This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Atlas is a multi-cloud database service provided by MongoDB in which the developers can create clusters, databases and indexes directly in the cloud, without installing anything locally. Get Started with Atlas MongoDB Atlas After the Cluster has been created, its time to create a Database and a collection. What is MongoDB Atlas?
When storing a vector index for your knowledge base in an Aurora database cluster, make sure that the table for your index contains a column for each metadata property in your metadata files before starting data ingestion. The response only cites sources that are relevant to the query.
All of these techniques center around product clustering, where product lines or SKUs that are “closer” or more similar to each other are clustered and modeled together. Clustering by product group. The most intuitive way of clustering SKUs is by their product group. Clustering by sales profile.
It is similar to TensorFlow, but it is designed to be more Pythonic. Scikit-learn Scikit-learn is an open-source machine learning library for Python. Explore the top 10 machine learning demos and discover cutting-edge techniques that will take your skills to the next level. It is open-source, so it is free to use and modify.
As attendees circulate through the GAIZ, subject matter experts and Generative AI Innovation Center strategists will be on-hand to share insights, answer questions, present customer stories from an extensive catalog of reference demos, and provide personalized guidance for moving generative AI applications into production.
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml Enter a stack name, such as Demo-Redshift. You should see a new CloudFormation stack with the name Demo-Redshift being created. yaml locally.
How to Implement Text Splitting in Snowflake Using SQL and Python UDFs We will now demonstrate how to implement the types of Text Splitting we explained in the above section in Snowflake. This process is repeated until the entire text is divided into coherent segments. The below flow diagram illustrates this process.
You can also access JumpStart models using the SageMaker Python SDK. The AWS CDK is an open-source software development framework to define your cloud application resources using familiar programming languages like Python. Prerequisites You must have the following prerequisites: An AWS account The AWS CLI v2 Python 3.6
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
You can use the new inference capabilities from Amazon SageMaker Studio , the SageMaker Python SDK , AWS SDKs , and AWS Command Line Interface (AWS CLI). Prerequisites To follow along, you should have a Kubernetes cluster with the SageMaker ACK controller v1.2.9 They are also supported by AWS CloudFormation. or above installed.
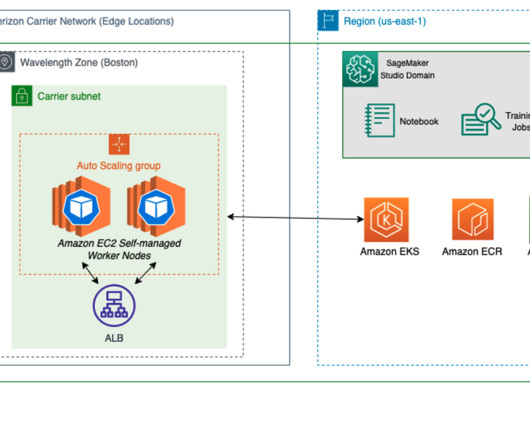
To learn more about deploying geo-distributed applications on AWS Wavelength, refer to Deploy geo-distributed Amazon EKS clusters on AWS Wavelength. Note that this integration is only available in us-east-1 and us-west-2 , and you will be using us-east-1 for the duration of the demo. The following diagram illustrates this architecture.
Data overview and preparation You can use a SageMaker Studio notebook with a Python 3 (Data Science) kernel to run the sample code. For demo purposes, we use approximately 1,600 products. We use the first metadata file in this demo. We use a pretrained ResNet-50 (RN50) model in this demo. path local_data_root = f'.
Right now, most deep learning frameworks are built for Python, but this neglects the large number of Java developers and developers who have existing Java code bases they want to integrate the increasingly powerful capabilities of deep learning into. For this reason, many DJL users also use it for inference only. With v0.21.0
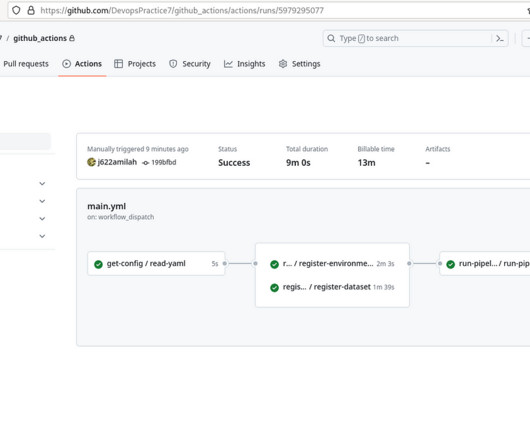
One aspect of this Data Science exam experience that I thought was lacking, was doing a complete MLOps workflow using GitHub Actions in addition to the Python SDK. yml script to configure a virtual machine to run the training script on, [2] running the scripts using GitHub Actions instead of with the azureml python SDK. csv data files.
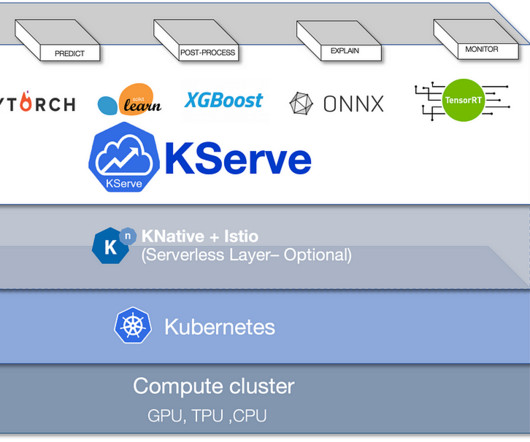
Setting Up KServe To demo the Hugging Face model on KServe we’ll use the local (Windows OS) quick install method on a minikube kubernetes cluster. The standalone “quick install” installs Istio and KNative for us without having to install all of Kubeflow and the extra components that tend to slow down local demo installs.
SageMaker Profiler provides Python modules for annotating PyTorch or TensorFlow training scripts and activating SageMaker Profiler. The need for profiling training jobs With the rise of deep learning (DL), machine learning (ML) has become compute and data intensive, typically requiring multi-node, multi-GPU clusters.
I realized that the algorithm assumes that we like a particular genre and artist and groups us into these clusters, not letting us discover and experience new music. You can check a live demo of the app using the link below: Spotify Reccomendation BECOME a WRITER at MLearning.ai // invisible ML // 800+ AI tools Mlearning.ai
The demo implementation code is available in the following GitHub repo. TGI is implemented in Python and uses the PyTorch framework. The Python utility script dino_sam_inpainting.py The VLP pipeline can be implemented using a Python-based workflow pipeline or alternative orchestration utilities. box_threshold=0.5,
They fine-tuned BERT, RoBERTa, DistilBERT, ALBERT, XLNet models on siamese/triplet network structure to be used in several tasks: semantic textual similarity, clustering, and semantic search. I tend to view LIT as an ML demo on steroids for prototyping. Broadcaster Stream API Fast.ai They also provide code to train your own models ?
Amazon Titan Text Embeddings is a text embeddings model that converts natural language text—consisting of single words, phrases, or even large documents—into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
We frequently see this with LLM users, where a good LLM creates a compelling but frustratingly unreliable first demo, and engineering teams then go on to systematically raise quality. Python code that calls an LLM), or should it be driven by an AI model (e.g. Systems can be dynamic. LLM agents that call external tools)?
Input context length for each table’s schema for demo is between 2,000–4,000 tokens. Currently, the AWS CDK supports TypeScript, JavaScript, Python, Java, C#, and Go. It includes column names, data type, distinct values, relationships, and more. AWS CDK stacks We used the AWS CDK to provision all the resources mentioned.
Youtube Comments Extraction and Sentiment Analysis Flask App Hey, guys in this blog we will implement Youtube Comments Extraction and Sentiment Analysis in Python using Flask. This is one of the best Machine learning projects with source code in Python. Check out the demo here… [link] 21. Check out the demo here… [link] 24.
This is one of the best Machine Learning Projects for final year in Python. Youtube Comments Extraction and Sentiment Analysis Flask App Hey, guys in this blog we will implement Youtube Comments Extraction and Sentiment Analysis in Python using Flask. Check out the demo here… [link] 21. Check out the demo here… [link] 24.
The Demo: Autoscaling with MLOps. In this demo, we are completely unattended. You interact with everything via our Python clients wrapping our API endpoints. If you want to take this demo and rip out a few parts to incorporate into your production code, you’re free to do so.
You can choose between Python or R programming languages. Moreover, you will also learn the use of clustering and dimensionality reduction algorithms. This makes it easier for you to understand the algorithm and the different techniques used in Machine Learning.
We demonstrate the approach using batch inference on Amazon Bedrock: We access the Amazon Bedrock Python SDK in JupyterLab on an Amazon SageMaker notebook instance. We use Cohere Command and AI21 Labs Jurassic-2 Mid for this demo. bedrock-python-sdk-reinvent/botocore-*.whl bedrock-python-sdk-reinvent/boto3-*.whl
Usually, if the dataset or model is too large to be trained on a single instance, distributed training allows for multiple instances within a cluster to be used and distribute either data or model partitions across those instances during the training process. Each account or Region has its own training instances.
or GPT-4 arXiv, OpenAlex, CrossRef, NTRS lgarma Topic clustering and visualization, paper recommendation, saved research collections, keyword extraction GPT-3.5 Currently, published research may be spread across a variety of different publishers, including free and open-source ones like those used in many of this challenge's demos (e.g.
When running this notebook on Studio, you should make sure the Python 3 (PyTorch 1.10 Demo notebook. You can use the demo notebook to send example data to already-deployed model endpoints. The demo notebook quickly allows you to get hands-on experience by querying the example data. CPU Optimized) image/kernel is used.
Confluent offers a cloud version of Kafka, but for this demo, we will use the local version using a docker setup. Once this is confirmed, run the following command to install the Kafka connector inside the container and then restart the connected cluster. However, there are still limitations based on the complexity of the data.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning. He currently is working on Generative AI for data integration.
In particular, my code is based on rospy, which, as you might guess, is a python package allowing you to write code to interact with ROS. It turned out that a better solution was to annotate data by using a clustering algorithm, in particular, I chose the popular K-means. I then trained the SVM on this dataset. in both metrics.
Their platform was developed for working with Spark and provides automated cluster management and Python-style notebooks. During this event, you can also check out the AI Expo & Demo Hall — both in-person and online — to see what companies like the ones above are doing to promote innovation in AI.
In order to take full advantage of this strategy, Prodigy is provided as a Python library and command line utility, with a flexible web application. The components are wired togther into a recipe , by adding the @recipe decorator to any Python function. Try the live demo! Human time and attention is precious.
The AWS SDK for Python (Boto3) set up. However, we recommend deleting the artifacts in SageMaker Studio or the SageMaker Studio domain if you used SageMaker Studio to follow along with this demo. Cluster similar client profiles to reduce design element variations for frugality and consistency.
Jon Krohn will introduce participants to the essential theory behind deep learning and provides interactive examples using PyTorch, TensorFlow 2, and Keras — the principal Python libraries for deep learning. With Dr. Jon Krohn you’ll also get hands-on code demos in Jupyter notebooks and strategic advice for overcoming common pitfalls.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
We cover prompts for the following NLP tasks: Text summarization Common sense reasoning Question answering Sentiment classification Translation Pronoun resolution Text generation based on article Imaginary article based on title Code for all the steps in this demo is available in the following notebook.
Then, I would use clustering techniques such as k-means or hierarchical clustering to group customers based on similarities in their purchasing behaviour. I devised a data cleaning and transformation strategy using Python scripts to standardise the data, which resolved the issue and improved the accuracy of the analysis.
This keynote will also include a live demo of transfer learning and deployment of a transformer model using Hugging Face and MLRun; showcasing how to make the whole process efficient, effective, and collaborative. This is the perfect place to witness the latest developments and advancements in the field of generative AI and beyond.
Second, while OpenAI’s GPT-4 announcement last March demoed generating website code from a hand-drawn sketch, that capability wasn’t available until after the survey closed. Third, while roughing out the HTML and JavaScript for a simple website makes a great demo, that isn’t really the problem web designers need to solve.
All the steps in this demo are available in the accompanying notebook Fine-tuning text generation GPT-J 6B model on a domain specific dataset. Solution overview In the following sections, we provide a step-by-step demonstration for fine-tuning an LLM for text generation tasks via both the JumpStart Studio UI and Python SDK.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content