This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When storing a vector index for your knowledge base in an Aurora database cluster, make sure that the table for your index contains a column for each metadata property in your metadata files before starting data ingestion.
For this demo we are using employee sample data csv file which is uploaded in colab’s environment. Creating vectorstore For this demonstration, we are going to use FAISS vectorstore. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors.
It is used for machine learning, naturallanguageprocessing, and computer vision tasks. Explore the top 10 machine learning demos and discover cutting-edge techniques that will take your skills to the next level. It has a large and active community of users and developers who can provide support and help.
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. For example, let’s say you had a collection of customer emails or online product reviews.
For this demo we are using employee sample data csv file which is uploaded in colab’s environment. CREATING VECTORSTORE For this demonstration, we are going to use FAISS vectorstore. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors.
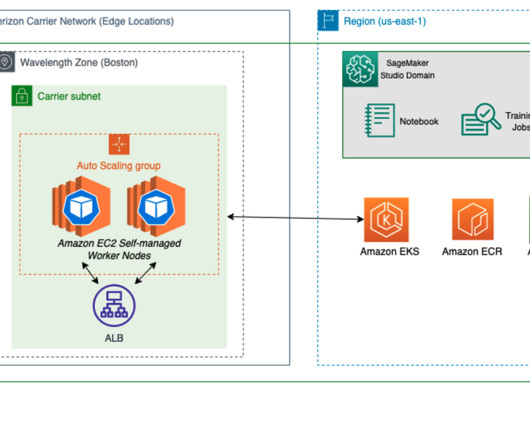
Retailers can deliver more frictionless experiences on the go with naturallanguageprocessing (NLP), real-time recommendation systems, and fraud detection. To learn more about deploying geo-distributed applications on AWS Wavelength, refer to Deploy geo-distributed Amazon EKS clusters on AWS Wavelength. Choose Manage.
We also demonstrate how you can engineer prompts for Flan-T5 models to perform various naturallanguageprocessing (NLP) tasks. Task Prompt (template in bold) Model output Summarization Briefly summarize this paragraph: Amazon Comprehend uses naturallanguageprocessing (NLP) to extract insights about the content of documents.
Photo by adrianna geo on Unsplash NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.23.20 They fine-tuned BERT, RoBERTa, DistilBERT, ALBERT, XLNet models on siamese/triplet network structure to be used in several tasks: semantic textual similarity, clustering, and semantic search. Let’s recap.
or GPT-4 arXiv, OpenAlex, CrossRef, NTRS lgarma Topic clustering and visualization, paper recommendation, saved research collections, keyword extraction GPT-3.5 Currently, published research may be spread across a variety of different publishers, including free and open-source ones like those used in many of this challenge's demos (e.g.
In this solution, we train and deploy a churn prediction model that uses a state-of-the-art naturallanguageprocessing (NLP) model to find useful signals in text. Demo notebook. You can use the demo notebook to send example data to already-deployed model endpoints.
Through multi-round dialogues, we highlight the capabilities of instruction-oriented zero-shot and few-shot vision languageprocessing, emphasizing its versatility and aiming to capture the interest of the broader multimodal community. The demo implementation code is available in the following GitHub repo.
Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable. It has intuitive helpers and utilities for modalities like computer vision, naturallanguageprocessing, audio, time series, and tabular data.
In this demo, we use a Jumpstart Flan T5 XXL model endpoint. His research interests are in the area of naturallanguageprocessing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. To further explore LangChain capabilities, refer to the LangChain documentation.
Text splitting is breaking down a long document or text into smaller, manageable segments or “chunks” for processing. This is widely used in NaturalLanguageProcessing (NLP), where it plays a pivotal role in pre-processing unstructured textual data. Below is what the input text data looks like.
Generative language models have proven remarkably skillful at solving logical and analytical naturallanguageprocessing (NLP) tasks. We use Cohere Command and AI21 Labs Jurassic-2 Mid for this demo. DynamoDB table An application running on AWS uses an Amazon Aurora Multi-AZ DB cluster deployment for its database.
This keynote will also include a live demo of transfer learning and deployment of a transformer model using Hugging Face and MLRun; showcasing how to make the whole process efficient, effective, and collaborative. This is the perfect place to witness the latest developments and advancements in the field of generative AI and beyond.
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
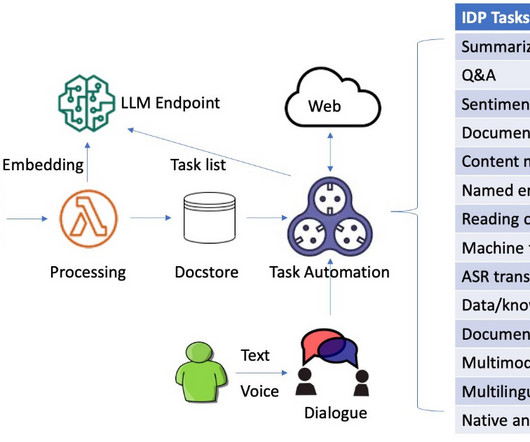
Naturallanguageprocessing (NLP) is one of the recent developments in IDP that has improved accuracy and user experience. As an alternative, you can use FAISS , an open-source vector clustering solution for storing vectors. However, despite these advances, there are still challenges to overcome.
The startup cost is now lower to deploy everything from a GPU-enabled virtual machine for a one-off experiment to a scalable cluster for real-time model execution. An example of the Concept to Clinic demo application, which is the kind of user-facing tool that the open source community does not build and maintain on its own.
In general, it’s a large language model, not altogether that different from language machine learning models we’ve seen in the past that do various naturallanguageprocessing tasks. A lot of them are demos at that point, they’re still not products. There are lots of demos out there.
For example, if your team works on recommender systems or naturallanguageprocessing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases. It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring.
Create better access to health with machine learning and naturallanguageprocessing. Clustering health aspects ? We also have some cool Healthsea demos hosted on Hugging Face spaces ? that visualize the individual processing steps of the pipeline and also its results on real data. ? Clausecat component 2.2
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
We ask this during product demos, user and support calls, and on our MLOps LIVE podcast. Orchestrators are concerned with lower-level abstractions like machines, instances, clusters, service-level grouping, replication, and so on. Why are you building an ML platform? Let’s look at the healthcare vertical for context.
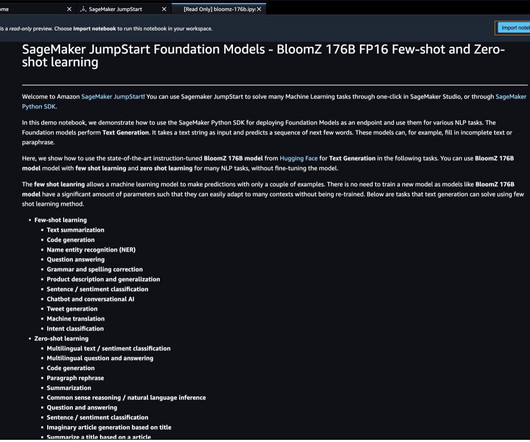
In this post and accompanying notebook, we demonstrate how to deploy the BloomZ 176B foundation model using the SageMaker Python simplified SDK in Amazon SageMaker JumpStart as an endpoint and use it for various naturallanguageprocessing (NLP) tasks. You can also access the foundation models thru Amazon SageMaker Studio.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content