
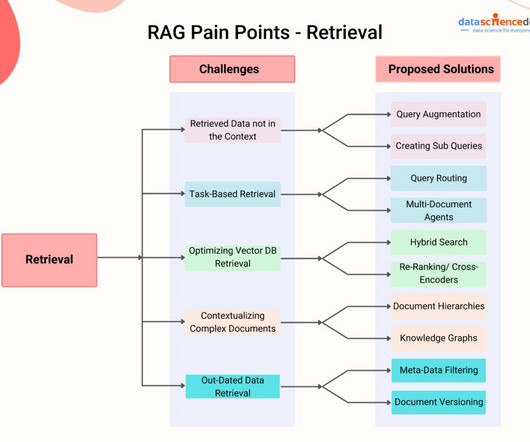
Convert Text Documents to a TF-IDF Matrix with tfidfvectorizer
KDnuggets
SEPTEMBER 7, 2022
Convert text documents to vectors using TF-IDF vectorizer for topic extraction, clustering, and classification.

KDnuggets
SEPTEMBER 7, 2022
Convert text documents to vectors using TF-IDF vectorizer for topic extraction, clustering, and classification.

Towards AI
OCTOBER 31, 2024
By Vatsal Saglani This article explores the creation of PDF2Pod, a NotebookLM clone that transforms PDF documents into engaging, multi-speaker podcasts. The method effectively captures both long-term trends and short-term dependencies, providing a more nuanced understanding of dynamic data compared to traditional clustering methods.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

DECEMBER 6, 2023
The model then uses a clustering algorithm to group the sentences into clusters. The sentences that are closest to the center of each cluster are selected to form the summary. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks.

NOVEMBER 27, 2024
dbt helps manage data transformation by enabling teams to deploy analytics code following software engineering best practices such as modularity, continuous integration and continuous deployment (CI/CD), and embedded documentation. In this case, add the intended IAM role to the source Aurora MySQL cluster.

Data Science Dojo
JULY 15, 2024
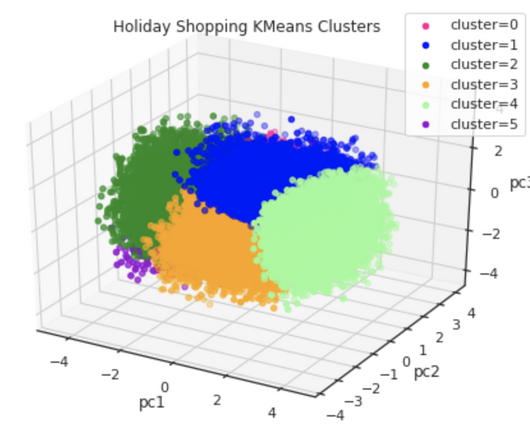
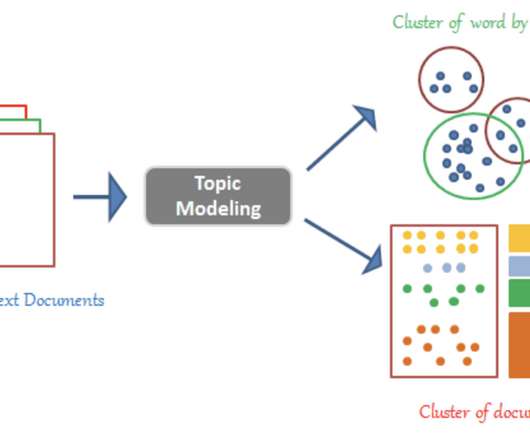
Text Analysis: Feature extraction might involve extracting keywords, sentiment scores, or topic information from text data for tasks like sentiment analysis or document classification. Clustering Algorithms: Clustering algorithms can group data points with similar features. Points far away from others are considered anomalies.

IBM Data Science in Practice
AUGUST 23, 2023
Improve Cluster Balance with the CPD Scheduler — Part 1 The default Kubernetes (“k8s”) scheduler can be thought of as a sort of “greedy” scheduler, in that it always tries to place pods on the nodes that have the most free resources. This frequently exacerbates cluster imbalance. This can lead to performance problems and even outages.
AWS Machine Learning Blog
SEPTEMBER 8, 2023
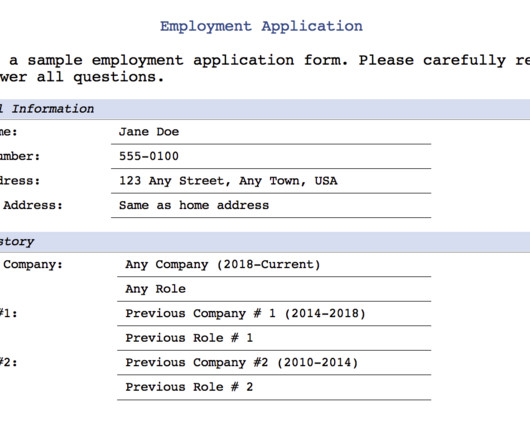
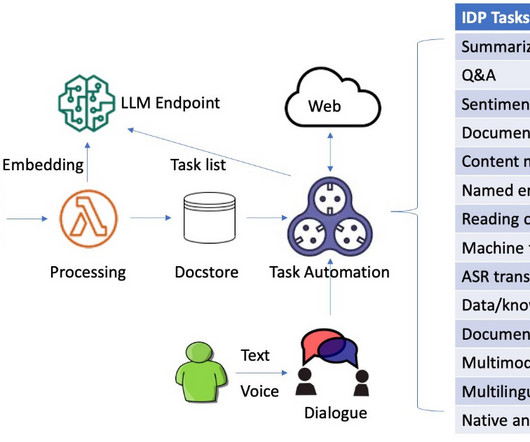
For modern companies that deal with enormous volumes of documents such as contracts, invoices, resumes, and reports, efficiently processing and retrieving pertinent data is critical to maintaining a competitive edge. What if there was a way to process documents intelligently and make them searchable in with high accuracy?

Expert insights. Personalized for you.


































Let's personalize your content