This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Recurrent Neural Networks (RNNs): These powerful deeplearning models can learn complex patterns and long-term dependencies within time series data, making them suitable for more intricate forecasting tasks. Clustering Algorithms: Clustering algorithms can group data points with similar features. shirt, pants).
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
These longer sequence lengths allow models to better understand long-range dependencies in text, generate more globally coherent outputs, and handle tasks requiring analysis of lengthy documents. More details about FP8 can be found at FP8 Formats For DeepLearning. supports the Llama 3.1 (and
For reference, GPT-3, an earlier generation LLM has 175 billion parameters and requires months of non-stop training on a cluster of thousands of accelerated processors. The Carbontracker study estimates that training GPT-3 from scratch may emit up to 85 metric tons of CO2 equivalent, using clusters of specialized hardware accelerators.
With that being said, let’s have a closer look at how unsupervised machine learning is omnipresent in all industries. What Is Unsupervised Machine Learning? If you’ve ever come across deeplearning, you might have heard about two methods to teach machines: supervised and unsupervised. Source ].
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. We use Slurm as the cluster management and job scheduling system.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
As a result, machine learning practitioners must spend weeks of preparation to scale their LLM workloads to large clusters of GPUs. To learn more about the SageMaker model parallel library, refer to SageMaker model parallelism library v2 documentation. You can also refer to our example notebooks to get started.
release , you can now launch Neuron DLAMIs (AWS DeepLearning AMIs) and Neuron DLCs (AWS DeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deeplearning frameworks.
For instance, when developing a medical search engine, obtaining a large dataset of real user queries and relevant documents is often infeasible due to privacy concerns surrounding personal health information. These PDFs will serve as the source for generating document chunks.
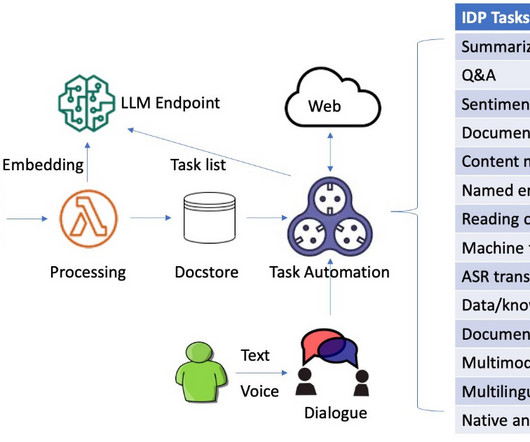
Intelligent document processing (IDP) is a technology that automates the processing of high volumes of unstructured data, including text, images, and videos. The system is capable of processing images, large PDF, and documents in other format and answering questions derived from the content via interactive text or voice inputs.
Hierarchical Clustering. Hierarchical Clustering: Since, we have already learnt “ K- Means” as a popular clustering algorithm. The other popular clustering algorithm is “Hierarchical clustering”. remember we have two types of “Hierarchical Clustering”. Divisive Hierarchical clustering. They are : 1.Agglomerative
Clustering — Beyonds KMeans+PCA… Perhaps the most popular way of clustering is K-Means. It is also very common as well to combine K-Means with PCA for visualizing the clustering results, and many clustering applications follow that path (e.g. this link ).
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. For a detailed walkthrough on fine-tuning the Meta Llama 3.2
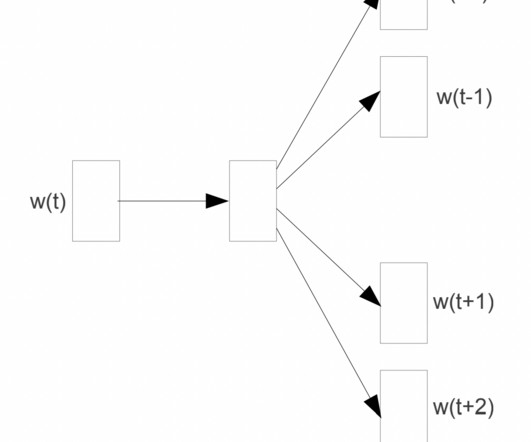
Doc2Vec Doc2Vec, also known as Paragraph Vector, is an extension of Word2Vec that learns vector representations of documents rather than words. Doc2Vec learns vector representations of documents by combining the word vectors with a document-level vector. DM Architecture. DBOW Architecture.
How to implement Multichannel transcription with AssemblyAI You can use the API or one of the AssemblyAI SDKs to implement Multichannel transcription (see developer documentation ). Speaker Embeddings with DeepLearning models : Once the audio is segmented, each segment is processed using a deeplearning model to extract speaker embeddings.
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
Its agent for software development can solve complex tasks that go beyond code suggestions, such as building entire application features, refactoring code, or generating documentation. Learn how to harness the power of AWS AI chips to create intelligent systems that understand and process text, images, and video.
Recent developments in deeplearning have led to increasingly large models such as GPT-3, BLOOM, and OPT, some of which are already in excess of 100 billion parameters. Many enterprise customers choose to deploy their deeplearning workloads using Kubernetes—the de facto standard for container orchestration in the cloud.
Our deeplearning models have non-trivial requirements: they are gigabytes in size, are numerous and heterogeneous, and require GPUs for fast inference and fine-tuning. The architecture deploys a simple service in a Kubernetes pod within an EKS cluster. xlarge nodes is included to run system pods that are needed by the cluster.
The primary components include: Graphics Processing Units (GPUs) These are specially designed for parallel processing, making them ideal for training deeplearning models. Foundation Models Foundation models are pre-trained deeplearning models that serve as the backbone for various generative applications.
Research in scene text detection and recognition (or scene text spotting) has been the major driver of this rapid development through adapting OCR to natural images that have more complex backgrounds than document images. These OCR products digitize and democratize the valuable information that is stored in paper or image-based sources (e.g.,
These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests. This approach allows for tailored responses and processes for different types of user needs, whether its a simple question, a document translation, or a complex inquiry about IDIADAs services.
Here are some ways data scientists can leverage GPT for regular data science tasks with real-life examples Text Generation and Summarization: Data scientists can use GPT to generate synthetic text or create automatic summaries of lengthy documents. offers an open-source platform for scalable machine learning and deeplearning.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. It removes the undifferentiated heavy lifting involved in building and optimizing machine learning (ML) infrastructure for training foundation models (FMs).
AWS Trainium instances for training workloads SageMaker ml.trn1 and ml.trn1n instances, powered by Trainium accelerators, are purpose-built for high-performance deeplearning training and offer up to 50% cost-to-train savings over comparable training optimized Amazon Elastic Compute Cloud (Amazon EC2) instances.
After trillions of linear algebra computations, it can take a new picture and segment it into clusters. Deeplearning multiple– layer artificial neural networks are the basis of deeplearning, a subdivision of machine learning (hence the word “deep”). GIS Random Forest script.
Given this mission, Talent.com and AWS joined forces to create a job recommendation engine using state-of-the-art natural language processing (NLP) and deeplearning model training techniques with Amazon SageMaker to provide an unrivaled experience for job seekers. During online A/B testing, we evaluate the CTR improvements.
Botnets Detection at Scale — Lesson Learned from Clustering Billions of Web Attacks into Botnets. Some of the questions you’ll explore include How much documentation is appropriate? You will use the same example to explore both approaches utilizing TensorFlow in a Colab notebook. Should you have manual sign-offs?
It is a document based storage that provides a fully managed database, with built-in full-text and vector Search , support for Geospatial queries, Charts and native support for efficient time series storage and querying capabilities. Setup the Database access and Network access.
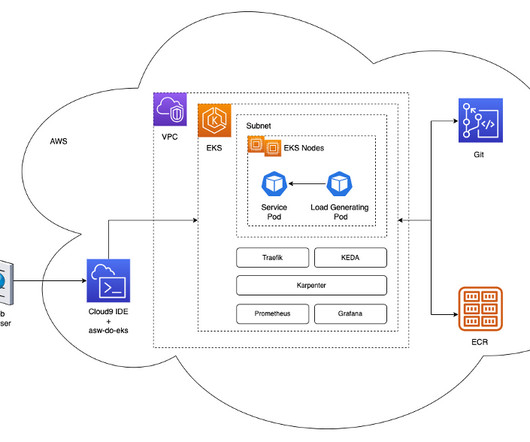
The architecture is built on a robust and secure AWS foundation: The architecture uses AWS services like Application Load Balancer , AWS WAF , and EKS clusters for seamless ingress, threat mitigation, and containerized workload management. The following diagram illustrates the WxAI architecture on AWS.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
Today, we’re pleased to announce the preview of Amazon SageMaker Profiler , a capability of Amazon SageMaker that provides a detailed view into the AWS compute resources provisioned during training deeplearning models on SageMaker. For more information, refer to documentation. and 1.13.1) and TensorFlow (version 2.12.0
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. With the DJL, integrating this deeplearning is simple. When we did our research online, the Deep Java Library showed up on the top. The architecture of DJL is engine agnostic.
Simply fire up DataRobot’s unsupervised mode and use clustering or anomaly detection to help you discover patterns and insights with your data. Allow the platform to handle infrastructure and deeplearning techniques so that you can maximize your focus on bringing value to your organization. It is part of our new 7.3
Photo by NASA on Unsplash Hello and welcome to this post, in which I will study a relatively new field in deeplearning involving graphs — a very important and widely used data structure. This post includes the fundamentals of graphs, combining graphs and deeplearning, and an overview of Graph Neural Networks and their applications.
It offers a comprehensive ecosystem that supports distributed training and inference, allowing developers to scale their machine learning workflows seamlessly. TensorFlow provides high-level APIs, such as tf.distribute, to distribute training across multiple devices, machines, or clusters.
Amazon Titan Text Embeddings is a text embeddings model that converts natural language text—consisting of single words, phrases, or even large documents—into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity. Why do we need an embeddings model?
An Auto-forecasting tool will usually compare various statistical models (sometimes deep-learning models are included as well) for each time series and then select the best-performing one based on users’ criteria to model the specific series. So how do we choose from all the available different clustering methods? Absolutely!
For example, a health insurance company may want their question answering bot to answer questions using the latest information stored in their enterprise document repository or database, so the answers are accurate and reflect their unique business rules. Identify the top K most relevant documents based on the user query.
A small number of similar documents (typically three) is added as context along with the user question to the “prompt” provided to another LLM and then that LLM generates an answer to the user question using information provided as context in the prompt. Chunking of knowledge base documents. Implementing the question answering task.
Prerequisites To follow along, you should have a Kubernetes cluster with the SageMaker ACK controller v1.2.9 For instructions on how to provision an Amazon Elastic Kubernetes Service (Amazon EKS) cluster with Amazon Elastic Compute Cloud (Amazon EC2) Linux managed nodes using eksctl, see Getting started with Amazon EKS – eksctl.
To further comment on Fury, for those looking to intern in the short term, we have a position available to work in an NLP deeplearning project in the healthcare domain. documentation Note The datasets used in this tutorial are available and can be more easily accessed using the ? Broadcaster Stream API Fast.ai NLP library.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content