This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
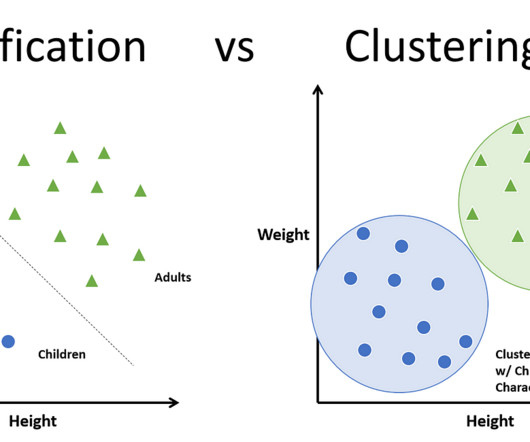
Definitely not. This is where the organization part comes in— by categorizing the brands as a whole or taking a more […] The post Classification vs. Clustering- Which One is Right for Your Data? Introduction Imagine walking into a shopping mall with hundreds of brands and products, all jumbled up and randomly placed in the shops.
In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance time by half. The major components of RELand are illustrated in Fig.
Improve Cluster Balance with CPD Scheduler — Part 2 The default Kubernetes scheduler has some limitations that cause unbalanced clusters. In an unbalanced cluster, some of the worker nodes are overloaded and others are under-utilized. we will use “cluster balance” and “resource usage balance” interchangeably.
Revolutionizing the way we organize the data, Databricks introduced a game-changer called Liquid Clustering in this year’s Data + AI Summit. An innovative feature that redefines the boundaries of partitioning and clustering for Delta tables. Writing data to a clustered table — Most operations do not automatically cluster data on write.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The AML feature store standardizes variable definitions using scientifically validated algorithms.
Simple Random Sampling Definition and Overview Simple random sampling is a technique in which each member of the population has an equal chance of being selected to form the sample. Select clusters randomly from the population. Include all members within the chosen clusters in the sample. Analyze the obtained sample data.
ACK allows you to take advantage of managed model building pipelines without needing to define resources outside of the Kubernetes cluster. This configuration takes the form of a Directed Acyclic Graph (DAG) represented as a JSON pipeline definition. kubectl for working with Kubernetes clusters. yq for YAML processing.
Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. Delete the MongoDB Atlas cluster. Solution overview The following diagram illustrates the solution architecture. Set up the database access and network access. Delete the Lambda function.
ClusteringClustering groups similar data points based on their attributes. One common example is k-means clustering, which segments data into distinct groups for analysis. Classification Classification techniques, including decision trees, categorize data into predefined classes.
You definitely need to embrace more advanced approaches if you have to: process large amounts of data from different sources find complex hidden relationships between them make forecasts detect unusual patterns, etc. Clustering. ?lustering These tools help companies boost productivity , reduce costs and achieve other objectives.
With containers, scaling on a cluster becomes much easier. Solution overview We walk you through the following high-level steps: Provision an ECS cluster of Trn1 instances with AWS CloudFormation. Create a task definition to define an ML training job to be run by Amazon ECS. Run the ML task on Amazon ECS.
Definition and overview of predictive modeling At its core, predictive modeling involves creating a model using historical data that can predict future events. They often play a crucial role in clustering and segmenting data, helping businesses identify trends without prior knowledge of the outcome.
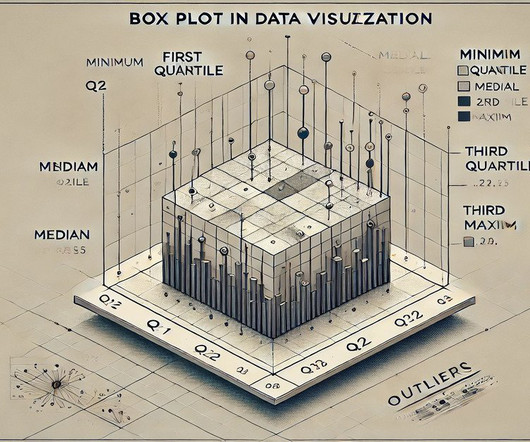
This article will explore the definition of a Box Plot, its essential components, and the formulas used in creating it. Definition of a Box Plot The definition of a Box Plot centres around its ability to show variability in data distribution. Box Plots help detect patterns by showing how data clusters around the median.
VS Code desktop integration lets data scientists use a familiar IDE to run and debug code that runs on the Cloud Pak for Data cluster. It allows use of VS Code desktop as the UI to run and debug code inside Python runtime environments in projects on the Cloud Pak for Data cluster. New in Cloud Pak for Data 4.6,
How Clustering Can Help You Understand Your Customers Better Customer segmentation is crucial for businesses to better understand their customers, target marketing efforts, and improve satisfaction. Clustering, a popular machine learning technique, identifies patterns in large datasets to group similar customers and gain insights.
Photo by Aditya Chache on Unsplash DBSCAN in Density Based Algorithms : Density Based Spatial Clustering Of Applications with Noise. Earlier Topics: Since, We have seen centroid based algorithm for clustering like K-Means.Centroid based : K-Means, K-Means ++ , K-Medoids. & One among the many density based algorithms is “DBSCAN”.
Tableau Data Types: Definition, Usage, and Examples Tableau has become a game-changer in the world of data visualization. Summary Table: Data Type in Tableau Data Type Definition Example Common Use Case String Textual characters “Customer Name” Categorizing data, adding labels Numerical Numbers (integers & decimals) 123.45
Cluster Analysis. Cluster analysis or clustering is an unsupervised learning method that groups objects in such a way that objects in the same group (a cluster) are more similar to each other than to those in other groups (clusters). Unlike personas, however, cluster analysis is data-driven.
To solve this, check out my article comparing Late Chunking to Contextual Retrieval, a method popularized by Anthropic to add context to chunks with LLMs:[link] In practice, what this does instead is reduce the number of failed retrievals, and clusters chunk embeddings around the document. Image By Author.
Here I’ll show you a convenient method for discovering and understanding clusters of text documents. If you are dealing with a large collections of documents, you will often find yourself in the situation where you are looking for some structure and understanding what is contained in the documents.
Our suite of managed integrations offers APIs to automate cluster setup and management: Domains : Link a custom domain to your cluster’s load balancer by using (CIS). Use these actions to streamline your cluster management. An ALB is automatically created for each public zone in the cluster. Create an ALB.
Clustering and other applications Other applications of our aggregation method are clustering and learning the covariance matrix of a Gaussian distribution. Consider the use of FriendlyCore to develop a differentially private k-means clustering algorithm. We compared the clustering algorithms for varying k.
But those end users werent always clear on which data they should use for which reports, as the data definitions were often unclear or conflicting. The promise of Hadoop was that organizations could securely upload and economically distribute massive batch files of any data across a cluster of computers.
First, we administered the Wisconsin Cards Sorting Test (WCST; a neuropsychological test probing cognitive flexibility) to 162 SSD patients and 108 healthy control participants, and we computed the clinical behavioural data with a data-driven clustering algorithm.
Instead of relying on predefined, rigid definitions, our approach follows the principle of understanding a set. Its important to note that the learned definitions might differ from common expectations. Instead of relying solely on compressed definitions, we provide the model with a quasi-definition by extension.
The feature space reduction is performed by aggregating clusters of features of balanced size. This clustering is usually performed using hierarchical clustering. The idea is to sort the labels into clusters to create a meta-label space.
Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster. Also, this connector contains the functionality to automatically load feature definitions to help with creating feature groups. To do so, open the notebook 4b-processing-rs-to-fs.ipynb in your SageMaker Studio environment.
An EMR cluster with EMR runtime roles enabled. Associating runtime roles with EMR clusters is supported in Amazon EMR 6.9. The EMR cluster should be created with encryption in transit. internal in the certificate subject definition. If your cluster resides in us-west-2 , you could specify CN=*.us-west-2.compute.internal.
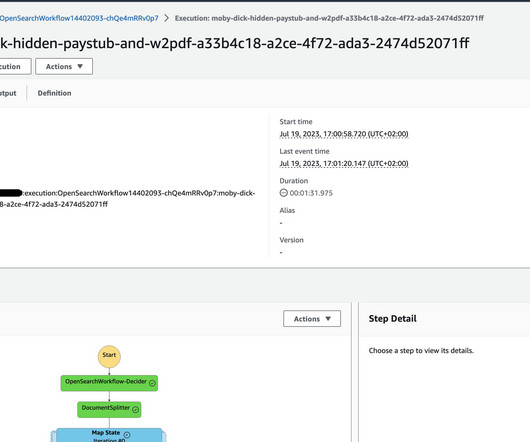
The IDP CDK constructs and samples are a collection of components to enable definition of IDP processes on AWS and published to GitHub. Another metrics to monitor is the health of the OpenSearch cluster, which you should setup according to the Opernational best practices for Amazon OpenSearch Service.
__version__ Let's try clustering a sample dataset and compare the runtime of clustering functions by running it with CPU and then with GPU. host_data = device_data.get() host_labels = device_labels.get() Running KMeans clustering on CPU. . Hope you will definitely give it a try. Import the packages. The CPU took 5.15
So a 2500 core testing cluster is small potatoes!” We have a 2500 core cluster dedicated to running over 75M tests per week so that the hundreds of developers working on these codes can continue to deliver new versions all day long. So a 2500 core testing cluster is small potatoes! Definitely!
It optimises decision trees, probabilistic models, clustering, and reinforcement learning. Entropy enhances clustering, federated learning, finance, and bioinformatics. Lets delve into its mathematical definition and key properties. Lets explore its definition, connection to entropy, and practical applications.
Digitization definitely helps here — where you use algorithms and past data to schedule jobs and dispatch relevant field service technicians for the same. It does so by clustering service calls in the same geographic area and sequencing them logically. This also makes your operations susceptible to human error.
Amazon ECS configuration For Amazon ECS, create a task definition that references your custom Docker image. dkr.ecr.amazonaws.com/ : ", "essential": true, "name": "training-container", } ] } This definition sets up a task with the necessary configuration to run your containerized application in Amazon ECS. Delete your ECS cluster.
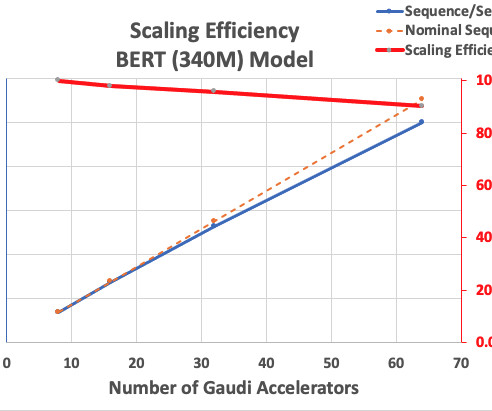
Training setup We provisioned a managed compute cluster comprised of 16 dl1.24xlarge instances using AWS Batch. We developed an AWS Batch workshop that illustrates the steps to set up the distributed training cluster with AWS Batch. The distributed training workshop illustrates the steps to set up the distributed training cluster.
Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. Here’s a brief overview: Function Definitions: main : Takes a dataset and a question as input, initializes a RetrievalQA chain, retrieves the answer, and formats it for display.
Each component or BIAN Service Domain is implemented through a microservice, which is deployed on an OCP cluster on IBM Cloud. The IBM Cloud for Financial Services deployment was achieved in a secure landing zone cluster, and infrastructure deployment is also automated using policy as code ( terraform ).
Connection definition JSON file When connecting to different data sources in AWS Glue, you must first create a JSON file that defines the connection properties—referred to as the connection definition file. The following is a sample connection definition JSON for Snowflake.
To demonstrate this value proposition end-to-end, an exemplar vision-transformer-based foundation model for civil infrastructure (pre-trained using public and custom industry-specific datasets) was fine-tuned and deployed for inference on a three-node edge (spoke) cluster.
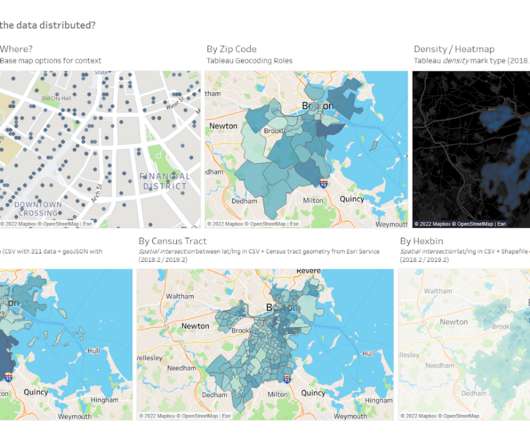
By definition, spatial data has location , so the first step to understanding the data is putting it on a map to see where it’s located. Or are there clusters of points? Where is the spatial data located and how is it distributed? . How are locations related to one another? Where is the spatial data located and how is it distributed?
The process of statistical modelling involves the following steps: Problem Definition: Here, you clearly define the research question first that you want to address using statistical modeling. This could be linear regression, logistic regression, clustering , time series analysis , etc.
Kafka clusters can be automatically scaled based on demand, with full encryption and access control. For disaster recovery, the geo-replication feature can create copies of event data to send to a backup cluster, with the user interface making this configurable in a few clicks.
Patrick Lewis “We definitely would have put more thought into the name had we known our work would become so widespread,” Lewis said in an interview from Singapore, where he was sharing his ideas with a regional conference of database developers.
I know similarities languages are not the sole and definite barometers of effectiveness in learning foreign languages. In this case, original data distribution have two clusters of circles and triangles and a clear border can be drawn between them. this might be natural as clusters of data can be estimated with unsupervised learning.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content