This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance time by half. RELand consistently outperforms the benchmark models on all relevant metrics.
Hammerspace, the company orchestrating the Next Data Cycle, unveiled the high-performance NAS architecture needed to address the requirements of broad-based enterprise AI, machine learning and deeplearning (AI/ML/DL) initiatives and the widespread rise of GPU computing both on-premises and in the cloud.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and ML engineers to build, train, and deploy ML models using geospatial data. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
Deeplearning models are typically highly complex. While many traditional machine learning models make do with just a couple of hundreds of parameters, deeplearning models have millions or billions of parameters. This is where visualizations in ML come in.
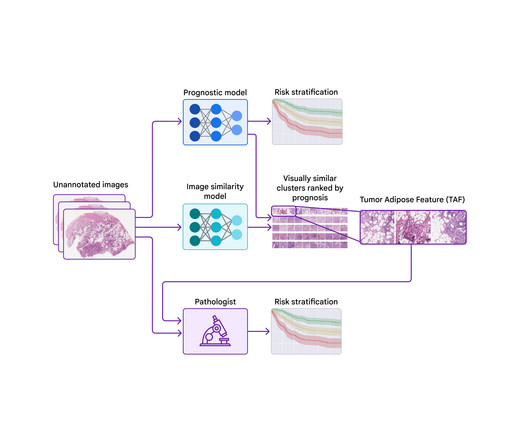
Developing machine learning (ML) tools in pathology to assist with the microscopic review represents a compelling research area with many potential applications. While these efforts focus on using ML to detect or quantify known features, alternative approaches offer the potential to identify novel features.
It offers a comprehensive ecosystem that supports distributed training and inference, allowing developers to scale their machine learning workflows seamlessly. TensorFlow provides high-level APIs, such as tf.distribute, to distribute training across multiple devices, machines, or clusters.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deeplearning workloads in the cloud.
Mixed Precision Training with FP8 As shown in figure below, FP8 is a datatype supported by NVIDIA’s H100 and H200 GPUs, enables efficient deeplearning workloads. More details about FP8 can be found at FP8 Formats For DeepLearning. supports the Llama 3.1 (and The following diagram shows the solution architecture.
Thanks to machine learning (ML) and artificial intelligence (AI), it is possible to predict cellular responses and extract meaningful insights without the need for exhaustive laboratory experiments. Gene set enrichment : Identify clusters of genes that behave similarly under perturbations and describe their common function.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
With that being said, let’s have a closer look at how unsupervised machine learning is omnipresent in all industries. What Is Unsupervised Machine Learning? If you’ve ever come across deeplearning, you might have heard about two methods to teach machines: supervised and unsupervised. Unsupervised ML: The Basics.
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
Introduction GPUs as main accelerators for deeplearning training tasks suffer from under-utilization. Authors of AntMan [1] propose a deeplearning infrastructure, which is a co-design of cluster schedulers (e.g., with deeplearning frameworks (e.g., with deeplearning frameworks (e.g.,
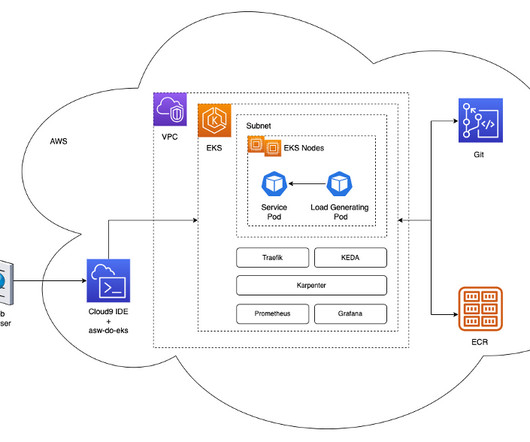
This solution simplifies the integration of advanced monitoring tools such as Prometheus and Grafana, enabling you to set up and manage your machine learning (ML) workflows with AWS AI Chips. By deploying the Neuron Monitor DaemonSet across EKS nodes, developers can collect and analyze performance metrics from ML workload pods.
Deeplearning models have emerged as a powerful tool in the field of ML, enabling computers to learn from vast amounts of data and make decisions based on that learning. In this article, we will explore the importance of deeplearning models and their applications in various fields.
Solving Machine Learning Tasks with MLCoPilot: Harnessing Human Expertise for Success Many of us have made use of large language models (LLMs) like ChatGPT to generate not only text and images but also code, including machine learning code. This is where ML CoPilot enters the scene.
While artificial intelligence (AI), machine learning (ML), deeplearning and neural networks are related technologies, the terms are often used interchangeably, which frequently leads to confusion about their differences. Machine learning is a subset of AI. This blog post will clarify some of the ambiguity.
Over the course of 2023, we rapidly scaled up our training clusters from 1K, 2K, 4K, to eventually 16K GPUs to support our AI workloads. Today, we’re training our models on two 24K-GPU clusters. We don’t expect this upward trajectory for AI clusters to slow down any time soon. Building AI clusters requires more than just GPUs.
Summary: Machine Learning and DeepLearning are AI subsets with distinct applications. ML works with structured data, while DL processes complex, unstructured data. ML requires less computing power, whereas DL excels with large datasets. DL demands high computational power, whereas ML can run on standard systems.
Mathematical and statistical knowledge: A solid foundation in mathematical concepts, linear algebra, calculus, and statistics is necessary to understand the underlying principles of machine learning algorithms. Combining their complementary skills and expertise leads to comprehensive and impactful data-driven solutions.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. We use Slurm as the cluster management and job scheduling system.
Machine learning (ML) research has proven that large language models (LLMs) trained with significantly large datasets result in better model quality. Distributed model training requires a cluster of worker nodes that can scale.
Our deeplearning models have non-trivial requirements: they are gigabytes in size, are numerous and heterogeneous, and require GPUs for fast inference and fine-tuning. The architecture deploys a simple service in a Kubernetes pod within an EKS cluster. xlarge nodes is included to run system pods that are needed by the cluster.
release , you can now launch Neuron DLAMIs (AWS DeepLearning AMIs) and Neuron DLCs (AWS DeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deeplearning frameworks.
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. So, let’s dive in and discover everything you need to know about model packaging in machine learning.
ML models have grown significantly in recent years, and businesses increasingly rely on them to automate and optimize their operations. However, managing ML models can be challenging, especially as models become more complex and require more resources to train and deploy. What is MLOps?
I think I managed to get most of the ML players in there…?? And who by gradient descent, who by quick segment Who in the cluster, who in the top percent Who by linear regression, who by SVM Who in random forest, who in deeplearning And who shall I say is normalizing?
This list, encompassing the most effective machine learning tools, serves as a valuable guide for developers seeking to enhance their machine learning toolkit and drive the AI revolution forward. This open-source library is renowned for its capabilities in numerical computation, particularly in large-scale machine learning projects.
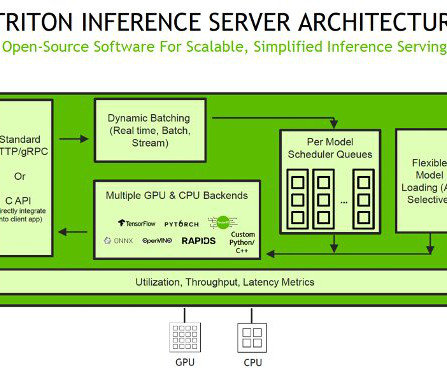
SageMaker provides single model endpoints (SMEs), which allow you to deploy a single ML model, or multi-model endpoints (MMEs), which allow you to specify multiple models to host behind a logical endpoint for higher resource utilization. TensorRT is an SDK developed by NVIDIA that provides a high-performance deeplearning inference library.
Hierarchical Clustering. Hierarchical Clustering: Since, we have already learnt “ K- Means” as a popular clustering algorithm. The other popular clustering algorithm is “Hierarchical clustering”. remember we have two types of “Hierarchical Clustering”. Divisive Hierarchical clustering. They are : 1.Agglomerative
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
Recent developments in deeplearning have led to increasingly large models such as GPT-3, BLOOM, and OPT, some of which are already in excess of 100 billion parameters. Many enterprise customers choose to deploy their deeplearning workloads using Kubernetes—the de facto standard for container orchestration in the cloud.
Clustering — Beyonds KMeans+PCA… Perhaps the most popular way of clustering is K-Means. It is also very common as well to combine K-Means with PCA for visualizing the clustering results, and many clustering applications follow that path (e.g. this link ).
Running machine learning (ML) workloads with containers is becoming a common practice. What you get is an ML development environment that is consistent and portable. With containers, scaling on a cluster becomes much easier. With containers, scaling on a cluster becomes much easier. Run the ML task on Amazon ECS.
Introduction to DeepLearning Algorithms: Deeplearning algorithms are a subset of machine learning techniques that are designed to automatically learn and represent data in multiple layers of abstraction. How DeepLearning Algorithms Work?
AWS Trainium instances for training workloads SageMaker ml.trn1 and ml.trn1n instances, powered by Trainium accelerators, are purpose-built for high-performance deeplearning training and offer up to 50% cost-to-train savings over comparable training optimized Amazon Elastic Compute Cloud (Amazon EC2) instances.
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. We recently developed four more new models.
AI engineering professional certificate by IBM AI engineering professional certificate from IBM targets fundamentals of machine learning, deeplearning, programming, computer vision, NLP, etc. However, you are expected to possess intermediate coding experience and a background as an AI ML engineer; to begin with the course.
Deeplearning continues to be a hot topic as increased demands for AI-driven applications, availability of data, and the need for increased explainability are pushing forward. So let’s take a quick dive and see some big sessions about deeplearning coming up at ODSC East May 9th-11th.
How this machine learning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (cluster analysis - CA) and classification are two important tasks that occur in our daily lives. Industrial Internet of Things (IIoT) The Constraints Within the area of Industry 4.0,
Additionally, the elimination of human loop processes has made it possible for AI/ML to construct training data for data annotation and labeling, which has a major influence on geospatial data. This function can be improved by AI and ML, which allow GIS to produce insights, automate procedures, and learn from data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content