This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
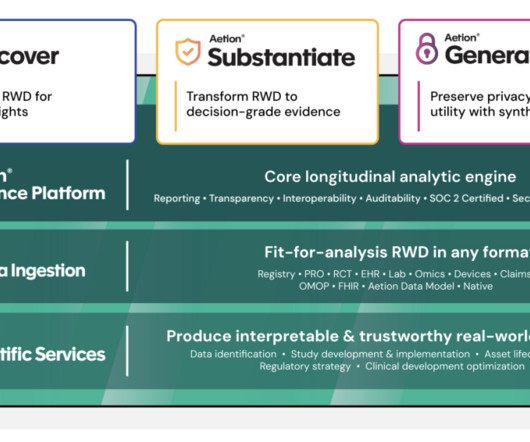
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The AML feature store standardizes variable definitions using scientifically validated algorithms.
Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. Delete the MongoDB Atlas cluster. Solution overview The following diagram illustrates the solution architecture. Set up the database access and network access. Delete the Lambda function.
Definition and overview of predictive modeling At its core, predictive modeling involves creating a model using historical data that can predict future events. They often play a crucial role in clustering and segmenting data, helping businesses identify trends without prior knowledge of the outcome.
Instead of relying on predefined, rigid definitions, our approach follows the principle of understanding a set. Its important to note that the learned definitions might differ from common expectations. Model invocation We use Anthropics Claude 3 Sonnet model for the naturallanguageprocessing task.
Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. Here’s a brief overview: Function Definitions: main : Takes a dataset and a question as input, initializes a RetrievalQA chain, retrieves the answer, and formats it for display.
Your data scientists develop models on this component, which stores all parameters, feature definitions, artifacts, and other experiment-related information they care about for every experiment they run. Machine Learning Operations (MLOps): Overview, Definition, and Architecture (by Kreuzberger, et al., AIIA MLOps blueprints.
Patrick Lewis “We definitely would have put more thought into the name had we known our work would become so widespread,” Lewis said in an interview from Singapore, where he was sharing his ideas with a regional conference of database developers. The concepts behind this kind of text mining have remained fairly constant over the years.
Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. Here’s a brief overview: Function Definitions: main : Takes a dataset and a question as input, initializes a RetrievalQA chain, retrieves the answer, and formats it for display.
Definition says, machine learning is the ability of computers to learn without explicit programming. Linear Regression Decision Trees Support Vector Machines Neural Networks Clustering Algorithms (e.g., Linear Regression Decision Trees Support Vector Machines Neural Networks Clustering Algorithms (e.g.,
Connection definition JSON file When connecting to different data sources in AWS Glue, you must first create a JSON file that defines the connection properties—referred to as the connection definition file. The following is a sample connection definition JSON for Snowflake.
It optimises decision trees, probabilistic models, clustering, and reinforcement learning. Entropy enhances clustering, federated learning, finance, and bioinformatics. Lets delve into its mathematical definition and key properties. Lets explore its definition, connection to entropy, and practical applications.
Large language models (LLMs) are a class of foundational models (FM) that consist of layers of neural networks that have been trained on these massive amounts of unlabeled data. Large language models (LLMs) have taken the field of AI by storm.
This characteristic is clearly observed in models in naturallanguageprocessing (NLP) and computer vision (CV) like in the graphs below. I know similarities languages are not the sole and definite barometers of effectiveness in learning foreign languages.
Data mining is the process of discovering these patterns among the data and is therefore also known as Knowledge Discovery from Data (KDD). Clustering. Another unsupervised learning method, clustering is the practice of assigning labels to unlabeled data using the patterns that exist in it.
Text representation with Embed – Developers can access endpoints that capture the semantic meaning of text, enabling applications such as vector search engines, text classification and clustering, and more. Cohere Embed comes in two forms, an English language model and a multilingual model, both of which are now available on Amazon Bedrock.
This section delves into its foundational definitions, types, and critical concepts crucial for comprehending its vast landscape. Deep Learning has been used to achieve state-of-the-art results in a variety of tasks, including image recognition, NaturalLanguageProcessing, and speech recognition.
Historically, naturallanguageprocessing (NLP) would be a primary research and development expense. In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows.
You can integrate a Data Wrangler data preparation flow into your machine learning (ML) workflows to simplify data preprocessing and feature engineering, taking data preparation to production faster without the need to author PySpark code, install Apache Spark, or spin up clusters. Choose Add Step and choose Custom Transform.
Run the @feature_processor code remotely In this section, we demonstrate running the feature processing code remotely as a Spark application using the @remote decorator described earlier. We run the feature processing remotely using Spark to scale to large datasets.
PBAs, such as graphics processing units (GPUs), have an important role to play in both these phases. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. With Inf1, they were able to reduce their inference latency by 25%, and costs by 65%.
Package model for inference – Using a processing job, if the evaluation results are positive, the model is packaged, stored in Amazon S3, and made ready for upload to the internal ML portal. His experience extends across different areas, including naturallanguageprocessing, generative AI and machine learning operations.
This can lead to enhancing accuracy but also increasing the efficiency of downstream tasks such as classification, retrieval, clusterization, and anomaly detection, to name a few. This can lead to higher accuracy in tasks like image classification and clusterization due to the fact that noise and unnecessary information are reduced.
GMMs are adequate for clustering and density estimation tasks. NaturalLanguageProcessing (NLP) In NLP , probabilistic models enhance text understanding and generation. In contrast, deterministic models provide a single, definitive outcome without considering variability.
Meanwhile, your friend Alex takes on the role of the decoder , selecting a location in the wardrobe and attempting to recreate (or, in technical terms) the clothing item (a process referred to as decoding ). time series or naturallanguageprocessing tasks).
Summary: This article compares Artificial Intelligence (AI) vs Machine Learning (ML), clarifying their definitions, applications, and key differences. Definition of AI AI refers to developing computer systems that can perform tasks that require human intelligence. It is often used for clustering data into meaningful categories.
A lot of people are building truly new things with Large Language Models (LLMs), like wild interactive fiction experiences that weren’t possible before. But if you’re working on the same sort of NaturalLanguageProcessing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them?
In this solution, we train and deploy a churn prediction model that uses a state-of-the-art naturallanguageprocessing (NLP) model to find useful signals in text. We define the objective metric name, metric definition (with regex pattern), and objective type for the tuning job.
Options (Free vs Paid) Closing Introduction In today’s increasingly globalized world, the ability to communicate in multiple languages has become a highly valuable skill. Language Models (LLMs) have revolutionized the field of naturallanguageprocessing, bringing unprecedented advancements in understanding and generating human-like text.
We don’t claim this is a definitive analysis but rather a rough guide due to several factors: Job descriptions show lagging indicators of in-demand prompt engineering skills, especially when viewed over the course of 9 months. The definition of a particular job role is constantly in flux and varies from employer to employer.
It also includes the mapping definition to construct the input for the specified AI service. Currently, he builds and supports an on-premises data center cluster built for AI training and also designs and builds cloud solutions for the company’s future of AI research and deployment.
This article explores the definitions of Data Science and AI, their current applications, how they are shaping the future, challenges they present, future trends, and the skills required for careers in these fields. Machine Learning Expertise Familiarity with a range of Machine Learning algorithms is crucial for Data Science practitioners.
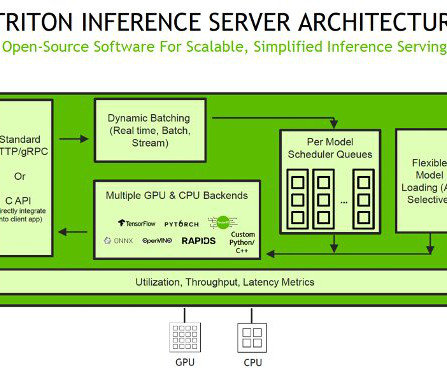
Triton supports a heterogeneous cluster with both GPUs and CPUs, which helps standardize inference across platforms and dynamically scales out to any CPU or GPU to handle peak loads. SageMaker provides Triton via SMEs and MMEs SageMaker enables you to deploy both single and multi-model endpoints with Triton Inference Server.
spaCy is a new library for text processing in Python and Cython. I wrote it because I think small companies are terrible at naturallanguageprocessing (NLP). The only problem is that the list really contains two clusters of words: one associated with the legal meaning of “pleaded”, and one for the more general sense.
Key steps involve problem definition, data preparation, and algorithm selection. Clustering and dimensionality reduction are common tasks in unSupervised Learning. For example, clustering algorithms can group customers by purchasing behaviour, even if the group labels are not predefined. For a regression problem (e.g.,
Accordingly, there are many Python libraries which are open-source including Data Manipulation, Data Visualisation, Machine Learning, NaturalLanguageProcessing , Statistics and Mathematics. After that, move towards unsupervised learning methods like clustering and dimensionality reduction.
We’ve been running Explosion for about five years now, which has given us a lot of insights into what NaturalLanguageProcessing looks like in industry contexts. Or cluster them first, and see if the clustering ends up being useful to determine who to assign a ticket to? How should you allocate your points?
I’m a data scientist at Capital One on the EP2ML (enterprise product and platforms) team where I’m focusing on the naturallanguage understanding and naturallanguageprocessing (NLUNOP) capabilities of our virtual assistant Eno, or chatbot. In reality, you have evolving task definitions.
I’m a data scientist at Capital One on the EP2ML (enterprise product and platforms) team where I’m focusing on the naturallanguage understanding and naturallanguageprocessing (NLUNOP) capabilities of our virtual assistant Eno, or chatbot. In reality, you have evolving task definitions.
We need, for example, less models for a number of NLP (naturallanguageprocessing) tasks in the enterprise. These embeddings then fell downstream through traditional ML pipelines for clustering, for identification, and then prioritization of compounds that may be therapeutically relevant.
Stephen: Yeah, absolutely, we’ll definitely delve into that. In general, it’s a large language model, not altogether that different from language machine learning models we’ve seen in the past that do various naturallanguageprocessing tasks. So there’s a ton of opportunities.
For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly. Apache Hadoop Apache Hadoop is an open-source framework that supports the distributed processing of large datasets across clusters of computers.
Deep learning became the new focus, first led by the advance in computer vision, then followed by naturallanguageprocessing. For example, it could adapt to different definitions of the shared vocabulary between the general domain and the specific domain. Now, roughly a decade later, the first shift had happened.
Up-to-date knowledge about naturallanguageprocessing is mostly locked away in academia. You should use two tags of history, and features derived from the Brown word clusters distributed here. And it definitely doesn’t matter enough to adopt a slow and complicated algorithm like Conditional Random Fields.
Create better access to health with machine learning and naturallanguageprocessing. Clustering health aspects ? If you’re interested to learn more, you should definitely check out Lj’s blog post about the spaCy config and spaCy projects ?. To improve the search, it’s a good idea to cluster aspects together.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content