This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction: Hi everyone, recently while participating in a DeepLearning competition, I. The post An Approach towards Neural Network based Image Clustering appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
The post K-Means Clustering and Transfer Learning for Image Classification appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Hey Guys, Hope you are doing well. This article will.
This article was published as a part of the Data Science Blogathon Introduction Deeplearning has evolved a lot in recent years and we all are excited to build deeper architecture networks to gain more accuracies for our models. These techniques are widely tried for Image related works like classification, clustering, or synthesis.
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
This blog lists down-trending data science, analytics, and engineering GitHub repositories that can help you with learning data science to build your own portfolio. What is GitHub? GitHub is a powerful platform for data scientists, data analysts, data engineers, Python and R developers, and more.
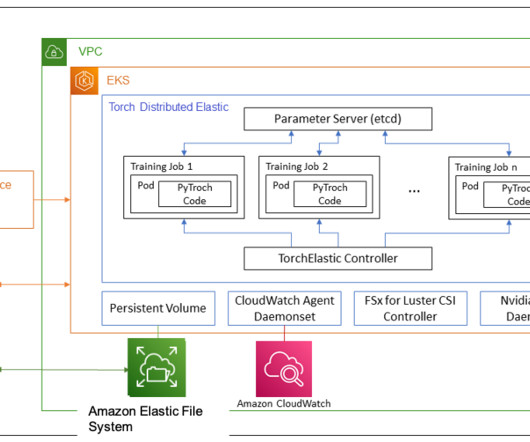
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deeplearning workloads in the cloud.
Home Table of Contents Introduction to GitHub Actions for Python Projects Introduction What Is CICD? For Python projects, CI/CD pipelines ensure that your code is consistently integrated and delivered with high quality and reliability. Git is the most commonly used VCS for Python projects, enabling collaboration and version tracking.
Python machine learning packages have emerged as the go-to choice for implementing and working with machine learning algorithms. These libraries, with their rich functionalities and comprehensive toolsets, have become the backbone of data science and machine learning practices.
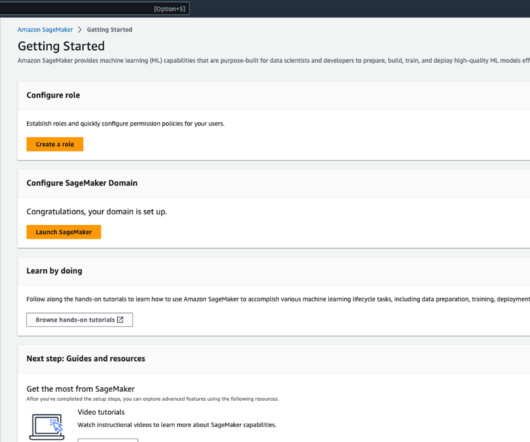
Solution overview SageMaker JumpStart provides FMs through two primary interfaces: Amazon SageMaker Studio and the SageMaker Python SDK. SageMaker Studio is a comprehensive interactive development environment (IDE) that offers a unified, web-based interface for performing all aspects of the machine learning (ML) development lifecycle.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. We use Slurm as the cluster management and job scheduling system.
Programming Language (R or Python). Programmers can start with either R or Python. it is overwhelming to learn data science concepts and a general-purpose language like python at the same time. Python can be added to the skill set later. Clustering (Unsupervised). DeepLearning. Ensembling.
Each word or sentence is mapped to a high-dimensional vector space, where similar meanings cluster together. Implement and analyze search results using Python scripts. Now, lets implement a Python script to execute the neural search query in OpenSearch. Figure 3: What Is Semantic Search? disable_warnings(urllib3.exceptions.InsecureRequestWarning)
Let's see how to use Multichannel transcription with the AssemblyAI Python SDK: import assemblyai as aai audio_file = " /multichannel-example.mp3" config = aai.TranscriptionConfig(multichannel=True) transcript = aai.Transcriber().transcribe(audio_file,
With containers, scaling on a cluster becomes much easier. In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deeplearning training. On the Amazon ECS console, choose Clusters in the navigation pane.
Python or R) to find the critical value from the -distribution for the chosen and degrees of freedom ( ). Performing the Grubbs Test In this section, we will see how to perform the Grubbs test in Python for sample datasets with small sample sizes. Note: We need to use statistical tables ( Table 1 ) or software (e.g., Thakur, eds.,
Clustering — Beyonds KMeans+PCA… Perhaps the most popular way of clustering is K-Means. It is also very common as well to combine K-Means with PCA for visualizing the clustering results, and many clustering applications follow that path (e.g. this link ).
How this machine learning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (cluster analysis - CA) and classification are two important tasks that occur in our daily lives. Industrial Internet of Things (IIoT) The Constraints Within the area of Industry 4.0,
Facebook AI similarity search (FAISS) FAISS is used for similarity search and clustering dense vectors. PyTorch and TensorFlow These are commonly used deeplearning frameworks that offer immense flexibility in building RAG models. Haystack It is a Python framework that is built on Elasticsearch.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deeplearning. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development.
Deeplearning continues to be a hot topic as increased demands for AI-driven applications, availability of data, and the need for increased explainability are pushing forward. So let’s take a quick dive and see some big sessions about deeplearning coming up at ODSC East May 9th-11th.
Developing NLP tools isn’t so straightforward, and requires a lot of background knowledge in machine & deeplearning, among others. Machine & DeepLearning Machine learning is the fundamental data science skillset, and deeplearning is the foundation for NLP.
The skill clusters are formed via the discipline of Topic Modelling , a method from unsupervised machine learning , which show the differences in the distribution of requirements between them. Over the time, it will provides you the answer on your questions related to which tool to learn! Why we did it?
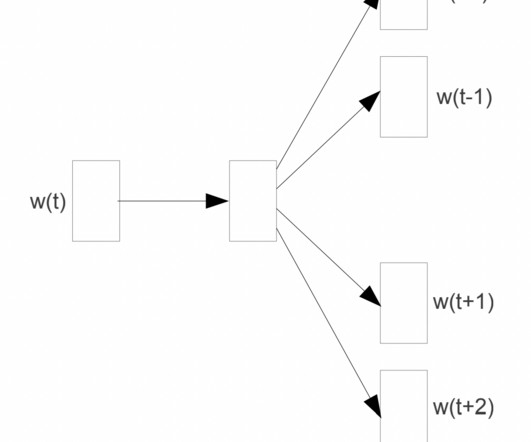
Image taken from Efficient Estimation of Word Representation in Vector Space Top2Vec Top2Vec is an unsupervised machine-learning model designed for topic modelling and document clustering. For this, Top2Vec utilizes a manifold learning technique called UMAP. To achieve this, Top2Vec utilizes the doc2vec model.
Hyperparameter optimization is highly computationally demanding for deeplearning models. In our solution, we implement a hyperparameter grid search on an EKS cluster for tuning a bert-base-cased model for classifying positive or negative sentiment for stock market data headlines. to launch the cluster. eks-create.sh
AI engineering professional certificate by IBM AI engineering professional certificate from IBM targets fundamentals of machine learning, deeplearning, programming, computer vision, NLP, etc. Prior experience in Python, ML basics, data training, and deeplearning will come in handy for a smooth ride ahead.
One of the popular techniques for detecting anomalies or outliers in data is K-means clustering, a machine learning algorithm that can uncover patterns and groupings in large datasets. In this article, we will explore the application of K-means clustering to a credit card dataset to identify potential fraud cases.
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. With the DJL, integrating this deeplearning is simple. Our data scientists train the model in Python using tools like PyTorch and save the model as PyTorch scripts.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. It removes the undifferentiated heavy lifting involved in building and optimizing machine learning (ML) infrastructure for training foundation models (FMs).
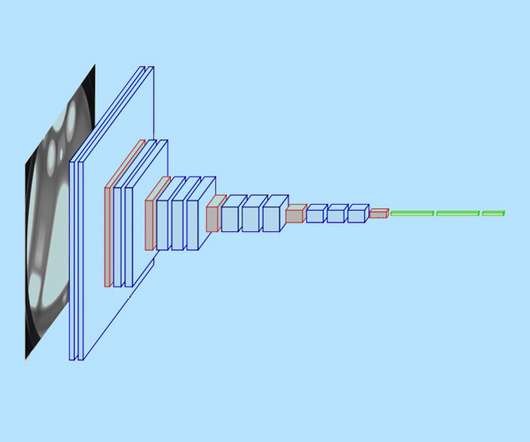
After trillions of linear algebra computations, it can take a new picture and segment it into clusters. Deeplearning multiple– layer artificial neural networks are the basis of deeplearning, a subdivision of machine learning (hence the word “deep”). GIS Random Forest script.
Azure ML SDK : For those who prefer a code-first approach, the Azure Machine LearningPython SDK allows data scientists to work in familiar environments like Jupyter notebooks while leveraging Azure’s capabilities. Check out the Python SDK reference for detailed information. DeepLearning with Python by Francois Chollet.
SmartCore SmartCore is a machine learning library written in Rust that provides a variety of algorithms for regression, classification, clustering, and more. The library encompasses both conventional and advanced machine learning techniques, including linear regression, k-means clustering, random forests, and support vector machines.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. He focuses on developing scalable machine learning algorithms. Youngsuk Park is a Sr.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
AWS Trainium instances for training workloads SageMaker ml.trn1 and ml.trn1n instances, powered by Trainium accelerators, are purpose-built for high-performance deeplearning training and offer up to 50% cost-to-train savings over comparable training optimized Amazon Elastic Compute Cloud (Amazon EC2) instances.
We cover two approaches: using the Amazon SageMaker Studio UI for a no-code solution, and using the SageMaker Python SDK. FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. Fine-tune using the SageMaker Python SDK You can also fine-tune Meta Llama 3.2 Vision models.
Machine learning for text extraction with Python is one of the best combos out there for this task. In this blog post, we’ll talk about how one can use Machine learning and Python to perform text extraction with the highest level of accuracy. You can use it to teach computers and measure their learning progress.
They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization. These bootcamps are focused training and learning platforms for people. Nowadays, individuals tend to opt for bootcamps for quick results and faster learning of any particular niche.
It provides an approachable, robust Python API for the full infrastructure stack of ML/AI, from data and compute to workflows and observability. Now, with today’s announcement, you have another straightforward compute option for workflows that need to train or fine-tune demanding deeplearning models: running them on Trainium.
In this article, we will explore the concept of applied text mining in Python and how to do text mining in Python. Introduction to Applied Text Mining in Python Before going ahead, it is important to understand, What is Text Mining in Python? How To Do Text Mining in Python? within the text.
Transformer neural networks A transformer neural network is a popular deeplearning architecture to solve sequence-to-sequence tasks. It uses attention as the learning mechanism to achieve close to human-level performance. The integration makes it easier to customize Hugging Face models on domain-specific use cases.
Today, we’re pleased to announce the preview of Amazon SageMaker Profiler , a capability of Amazon SageMaker that provides a detailed view into the AWS compute resources provisioned during training deeplearning models on SageMaker. In this post, we walk you through the capabilities of SageMaker Profiler.
As an AI-powered solution, Veriff needs to create and run dozens of machine learning (ML) models in a cost-effective way. These models range from lightweight tree-based models to deeplearning computer vision models, which need to run on GPUs to achieve low latency and improve the user experience. Miguel Ferreira works as a Sr.
In today’s blog, we will see some very interesting Python Machine Learning projects with source code. This list will consist of Machine learning projects, DeepLearning Projects, Computer Vision Projects , and all other types of interesting projects with source codes also provided.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. PyAnnote is an open source toolkit written in Python for speaker diarization. This post delves into integrating Hugging Face’s PyAnnote for speaker diarization with Amazon SageMaker asynchronous endpoints.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content