This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
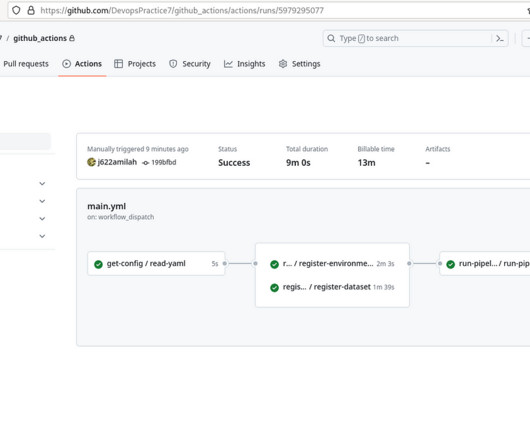
For this post we’ll use a provisioned Amazon Redshift cluster. Basic knowledge of a SQL query editor. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. A provisioned or serverless Amazon Redshift data warehouse. A SageMaker domain. Database name : Enter dev.
Atlas is a multi-cloud database service provided by MongoDB in which the developers can create clusters, databases and indexes directly in the cloud, without installing anything locally. Get Started with Atlas MongoDB Atlas After the Cluster has been created, its time to create a Database and a collection. What is MongoDB Atlas?
The prompts are managed through Lambda functions to use OpenSearch Service and Anthropic Claude 2 on Amazon Bedrock to search the client’s database and generate an appropriate response to the client’s business analysis, including the response in plain English, the reasoning, and the SQL code.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Enter a stack name, such as Demo-Redshift. This is the maximum allowed number of domains in each supported Region.
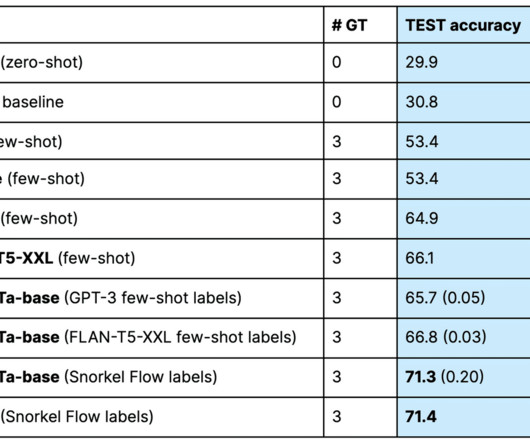
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
This Week Sentence Transformers txtai: AI-Powered Search Engine Fine-tuning Custom Datasets Data API Endpoint With SQL It’s LIT ? They fine-tuned BERT, RoBERTa, DistilBERT, ALBERT, XLNet models on siamese/triplet network structure to be used in several tasks: semantic textual similarity, clustering, and semantic search. NLP library.
And if you want to see demos of some of this functionality, be sure to join us for the livestream of the Citus 12.0 Moreover, the cluster can be rebalanced based on disk usage, such that large schemas automatically get more resources dedicated to them, while small schemas are efficiently packed together. Updates page.
Krishna Maheshwari from NeuroBlade highlighted their collaboration with the Velox community, introducing NeuroBlade’s SPU (SQL Processing Unit) and its transformative impact on Velox’s computational speed and efficiency. He shared insights into Velox Wave and Accelerators, showcasing its potential for acceleration.
I highly recommend anyone coming from a Machine Learning or Deep Learning modeling background who wants to learn about deploying models (MLOps) on a cloud platform to take this exam or an equivalent; the exam also includes topics on SQL data ingestion with Azure and Databricks, which is also a very important skill to have in Data Science.
To understand how DataRobot AI Cloud and Big Query can align, let’s explore how DataRobot AI Cloud Time Series capabilities help enterprises with three specific areas: segmented modeling, clustering, and explainability. Data scientists can leverage their SQL skills to join their own datasets with Google BigQuery publicly available data.
How to Implement Text Splitting in Snowflake Using SQL and Python UDFs We will now demonstrate how to implement the types of Text Splitting we explained in the above section in Snowflake. Among the SQL databases, PostgreSQL is one of the popular ones, as it is vector-enabled, along with Timescale, SingleStore, etc.
We had bigger sessions on getting started with machine learning or SQL, up to advanced topics in NLP, and how to make deepfakes. On both days, we had our AI Expo & Demo Hall where over a dozen of our partners set up to showcase their latest developments, tools, frameworks, and other offerings.
They’ll get you a fast answer – rather than creating an obstacle course of SQL queries that slows down your system. If we were working with a relational database, the SQL query would be awkward to construct. Request full access to our KronoGraph SDK, demos and live-coding playground. Traversal queries are especially handy.
It covers essential topics such as SQL queries, data visualization, statistical analysis, machine learning concepts, and data manipulation techniques. Key Takeaways SQL Mastery: Understand SQL’s importance, join tables, and distinguish between SELECT and SELECT DISTINCT. How do you join tables in SQL?
Today’s most cutting-edge Generative AI and LLM applications are all trained using large clusters of GPU-accelerated hardware. At Snowflake Summit, NVIDIA is showing demos of its NeMo platform to show the power of these new capabilities within Snowflake. What are the Benefits of Using NVIDIA GPUs in Snowflake?
For example, if a data team wants to use an LLM to examine financial documents—something the model may perform poorly on out of the box—the team can fine-tune it on something like the Financial Documents Clustering data set. Traditional databases such as SQL or MongoDB. Book a demo today. A search engine such as Google or Bing.
Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters. Soda Core Soda Core is an open-source data quality management framework for SQL, Spark, and Pandas-accessible data. Check out the Kubeflow documentation.
It’s easy to use a different SQL backend, or to specify a custom storage solution. Try the live demo! However, the unsupervised algorithm won’t usually return clusters that map neatly to the labels you care about. To keep the system requirements to a minimum, data is stored in an SQLite database by default.
You see them all the time with a headline like: “data science, machine learning, Java, Python, SQL, or blockchain, computer vision.” We assume that they want to do stuff they normally would, with Python, SQL, and PySpark, with data frames. It can be a cluster run by Kubernetes or maybe something else. It’s two things.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
I did not realize as Chris demoed his prototype PhD system that it would become Tableau Desktop , a product used today by millions of people around the world to see and understand data, including in Fortune 500 companies, classrooms, and nonprofit organizations. Gestalt properties including clusters are salient on scatters.
This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. This allowed them to focus on SQL-based query optimization to the nth degree. They also put process automation in place to quickly set up and take down clusters.
I did not realize as Chris demoed his prototype PhD system that it would become Tableau Desktop , a product used today by millions of people around the world to see and understand data, including in Fortune 500 companies, classrooms, and nonprofit organizations. Gestalt properties including clusters are salient on scatters.
We ask this during product demos, user and support calls, and on our MLOps LIVE podcast. Orchestrators are concerned with lower-level abstractions like machines, instances, clusters, service-level grouping, replication, and so on. Why are you building an ML platform?
For example, there has been a lot of hype around translating natural language to things like SQL so that it’s a little bit easier to do data discovery and things like that. A lot of them are demos at that point, they’re still not products. There are lots of demos out there. Try to build a couple of use cases.
On the Add additional capacity page, select Developer edition (for this demo) and choose Next. On the Configure sync settings page, under Sync scope , provide the following information: For SQL query , enter the SQL query and column values as follows: select * from employees.amazon_review. Choose Next.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content