
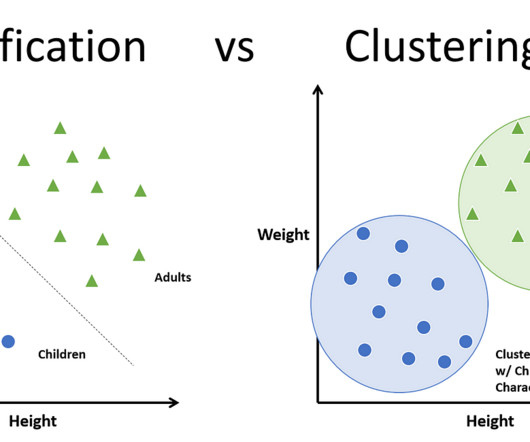
Classification vs. Clustering- Which One is Right for Your Data?
Analytics Vidhya
MAY 22, 2023
Definitely not. This is where the organization part comes in— by categorizing the brands as a whole or taking a more […] The post Classification vs. Clustering- Which One is Right for Your Data? Introduction Imagine walking into a shopping mall with hundreds of brands and products, all jumbled up and randomly placed in the shops.


















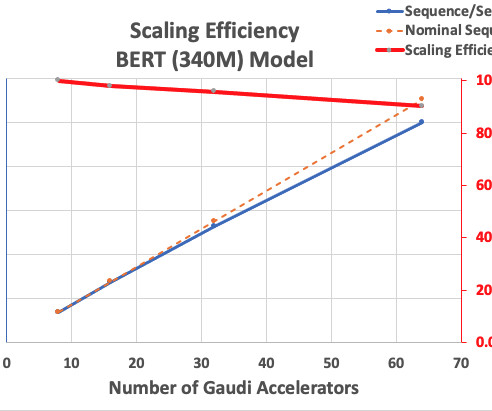
























Let's personalize your content