This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
With these hyperlinks, we can bypass traditional memory and storage-intensive methods of first downloading and subsequently processing images locally—a task made even more daunting by the size and scale of our dataset, spanning over 4 TB. These batches are then evenly distributed across the machines in a cluster. format("/".join(tile_prefix),
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deeplearning workloads in the cloud.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. We use Slurm as the cluster management and job scheduling system.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
Distributed model training requires a cluster of worker nodes that can scale. In this blog post, AWS collaborates with Meta’s PyTorch team to discuss how to use the PyTorch FSDP library to achieve linear scaling of deeplearning models on AWS seamlessly using Amazon EKS and AWS DeepLearning Containers (DLCs).
Recent developments in deeplearning have led to increasingly large models such as GPT-3, BLOOM, and OPT, some of which are already in excess of 100 billion parameters. Many enterprise customers choose to deploy their deeplearning workloads using Kubernetes—the de facto standard for container orchestration in the cloud.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. First, download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer. Youngsuk Park is a Sr.
AWS Trainium instances for training workloads SageMaker ml.trn1 and ml.trn1n instances, powered by Trainium accelerators, are purpose-built for high-performance deeplearning training and offer up to 50% cost-to-train savings over comparable training optimized Amazon Elastic Compute Cloud (Amazon EC2) instances.
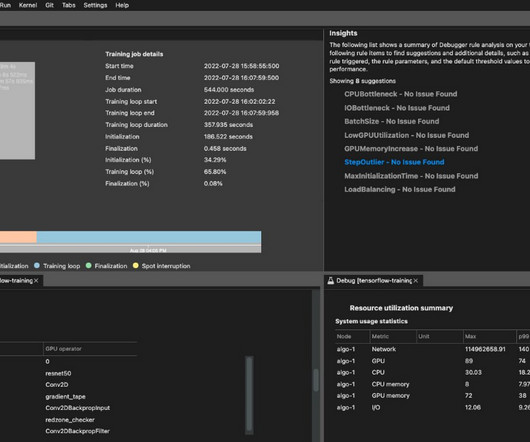
SageMaker supports various data sources and access patterns, distributed training including heterogenous clusters, as well as experiment management features and automatic model tuning. When an On-Demand job is launched, it goes through five phases: Starting, Downloading, Training, Uploading, and Completed.
By distributing experts across workers, expert parallelism addresses the high memory requirements of loading all experts on a single device and enables MoE training on a larger cluster. The following figure offers a simplified look at how expert parallelism works on a multi-GPU cluster.
Libraries such as DeepSpeed (an open-source deeplearning optimization library for PyTorch) address some of these challenges, and can help accelerate model development and training. Training setup We provisioned a managed compute cluster comprised of 16 dl1.24xlarge instances using AWS Batch. Pre-training of a 1.5-billion-parameter
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deeplearning training. In this post, we showed cost-efficient training of LLMs on AWS deeplearning hardware. Ben Snyder is an applied scientist with AWS DeepLearning.
Now, with today’s announcement, you have another straightforward compute option for workflows that need to train or fine-tune demanding deeplearning models: running them on Trainium. Deployment To deploy a Metaflow stack using AWS CloudFormation , complete the following steps: Download the CloudFormation template.
Download the free, unabridged version here. They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deeplearning to the team. Download the free, unabridged version here.
In this blog post, we will delve into the mechanics of the Grubbs test, its application in anomaly detection, and provide a practical guide on how to implement it using real-world data. Thakur, eds., Join the Newsletter! Website The post Anomaly Detection: How to Find Outliers Using the Grubbs Test appeared first on PyImageSearch.
Figure 5: Architecture of Convolutional Autoencoder for Image Segmentation (source: Bandyopadhyay, “Autoencoders in DeepLearning: Tutorial & Use Cases [2023],” V7Labs , 2023 ). This can be helpful for visualization, data compression, and speeding up other machine learning algorithms. That’s not the case.
In the first part of our Anomaly Detection 101 series, we learned the fundamentals of Anomaly Detection and saw how spectral clustering can be used for credit card fraud detection. To download our dataset and set up our environment, we will install the following packages. Or has to involve complex mathematics and equations?
To learn how to develop Face Recognition applications using Siamese Networks, just keep reading. Jump Right To The Downloads Section Face Recognition with Siamese Networks, Keras, and TensorFlow Deeplearning models tend to develop a bias toward the data distribution on which they have been trained. That’s not the case.
They have been trained using two newly unveiled custom-built 24K GPU clusters on more than 15 trillion tokens of data. Ollama employs a transformer architecture, a type of deeplearning model that’s pivotal in large language models. Llama 3 models utilize data to achieve unprecedented scaling.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file. Download the GitHub repository Complete the following steps to download the GitHub repo: In the SageMaker notebook, on the File menu, choose New and Terminal.
Orchestration Tools: Kubernetes, Docker Swarm Purpose: Manages the deployment, scaling, and operation of application containers across clusters of hosts. Do you think learning computer vision and deeplearning has to be time-consuming, overwhelming, and complicated? Download the code! That’s not the case.
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. With the DJL, integrating this deeplearning is simple. Business requirements We are the US squad of the Sportradar AI department. The architecture of DJL is engine agnostic.
Transformer neural networks A transformer neural network is a popular deeplearning architecture to solve sequence-to-sequence tasks. It uses attention as the learning mechanism to achieve close to human-level performance. The integration makes it easier to customize Hugging Face models on domain-specific use cases.
First, we started by benchmarking our workloads using the readily available Graviton DeepLearning Containers (DLCs) in a standalone environment. So far, we have migrated PyTorch and TensorFlow based Distil RoBerta-base, spaCy clustering, prophet, and xlmr models to Graviton3-based c7g instances.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. This method is generally much faster, with the model typically downloading in just a couple of minutes from Amazon S3. You can connect with Dmitry on LinkedIn.
Face Recognition One of the most effective Github Projects on Data Science is a Face Recognition project that makes use of DeepLearning and Histogram of Oriented Gradients (HOG) algorithm. Customer Segmentation using K-Means Clustering One of the most crucial uses of data science is customer segmentation.
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deeplearning has achieved remarkable success in supervised tasks, especially in image recognition. Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images.
Summary: TensorFlow is an open-source DeepLearning framework that facilitates creating and deploying Machine Learning models. Its flexible architecture allows efficient computation across CPUs, GPUs, and TPUs, accelerating DeepLearning tasks. It’s an open-source DeepLearning framework developed by Google.
The model weights are available to download, inspect and deploy anywhere. Starting June 7th, both Falcon LLMs will also be available in Amazon SageMaker JumpStart, SageMaker’s machine learning (ML) hub that offers pre-trained models, built-in algorithms, and pre-built solution templates to help you quickly get started with ML.
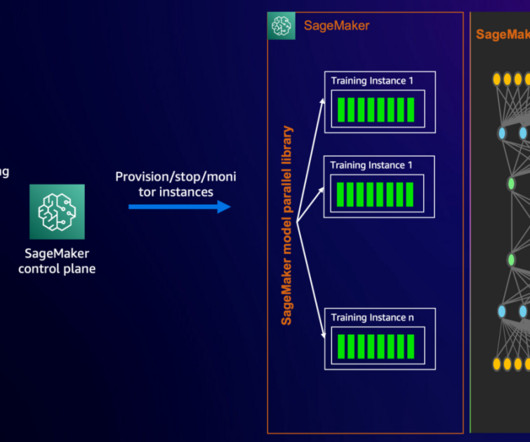
Recent years have shown amazing growth in deeplearning neural networks (DNNs). Amazon SageMaker distributed training jobs enable you with one click (or one API call) to set up a distributed compute cluster, train a model, save the result to Amazon Simple Storage Service (Amazon S3), and shut down the cluster when complete.
Today, many modern Speech-to-Text APIs and Speaker Diarization libraries apply advanced DeepLearning models to perform tasks (A) and (B) near human-level accuracy, significantly increasing the utility of Speaker Diarization APIs. An embedding is a DeepLearning model’s low-dimensional representation of an input.
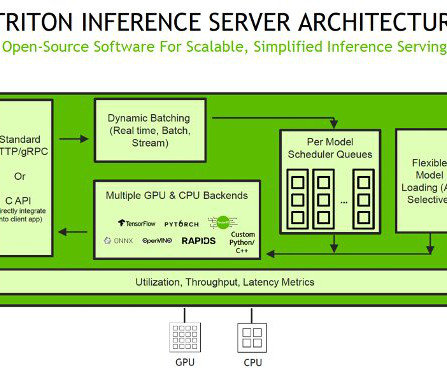
TensorRT is an SDK developed by NVIDIA that provides a high-performance deeplearning inference library. It’s optimized for NVIDIA GPUs and provides a way to accelerate deeplearning inference in production environments. Triton Inference Server supports ONNX as a model format.
Scikit Learn Scikit Learn is a comprehensive machine learning tool designed for data mining and large-scale unstructured data analysis. With an impressive collection of efficient tools and a user-friendly interface, it is ideal for tackling complex classification, regression, and cluster-based problems.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. Hugging Face is a popular open source hub for machine learning (ML) models. You use the same script for downloading the model file when creating the SageMaker endpoint.
It’s essential to review and adhere to the applicable license terms before downloading or using these models to make sure they’re suitable for your intended use case. He focuses on developing scalable machine learning algorithms. These models are released under different licenses designated by their respective sources.
ClusteringClustering is a class of algorithms that segregates the data into a set of definite clusters such that similar points lie in the same cluster and dissimilar points lie in different clusters. Several clustering algorithms (e.g., means and spectral clustering) can be used in recommendation engines.
SageMaker notably supports popular deeplearning frameworks, including PyTorch, which is integral to the solutions provided here. Inside the managed training job in the SageMaker environment, the training job first downloads the mouse genome using the S3 URI supplied by HealthOmics.
Therefore, we decided to introduce a deeplearning-based recommendation algorithm that can identify not only linear relationships in the data, but also more complex relationships. However, it was necessary to upgrade the recommendation service to analyze each customer’s taste and meet their needs.
The process involves the following steps: Download the training and validation data, which consists of PDFs from Uber and Lyft 10K documents. Bryan Yost is a Principle DeepLearning Architect at Amazon Web Services Generative AI Innovation Center. These PDFs will serve as the source for generating document chunks.
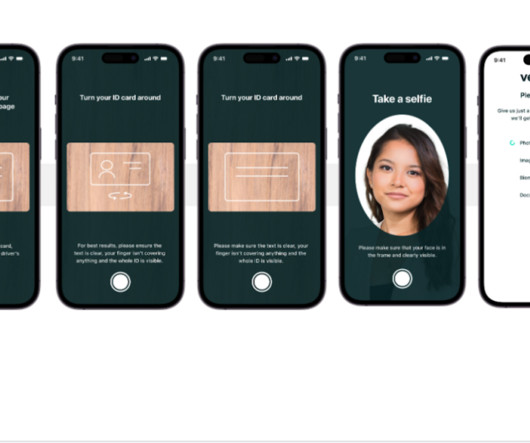
As an AI-powered solution, Veriff needs to create and run dozens of machine learning (ML) models in a cost-effective way. These models range from lightweight tree-based models to deeplearning computer vision models, which need to run on GPUs to achieve low latency and improve the user experience. Download the model weights.
For CSV, we still recommend splitting up large files into smaller ones to reduce data download time and enable quicker reads. The single-GPU training path still has some advantage in downloading and reading only part of the data in each instance, and therefore low data download time. However, it’s not a requirement. Tony Cruz
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content