This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
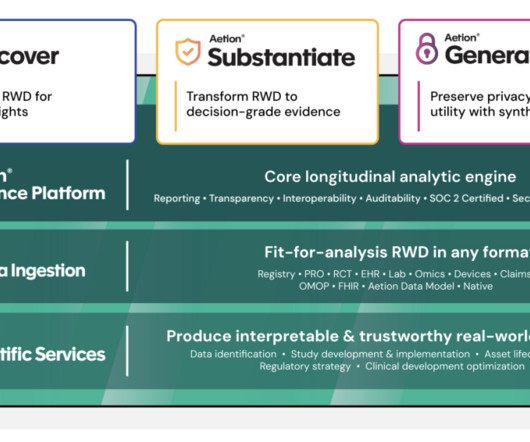
In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance time by half. RELand consistently outperforms the benchmark models on all relevant metrics.
This is why businesses are looking to leverage machine learning (ML). You definitely need to embrace more advanced approaches if you have to: process large amounts of data from different sources find complex hidden relationships between them make forecasts detect unusual patterns, etc. Top ML approaches to improve your analytics.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machine learning (ML) applications. Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. kubectl for working with Kubernetes clusters.
Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models. Amazon SageMaker JumpStart provides pre-trained models and data to help you get started with ML. Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster.
Let’s explore the specific role and responsibilities of a machine learning engineer: Definition and scope of a machine learning engineer A machine learning engineer is a professional who focuses on designing, developing, and implementing machine learning models and systems.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The AML feature store standardizes variable definitions using scientifically validated algorithms.
Running machine learning (ML) workloads with containers is becoming a common practice. What you get is an ML development environment that is consistent and portable. With containers, scaling on a cluster becomes much easier. Create a task definition to define an ML training job to be run by Amazon ECS.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. Machine learning(ML) is evolving at a very fast pace. Photo by Andrea De Santis on Unsplash So, What is Machine Learning?
Snowpark ML is transforming the way that organizations implement AI solutions. Snowpark allows ML models and code to run on Snowflake warehouses. By “bringing the code to the data,” we’ve seen ML applications run anywhere from 4-100x faster than other architectures.
As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale. Supporting the operations of data scientists and ML engineers requires you to reduce—or eliminate—the engineering overhead of building, deploying, and maintaining high-performance models.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. What does a modern technology stack for streamlined ML processes look like?
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
This allows machine learning (ML) practitioners to rapidly launch an Amazon Elastic Compute Cloud (Amazon EC2) instance with a ready-to-use deep learning environment, without having to spend time manually installing and configuring the required packages. You also need the ML job scripts ready with a command to invoke them.
SageMaker provides single model endpoints (SMEs), which allow you to deploy a single ML model, or multi-model endpoints (MMEs), which allow you to specify multiple models to host behind a logical endpoint for higher resource utilization. About the Authors Melanie Li is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia.
What Zeta has accomplished in AI/ML In the fast-evolving landscape of digital marketing, Zeta Global stands out with its groundbreaking advancements in artificial intelligence. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
As a result, poor code quality and reliance on manual workflows are two of the main issues in ML development processes. Using the following three principles helps you build a mature ML development process: Establish a standard repository structure you can use as a scaffold for your projects. What is a mature ML development process?
Tens of thousands of AWS customers use AWS machine learning (ML) services to accelerate their ML development with fully managed infrastructure and tools. Cluster resources are provisioned for the duration of your job, and cleaned up when a job is complete. You can easily extend this solution to add more functionality.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. Second, open source Metaflow provides the necessary software infrastructure to build production-grade ML/AI systems in a developer-friendly manner.
How Clustering Can Help You Understand Your Customers Better Customer segmentation is crucial for businesses to better understand their customers, target marketing efforts, and improve satisfaction. Clustering, a popular machine learning technique, identifies patterns in large datasets to group similar customers and gain insights.
Solution overview To demonstrate container-based GPU metrics, we create an EKS cluster with g5.2xlarge instances; however, this will work with any supported NVIDIA accelerated instance family. Create an EKS cluster with a node group This group includes a GPU instance family of your choice; in this example, we use the g5.2xlarge instance type.
This mindset has followed me into my work in ML/AI. Because if companies use code to automate business rules, they use ML/AI to automate decisions. Given that, what would you say is the job of a data scientist (or ML engineer, or any other such title)? But first, let’s talk about the typical ML workflow.
Photo by Aditya Chache on Unsplash DBSCAN in Density Based Algorithms : Density Based Spatial Clustering Of Applications with Noise. Earlier Topics: Since, We have seen centroid based algorithm for clustering like K-Means.Centroid based : K-Means, K-Means ++ , K-Medoids. & One among the many density based algorithms is “DBSCAN”.
Instead of relying on predefined, rigid definitions, our approach follows the principle of understanding a set. Its important to note that the learned definitions might differ from common expectations. Instead of relying solely on compressed definitions, we provide the model with a quasi-definition by extension.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. Account A is the data lake account that houses all the ML-ready data obtained through extract, transform, and load (ETL) processes. An EMR cluster with EMR runtime roles enabled. compute.internal.
Training setup We provisioned a managed compute cluster comprised of 16 dl1.24xlarge instances using AWS Batch. We developed an AWS Batch workshop that illustrates the steps to set up the distributed training cluster with AWS Batch. The distributed training workshop illustrates the steps to set up the distributed training cluster.
The IDP CDK constructs and samples are a collection of components to enable definition of IDP processes on AWS and published to GitHub. Another metrics to monitor is the health of the OpenSearch cluster, which you should setup according to the Opernational best practices for Amazon OpenSearch Service.
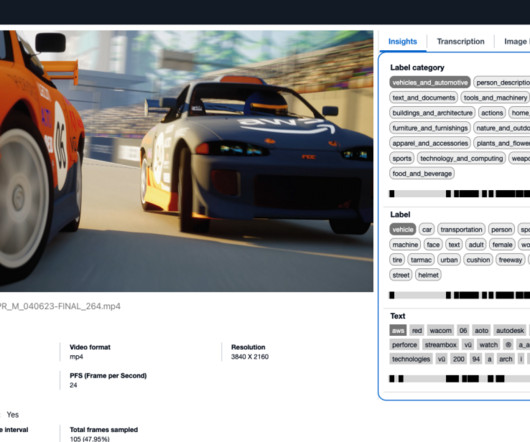
An Amazon OpenSearch Service cluster stores the extracted video metadata and facilitates users’ search and discovery needs. Building a robust solution to extract information from videos poses challenges from both machine learning (ML) and engineering perspectives. Classify the video into IAB categories.
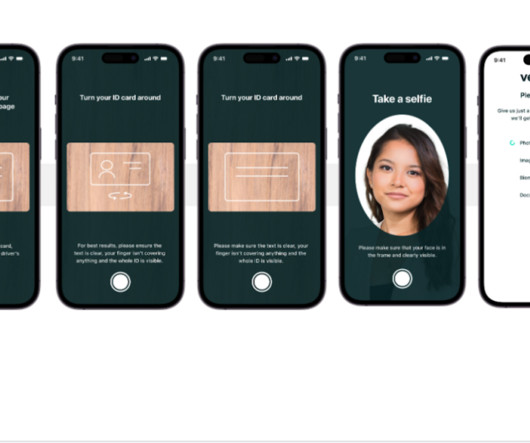
As an AI-powered solution, Veriff needs to create and run dozens of machine learning (ML) models in a cost-effective way. Infrastructure and development challenges Veriff’s backend architecture is based on a microservices pattern, with services running on different Kubernetes clusters hosted on AWS infrastructure.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them.
Text representation with Embed – Developers can access endpoints that capture the semantic meaning of text, enabling applications such as vector search engines, text classification and clustering, and more. Next, you set up a Weaviate cluster. Subscribe to the Weaviate Kubernetes Cluster on AWS Marketplace.
This step-function instantiated a cluster of instances to extract and process data from S3 and the further steps of pre-processing, training, evaluation would run on a single large EC2 instance. This became a bottleneck in troubleshooting, adding, or removing a step, or even in making some small changes in the overall infrastructure.
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to Kyle Morris from Banana about deploying models on GPU. Kyle: Yes.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
You can integrate a Data Wrangler data preparation flow into your machine learning (ML) workflows to simplify data preprocessing and feature engineering, taking data preparation to production faster without the need to author PySpark code, install Apache Spark, or spin up clusters. He is very passionate about data-driven AI.
Foundational models (FMs) are marking the beginning of a new era in machine learning (ML) and artificial intelligence (AI) , which is leading to faster development of AI that can be adapted to a wide range of downstream tasks and fine-tuned for an array of applications. IBM watsonx consists of the following: IBM watsonx.ai
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. It plays a crucial role in every model’s development process and allows data scientists to focus on the most promising ML techniques. This logical grouping is required when creating the HPO job.
Amazon SageMaker distributed training jobs enable you with one click (or one API call) to set up a distributed compute cluster, train a model, save the result to Amazon Simple Storage Service (Amazon S3), and shut down the cluster when complete. We included the steps to achieve this in the last section of the notebook.
Machine learning (ML) is revolutionizing solutions across industries and driving new forms of insights and intelligence from data. Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed. What is federated learning?
This set of 3 numbers is a 3-dimensional representation or embedding for the visual quality (based on our definition) of the images. Training an Embedding Model Now that we know how to interpret embeddings let's see how we would go about training an ML model to generate embeddings.
Problem definition Traditionally, the recommendation service was mainly provided by identifying the relationship between products and providing products that were highly relevant to the product selected by the customer. Gonsoo Moon is an AWS AI/ML Specialist Solutions Architect and provides AI/ML technical support.
__version__ Let's try clustering a sample dataset and compare the runtime of clustering functions by running it with CPU and then with GPU. host_data = device_data.get() host_labels = device_labels.get() Running KMeans clustering on CPU. . Hope you will definitely give it a try. Import the packages. The CPU took 5.15
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content