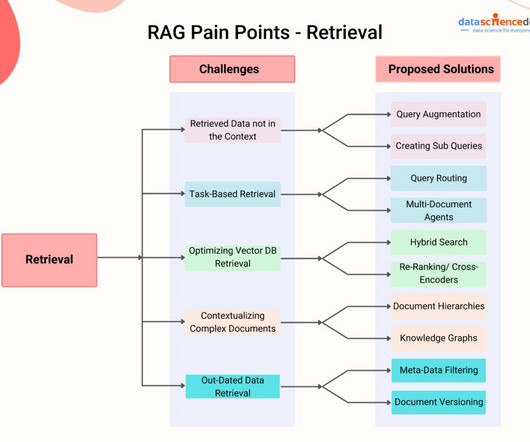
Retrieval Augmented Generation generally consists of Three major steps, I will explain them briefly down below – Information Retrieval The very first step involves retrieving relevant information from a knowledge base, database, or vector database, where we store the embeddings of the data from which we will retrieve information.
They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference. Previously, data scientists often found themselves juggling multiple tools to support SQL in their workflow, which hindered productivity.
For this post we’ll use a provisioned Amazon Redshift cluster. Basic knowledge of a SQL query editor. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Database name : Enter dev. Database user : Enter awsuser. A SageMaker domain.
What is an online transaction processing database (OLTP)? But the true power of OLTP databases lies beyond the mere execution of transactions, and delving into their inner workings is to unravel a complex tapestry of data management, high-performance computing, and real-time responsiveness.
Items in your shopping carts, comments on all your posts, and changing scores in a video game are examples of information stored somewhere in a database. Which begs the question what is a database? Types of Databases: There are many different types of databases. The tables store data in the form of rows and columns.
From vCenter, administrators can configure and control ESXi hosts, datacenters, clusters, traditional storage, software-defined storage, traditional networking, software-defined networking, and all other aspects of the vSphere architecture. VMware “clustering” is purely for virtualization purposes.
In this post, we provide an overview of the Meta Llama 3 models available on AWS at the time of writing, and share best practices on developing Text-to-SQL use cases using Meta Llama 3 models. Training involved a dataset of over 15 trillion tokens across two GPU clusters, significantly more than Meta Llama 2.
Amidst the buzz surrounding big data technologies, one thing remains constant: the use of Relational Database Management Systems (RDBMS). Likewise, in big data, relational databases serve as the bedrock upon which the data infrastructure stands. Relational databases emerge as the solution, bringing order to the data deluge.
Caching is performed on Amazon CloudFront for certain topics to ease the database load. Amazon Aurora PostgreSQL-Compatible Edition and pgvector Amazon Aurora PostgreSQL-Compatible is used as the database, both for the functionality of the application itself and as a vector store using pgvector. Its hosted on AWS Lambda.
It is a cloud-native approach, and it suits a small team that does not want to host, maintain, and operate a Kubernetes cluster alonewith all the resulting responsibilities (and costs). The source data is unstructured JSON, while the target is a structured, relational database. Database size limits of 10GB.
Java is 1000 times faster than today’s database systems. While programming languages like Java offer microsecond processing speeds, external database servers that have been utilized for data processing over the past 40 years, are 1000 times slower with millisecond processing speeds.
In this post, we walk through step-by-step instructions to establish a cross-account connection to any Amazon Redshift node type (RA3, DC2, DS2) by connecting the Amazon Redshift cluster located in one AWS account to SageMaker Studio in another AWS account in the same Region using VPC peering.
It communicates with the Cluster Manager to allocate resources and oversee task progress. SparkContext: Facilitates communication between the Driver program and the Spark Cluster. Cluster Manager: Responsible for resource allocation and monitoring Spark applications during execution.
In this post, we describe how CBRE partnered with AWS Prototyping to develop a custom query environment allowing natural language query (NLQ) prompts by using Amazon Bedrock, AWS Lambda , Amazon Relational Database Service (Amazon RDS), and Amazon OpenSearch Service. The wrapper function runs the SQL query using psycopg2.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
Its characteristics can be summarized as follows: Volume : Big Data involves datasets that are too large to be processed by traditional database management systems. databases), semi-structured data (e.g., Clusters : Clusters are groups of interconnected nodes that work together to process and store data.
With Instana, you enjoy automated full-stack monitoring, from application performance to infrastructure, microservices, Kubernetes, databases, APIs, and beyond. SQL traces SQL tracing is not natively supported by SAP BTP Kyma. However, Instana can support SQL tracing.
It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step. Amazon Redshift Serverless cluster. There is no need to set up and manage clusters.
Database Proliferation Years ago, I wrote that NoSQL wasn’t a database technology; it was a movement. It was a movement that affirmed the development and use of database architectures other than the relational database. There has been a proliferation of time series and graph databases.
Visualizing graph data doesn’t necessarily depend on a graph database… Working on a graph visualization project? You might assume that graph databases are the way to go – they have the word “graph” in them, after all. Do I need a graph database? It depends on your project. Unstructured? Under construction?
Unlike the old days where data was readily stored and available from a single database and data scientists only needed to learn a few programming languages, data has grown with technology. Understand the Databases. As a data engineer, you will be primarily working on databases. Just like programming, SQL has multiple dialects.
Data warehouse, also known as a decision support database, refers to a central repository, which holds information derived from one or more data sources, such as transactional systems and relational databases. They have undergone significant transformation since then, with modern warehouses housing largescale terabyte capacities.
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. To retrieve data from database, you can use foundation models (FMs) offered by Amazon Bedrock, converting text into SQL queries with specified constraints.
That’s why our data visualization SDKs are database agnostic: so you’re free to choose the right stack for your application. There have been a lot of new entrants and innovations in the graph database category, with some vendors slowly dipping below the radar, or always staying on the periphery. can handle many graph-type problems.
Data is loaded into the Hadoop Distributed File System (HDFS) and stored on the many computer nodes of a Hadoop cluster in deployments based on the distributed processing architecture. Some NoSQL databases are also utilized as platforms for data lakes. To preserve your digital assets, data must lastly be secured.
In our previous article on Retrieval Augmented Generation (RAG), we discussed the need for a Vector Database to retrieve additional information for our prompts. Today, we will dive into the inner workings of a Vector Database to better understand exactly how this technology functions. What is a Vector Database in Simple Terms?
Usually, the ingestion stage consists of the following steps: Collect data Chunk data Generate vector embeddings of chunks Store vector embeddings and chunks in a vector database The efficiency and effectiveness of the data ingestion phase significantly influence the overall performance of the system.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
What if you could automatically shard your PostgreSQL database across any number of servers and get industry-leading performance at scale without any special data modelling steps? If you skip one of these steps, performance might be poor due to network overhead, or you might run into distributed SQL limitations.
This tool can be great for handing SQL queries and other data queries. Several or more cubes are used to separate OLAP databases. The consolidated totals are saved in a data model in the HOLAP technique, while the particular data is maintained in a relational database. With OLAP, finding clusters and anomalies is simple.
We use Knowledge Bases for Amazon Bedrock to fetch from historical data stored as embeddings in the Amazon OpenSearch Service vector database. You can use Fargate with Amazon ECS to run containers without having to manage servers, clusters, or virtual machines. For example, “What are the max metrics for device 1009?”
Software businesses are using Hadoop clusters on a more regular basis now. NoSQL and SQL. In addressing storage needs, traditional databases like Oracle are being replaced. Developers need an understanding of MongoDB, Couchbase, and other NoSQL database types. Apache Spark. Quantitative Analysis.
Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. AWS Athena is a query service that allows users to analyze data in S3 using standard SQL syntax. Both combined, you use SQL to query what’s stored in S3. There are a lot of benefits of data scalability.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster.
It was built using a combination of in-house and external cloud services on Microsoft Azure for large language models (LLMs), Pinecone for vectorized databases, and Amazon Elastic Compute Cloud (Amazon EC2) for embeddings. Opportunities for innovation CreditAI by Octus version 1.x x uses Retrieval Augmented Generation (RAG).
This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. This allowed them to focus on SQL-based query optimization to the nth degree. They stood up a file-based data lake alongside their analytical database.
They are typically trained on clusters of computers or even on cloud computing platforms. LlamaIndex can be used to connect LLMs to a variety of data sources, including APIs, PDFs, documents, and SQLdatabases. Vector databases Vector databases are a type of database that is optimized for storing and querying vector data.
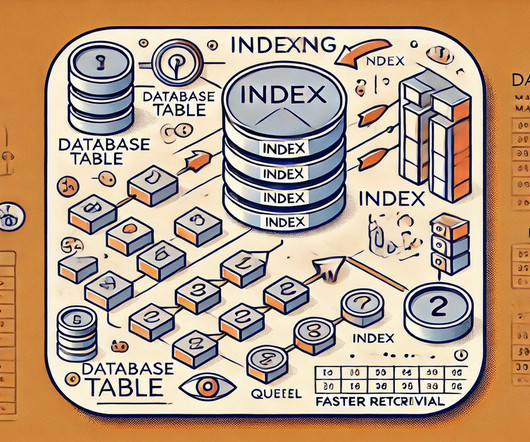
Introduction A Database Management System (DBMS) is essential for efficiently storing, managing, and retrieving application data. As databases grow, performance optimisation becomes critical to ensure quick access to information. One of the most effective techniques for enhancing database performance is indexing in DBMS.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content