This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ClusteringClustering groups similar data points based on their attributes. One common example is k-means clustering, which segments data into distinct groups for analysis. Decision trees and K-nearestneighbors (KNN) Both decision trees and KNN play vital roles in classification and prediction.
Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. MongoDB Atlas Vector Search uses a technique called k-nearestneighbors (k-NN) to search for similar vectors. k-NN works by finding the k most similar vectors to a given vector.
Definition and importance of machine learning algorithms The core value of machine learning algorithms lies in their capacity to process and analyze vast amounts of data efficiently. Common types include: K-means clustering: Groups similar data points together based on specific metrics.
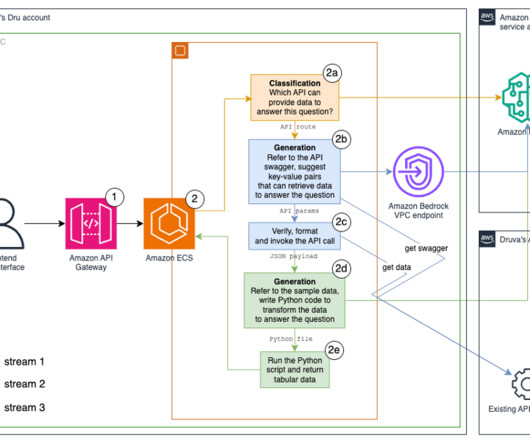
We tried different methods, including k-nearestneighbor (k-NN) search of vector embeddings, BM25 with synonyms , and a hybrid of both across fields including API routes, descriptions, and hypothetical questions. The request arrives at the microservice on our existing Amazon Elastic Container Service (Amazon ECS) cluster.
Instead of relying on predefined, rigid definitions, our approach follows the principle of understanding a set. Its important to note that the learned definitions might differ from common expectations. Instead of relying solely on compressed definitions, we provide the model with a quasi-definition by extension.
The prediction is then done using a k-nearestneighbor method within the embedding space. The feature space reduction is performed by aggregating clusters of features of balanced size. This clustering is usually performed using hierarchical clustering.
K-NearestNeighborK-nearestneighbor (KNN) ( Figure 8 ) is an algorithm that can be used to find the closest points for a data point based on a distance measure (e.g., Figure 8: K-nearestneighbor algorithm (source: Towards Data Science ). Several clustering algorithms (e.g.,
Now the key insight that we had in solving this is that we noticed that unseen concepts are actually well clustered by pre-trained deep learning models or foundation models. And effectively in the latent space, they form kind of tight clusters for these unseen concepts that are very well-connected components. of the unlabeled data.
Now the key insight that we had in solving this is that we noticed that unseen concepts are actually well clustered by pre-trained deep learning models or foundation models. And effectively in the latent space, they form kind of tight clusters for these unseen concepts that are very well-connected components. of the unlabeled data.
Now the key insight that we had in solving this is that we noticed that unseen concepts are actually well clustered by pre-trained deep learning models or foundation models. And effectively in the latent space, they form kind of tight clusters for these unseen concepts that are very well-connected components. of the unlabeled data.
This can lead to enhancing accuracy but also increasing the efficiency of downstream tasks such as classification, retrieval, clusterization, and anomaly detection, to name a few. This can lead to higher accuracy in tasks like image classification and clusterization due to the fact that noise and unnecessary information are reduced.
The sub-categories of this approach are negative sampling, clustering, knowledge distillation, and redundancy reduction. Some common quantitative evaluations are linear probing , Knearestneighbors (KNN), and fine-tuning. They have done a very comprehensive study regarding this topic so lot of things we can talk about.
Key steps involve problem definition, data preparation, and algorithm selection. Clustering and dimensionality reduction are common tasks in unSupervised Learning. For example, clustering algorithms can group customers by purchasing behaviour, even if the group labels are not predefined. For unSupervised Learning tasks (e.g.,
There are majorly two categories of sampling techniques based on the usage of statistics, they are: Probability Sampling techniques: Clustered sampling, Simple random sampling, and Stratified sampling. The K-NearestNeighbor Algorithm is a good example of an algorithm with low bias and high variance.
Definition and structure of feature vectors A feature vector contains numerical values that represent the attributes of an observed phenomenon. This can be useful in clustering algorithms where distance metrics help define groups. Each feature corresponds to a specific measurable element, allowing for detailed comparative analysis.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content