This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
decisiontrees, support vector regression) that can model even more intricate relationships between features and the target variable. DecisionTrees: These work by asking a series of yes/no questions based on data features to classify data points. A significant drop suggests that feature is important. shirt, pants).
Classification Classification techniques, including decisiontrees, categorize data into predefined classes. ClusteringClustering groups similar data points based on their attributes. One common example is k-means clustering, which segments data into distinct groups for analysis.
Deeplearning models are typically highly complex. While many traditional machine learning models make do with just a couple of hundreds of parameters, deeplearning models have millions or billions of parameters. The reasons for this range from wrongly connected model components to misconfigured optimizers.
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and DecisionTrees. Introduction Machine Learning has revolutionized how we process and analyse data, enabling systems to learn patterns and make predictions.
AI-generated image ( craiyon ) [link] Who By Prior And who by prior, who by Bayesian Who in the pipeline, who in the cloud again Who by high dimension, who by decisiontree Who in your many-many weights of net Who by very slow convergence And who shall I say is boosting? I think I managed to get most of the ML players in there…??
Machine learning algorithms Machine learning forms the core of Applied Data Science. It leverages algorithms to parse data, learn from it, and make predictions or decisions without being explicitly programmed. DeeplearningDeeplearning, a subset of machine learning, has been a game-changer in lots of industries.
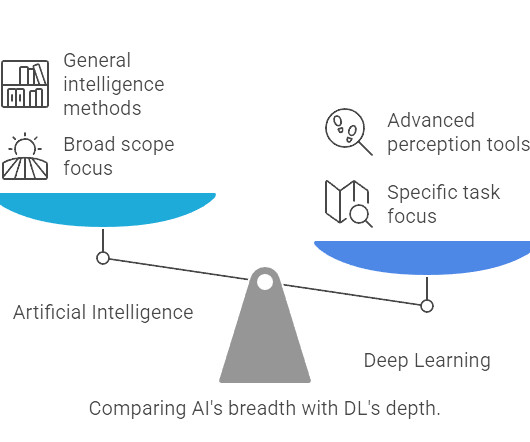
Summary: Artificial Intelligence (AI) and DeepLearning (DL) are often confused. AI vs DeepLearning is a common topic of discussion, as AI encompasses broader intelligent systems, while DL is a subset focused on neural networks. Is DeepLearning just another name for AI? Is all AI DeepLearning?
Summary: Machine Learning and DeepLearning are AI subsets with distinct applications. Introduction In todays world of AI, both Machine Learning (ML) and DeepLearning (DL) are transforming industries, yet many confuse the two. Clustering and anomaly detection are examples of unsupervised learning tasks.
They’re also part of a family of generative learning algorithms that model the input distribution of a given class or/category. Naïve Bayes algorithms include decisiontrees , which can actually accommodate both regression and classification algorithms.
Most generative AI models start with a foundation model , a type of deeplearning model that “learns” to generate statistically probable outputs when prompted. Decisiontrees implement a divide-and-conquer splitting strategy for optimal classification.
After trillions of linear algebra computations, it can take a new picture and segment it into clusters. Deeplearning multiple– layer artificial neural networks are the basis of deeplearning, a subdivision of machine learning (hence the word “deep”). GIS Random Forest script.
A sector that is currently being influenced by machine learning is the geospatial sector, through well-crafted algorithms that improve data analysis through mapping techniques such as image classification, object detection, spatial clustering, and predictive modeling, revolutionizing how we understand and interact with geographic information.
The feature space reduction is performed by aggregating clusters of features of balanced size. This clustering is usually performed using hierarchical clustering. Tree-based algorithms The tree-based methods aim at repeatedly dividing the label space in order to reduce the search space during the prediction.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deeplearning. TensorFlow and Keras: TensorFlow is an open-source platform for machine learning.
The model learns to map input features to the correct output by minimizing the error between its predictions and the actual target values. Examples of supervised learning models include linear regression, decisiontrees, support vector machines, and neural networks. regression, classification, clustering).
By leveraging techniques like machine learning and deeplearning, IoT devices can identify trends, anomalies, and patterns within the data. Supervised learning algorithms, like decisiontrees, support vector machines, or neural networks, enable IoT devices to learn from historical data and make accurate predictions.
In the first part of our Anomaly Detection 101 series, we learned the fundamentals of Anomaly Detection and saw how spectral clustering can be used for credit card fraud detection. On Lines 21-27 , we define a Node class, which represents a node in a decisiontree. We first start by defining the Node of an iTree.
Unsupervised learning Unsupervised learning techniques do not require labeled data and can handle more complex data sets. Unsupervised learning is powered by deeplearning and neural networks or auto encoders that mimic the way biological neurons signal to each other.
In contrast, decisiontrees assume data can be split into homogeneous groups through feature thresholds. Inductive bias is crucial in ensuring that Machine Learning models can learn efficiently and make reliable predictions even with limited information by guiding how they make assumptions about the data.
You’ll get hands-on practice with unsupervised learning techniques, such as K-Means clustering, and classification algorithms like decisiontrees and random forest. Finally, you’ll explore how to handle missing values and training and validating your models using PySpark.
Some common algorithms include: Random Forest : This ensemble learning algorithm is effective for classification tasks. Clustering can help in identifying patterns and anomalies within specific groups What are the best machine learning tools to analyze network traffic? All too long to do?
UnSupervised Learning Unlike Supervised Learning, unSupervised Learning works with unlabeled data. Clustering and dimensionality reduction are common tasks in unSupervised Learning. For example, clustering algorithms can group customers by purchasing behaviour, even if the group labels are not predefined.
With advances in machine learning, deeplearning, and natural language processing, the possibilities of what we can create with AI are limitless. Develop AI models using machine learning or deeplearning algorithms. Machine learning and deeplearning algorithms are commonly used in AI development.
Boosting: An ensemble learning technique that combines multiple weak models to create a strong predictive model. C Classification: A supervised Machine Learning task that assigns data points to predefined categories or classes based on their characteristics.
Sentence transformers are powerful deeplearning models that convert sentences into high-quality, fixed-length embeddings, capturing their semantic meaning. These embeddings are useful for various natural language processing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval.
There are majorly two categories of sampling techniques based on the usage of statistics, they are: Probability Sampling techniques: Clustered sampling, Simple random sampling, and Stratified sampling. Decisiontrees are more prone to overfitting. Some algorithms that have low bias are DecisionTrees, SVM, etc.
Without linear algebra, understanding the mechanics of DeepLearning and optimisation would be nearly impossible. The most popular supervised learning algorithms are: Linear Regression Linear regression predicts a continuous value by establishing a linear relationship between input features and the output.
Versatility: From classification to regression, Scikit-Learn Cheat Sheet covers a wide range of Machine Learning tasks. DecisionTree) Making Predictions Evaluating Model Accuracy (Classification) Feature Scaling (Standardization) Getting Started Before diving into the intricacies of Scikit-Learn, let’s start with the basics.
Traditional Machine Learning and DeepLearning methods are used to solve Multiclass Classification problems, but the model’s complexity increases as the number of classes increases. Particularly in DeepLearning, the network size increases as the number of classes increases.
Density-Based Spatial Clustering of Applications with Noise (DBSCAN): DBSCAN is a density-based clustering algorithm. It identifies regions of high data point density as clusters and flags points with low densities as anomalies. Points that don’t belong to any cluster or are in low-density regions are considered anomalies.
Machine Learning As machine learning is one of the most notable disciplines under data science, most employers are looking to build a team to work on ML fundamentals like algorithms, automation, and so on. DeepLearningDeeplearning is a cornerstone of modern AI, and its applications are expanding rapidly.
Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers. Students should learn how to train and evaluate models using large datasets. Students should learn about neural networks and their architecture.
Balanced Dataset Creation Balanced Dataset Creation refers to active learning's ability to select samples that ensure proper representation across different classes and scenarios, especially in cases of imbalanced data distribution. Pool-Based Active Learning Scenario : Classifying images of artwork styles for a digital archive.
Machine Learning Algorithms Candidates should demonstrate proficiency in a variety of Machine Learning algorithms, including linear regression, logistic regression, decisiontrees, random forests, support vector machines, and neural networks. What is the Central Limit Theorem, and why is it important in statistics?
AI, particularly Machine Learning and DeepLearning uses these insights to develop intelligent models that can predict outcomes, automate processes, and adapt to new information. DeepLearning: Advanced neural networks drive DeepLearning , allowing AI to process vast amounts of data and recognise complex patterns.
Moving the machine learning models to production is tough, especially the larger deeplearning models as it involves a lot of processes starting from data ingestion to deployment and monitoring. It provides different features for building as well as deploying various deeplearning-based solutions. What is MLOps?
Contextual Learning - With their deeplearning architecture, LLMs can grasp the nuances of language, including idioms, cultural references and complex syntax. This is important for real-time decision-making tasks, like autonomous vehicles or high-frequency trading. High efficiency in specific, well-defined problem spaces.
Then, I would use clustering techniques such as k-means or hierarchical clustering to group customers based on similarities in their purchasing behaviour. What are the advantages and disadvantages of decisiontrees ? Are there any areas in data analytics where you want to improve or learn more?
For instance, understanding the distribution of MonthlyCharges and TotalCharges can help in pricing strategy decisions. Are there clusters of customers with different spending patterns? #3. Random Forest Classifier (rf): Ensemble method combining multiple decisiontrees. We pay our contributors, and we don’t sell ads.
Source: [link] Weights and Biases Weights and biases are the key components of the deeplearning architectures that affect the model performance. LIME can help improve model transparency, build trust, and ensure that models make fair and unbiased decisions by identifying the key features that are more relevant in prediction-making.
Common algorithms used in classification tasks include: DecisionTrees: A tree-like model that makes decisions based on feature values. Random Forests: An ensemble of decisiontrees, improving accuracy through voting mechanisms.
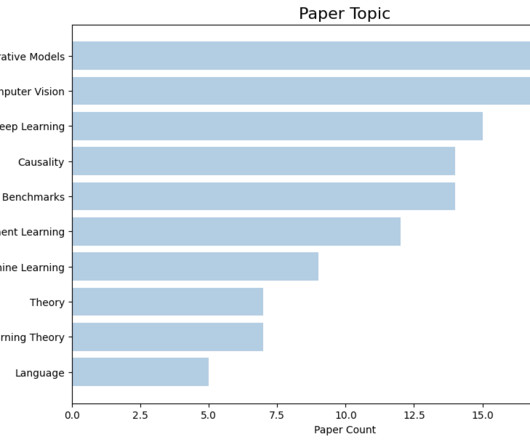
Here is a quick overview of the areas our researchers are working on: Here are some of our top collaborator institutions: Table of Contents Oral Papers Spotlight Papers Poster Papers Causality Computational Biology Computer Vision Computer Vision (Image Generation) Computer Vision (Video Generation) Computer Vision (Video Understanding) Data-centric (..)
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content