This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Zheng’s “Guide to Data Structures and Algorithms” Parts 1 and Part 2 1) Big O Notation 2) Search 3) Sort 3)–i)–Quicksort 3)–ii–Mergesort 4) Stack 5) Queue 6) Array 7) Hash Table 8) Graph 9) Tree (e.g.,
decisiontrees, supportvector regression) that can model even more intricate relationships between features and the target variable. SupportVectorMachines (SVM): This algorithm finds a hyperplane that best separates data points of different classes in high-dimensional space. shirt, pants).
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. Key examples include Linear Regression for predicting prices, Logistic Regression for classification tasks, and DecisionTrees for decision-making. DecisionTrees visualize decision-making processes for better understanding.
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and DecisionTrees. Introduction Machine Learning has revolutionized how we process and analyse data, enabling systems to learn patterns and make predictions.
It identifies hidden patterns in data, making it useful for decision-making across industries. Compared to decisiontrees and SVM, it provides interpretable rules but can be computationally intensive. RapidMiner supports various data mining operations, including classification, clustering, and association rule mining.
Supervised machine learning algorithms, such as linear regression and decisiontrees, are fundamental models that underpin predictive modeling. Unsupervised learning models, like clustering and dimensionality reduction, aid in uncovering hidden structures within data.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. What is Classification? Hence, the assumption causes a problem.
In data mining, popular algorithms include decisiontrees, supportvectormachines, and k-means clustering. This is similar as you consider many factors while you pay someone for essay , which may include referencing, evidence-based argument, cohesiveness, etc.
Develop Hybrid Models Combine traditional analytical methods with modern algorithms such as decisiontrees, neural networks, and supportvectormachines. Clustering algorithms, such as k-means, group similar data points, and regression models predict trends based on historical data.
Classification algorithms include logistic regression, k-nearest neighbors and supportvectormachines (SVMs), among others. Naïve Bayes algorithms include decisiontrees , which can actually accommodate both regression and classification algorithms.
The feature space reduction is performed by aggregating clusters of features of balanced size. This clustering is usually performed using hierarchical clustering. Tree-based algorithms The tree-based methods aim at repeatedly dividing the label space in order to reduce the search space during the prediction.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Common Machine Learning Algorithms Machine learning algorithms are not limited to those mentioned below, but these are a few which are very common. Linear Regression DecisionTreesSupportVectorMachines Neural Networks Clustering Algorithms (e.g.,
Examples of supervised learning models include linear regression, decisiontrees, supportvectormachines, and neural networks. Common examples include: Linear Regression: It is the best Machine Learning model and is used for predicting continuous numerical values based on input features.
Simple linear regression Multiple linear regression Polynomial regression DecisionTree regression SupportVector regression Random Forest regression Classification is a technique to predict a category. The most common unsupervised algorithms are clustering, dimensionality reduction, and association rule mining.
Machine learning algorithms for unstructured data include: K-means: This algorithm is a data visualization technique that processes data points through a mathematical equation with the intention of clustering similar data points. Isolation forest models can be found on the free machine learning library for Python, scikit-learn.
The goal of unsupervised learning is to identify structures in the data, such as clusters, dimensions, or anomalies, without prior knowledge of the expected output. Some popular classification algorithms include logistic regression, decisiontrees, random forests, supportvectormachines (SVMs), and neural networks.
DecisionTreesDecisiontrees recursively partition data into subsets based on the most significant attribute values. Python’s Scikit-learn provides easy-to-use interfaces for constructing decisiontree classifiers and regressors, enabling intuitive model visualisation and interpretation.
It constructs multiple decisiontrees and combines their predictions to achieve accurate results in identifying different types of network traffic SupportVectorMachines (SVM) : SVM is used for both classification and anomaly detection.
These algorithms are carefully selected based on the specific decision problem and are trained using the prepared data. Machine learning algorithms, such as neural networks or decisiontrees, learn from the data to make predictions or generate recommendations.
Techniques like linear regression, time series analysis, and decisiontrees are examples of predictive models. These models do not rely on predefined labels; instead, they discover the inherent structure in the data by identifying clusters based on similarities. Model selection requires balancing simplicity and performance.
In contrast, decisiontrees assume data can be split into homogeneous groups through feature thresholds. Inductive bias is crucial in ensuring that Machine Learning models can learn efficiently and make reliable predictions even with limited information by guiding how they make assumptions about the data.
Supervised learning algorithms, like decisiontrees, supportvectormachines, or neural networks, enable IoT devices to learn from historical data and make accurate predictions. Unsupervised learning Unsupervised learning involves training machine learning models with unlabeled datasets.
Machine Learning Algorithms Candidates should demonstrate proficiency in a variety of Machine Learning algorithms, including linear regression, logistic regression, decisiontrees, random forests, supportvectormachines, and neural networks. How do you handle missing values in a dataset?
Clustering and dimensionality reduction are common tasks in unSupervised Learning. For example, clustering algorithms can group customers by purchasing behaviour, even if the group labels are not predefined. Selecting an Algorithm Choosing the correct Machine Learning algorithm is vital to the success of your model.
C Classification: A supervised Machine Learning task that assigns data points to predefined categories or classes based on their characteristics. Clustering: An unsupervised Machine Learning technique that groups similar data points based on their inherent similarities.
Density-Based Spatial Clustering of Applications with Noise (DBSCAN): DBSCAN is a density-based clustering algorithm. It identifies regions of high data point density as clusters and flags points with low densities as anomalies. Points that don’t belong to any cluster or are in low-density regions are considered anomalies.
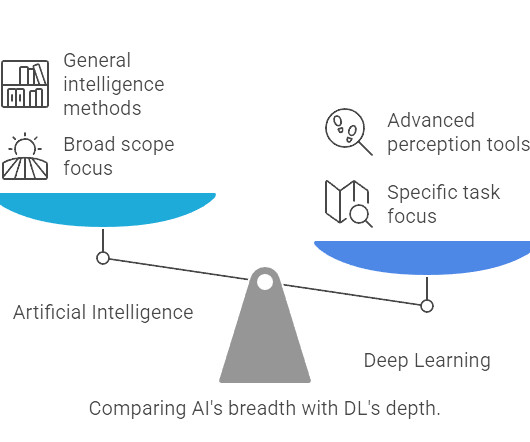
AI is a broad field focused on simulating human intelligence, encompassing techniques like decisiontrees and rule-based systems. In contrast, DL is a specialized subset of Machine Learning (ML) that uses multi-layered neural networks to recognize patterns and automate complex tasks.
For instance, understanding the distribution of MonthlyCharges and TotalCharges can help in pricing strategy decisions. Are there clusters of customers with different spending patterns? #3. Random Forest Classifier (rf): Ensemble method combining multiple decisiontrees. Captures complex relationships in data.
Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow. Begin by employing algorithms for supervised learning such as linear regression , logistic regression, decisiontrees, and supportvectormachines.
Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers. Big Data Technologies and Tools A comprehensive syllabus should introduce students to the key technologies and tools used in Big Data analytics.
Scikit-learn: Scikit-learn is an open-source library that provides a range of tools for building and training machine learning models, including classification, regression, and clustering. Algorithm selection: Choose algorithms that are less prone to biases, such as decisiontrees or supportvectormachines.
Clustering and anomaly detection are examples of unsupervised learning tasks. Reinforcement Learning Reinforcement learning focuses on teaching the model to make decisions by rewarding it for correct actions and penalising it for mistakes. Common applications include image recognition and fraud detection.
There are majorly two categories of sampling techniques based on the usage of statistics, they are: Probability Sampling techniques: Clustered sampling, Simple random sampling, and Stratified sampling. Decisiontrees are more prone to overfitting. Some algorithms that have low bias are DecisionTrees, SVM, etc.
DecisionTrees These trees split data into branches based on feature values, providing clear decision rules. SupportVectorMachines (SVM) SVMs are powerful classifiers that separate data into distinct categories by finding an optimal hyperplane.
Classification techniques like random forests, decisiontrees, and supportvectormachines are among the most widely used, enabling tasks such as categorizing data and building predictive models.
This allows it to evaluate and find relationships between the data points which is essential for clustering. Supports batch processing for quick processing for the images. Relies on explicit decision boundaries or feature representations for sample selection.
Machine Learning Supervised Learning includes algorithms like linear regression, decisiontrees, and supportvectormachines. Unsupervised Learning techniques such as clustering and dimensionality reduction to discover patterns in data.
Scikit-learn provides a consistent API for training and using machine learning models, making it easy to experiment with different algorithms and techniques. It is commonly used in MLOps workflows for deploying and managing machine learning models and inference services.
Decisiontrees: They segment data into branches based on sequential questioning. Common types include: K-means clustering: Groups similar data points together based on specific metrics. Common types include: K-means clustering: Groups similar data points together based on specific metrics.
Common algorithms used in classification tasks include: DecisionTrees: A tree-like model that makes decisions based on feature values. Random Forests: An ensemble of decisiontrees, improving accuracy through voting mechanisms.
Learning the decision boundary Machine learning algorithms learn decision boundaries through a training process that adjusts the model’s parameters based on the input data. Algorithms like logistic regression or supportvectormachines focus on optimizing the decision boundary to minimize misclassification errors.
Some common supervised learning algorithms include decisiontrees, random forests, supportvectormachines, and linear regression. These algorithms help businesses make decisions when there is clear historical data available. Unsupervised learning outputs are not as direct.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content