This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now, in the realm of geographic information systems (GIS), professionals often experience a complex interplay of emotions akin to the love-hate relationship one might have with neighbors. Enter KNearestNeighbor (k-NN), a technique that personifies the very essence of propinquity and Neighborly dynamics.
K-NearestNeighbors (KNN): This method classifies a data point based on the majority class of its Knearestneighbors in the training data. Distance-based Methods: These methods measure the distance of a data point from its nearestneighbors in the feature space. shirt, pants). shirt, pants).
You can then run searches for the top Kdocuments in an index that are most similar to a given query vector, which could be a question, keyword, or content (such as an image, audio clip, or text) that has been encoded by the same ML model. A right-sized cluster will keep this compressed index in memory.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster.
We shall look at various types of machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can call their libraries in R studios, including executing the code. In-depth Documentation- R facilitates repeatability by analyzing data using a script-based methodology.
k-NearestNeighbors (k-NN) k-NN is a simple algorithm that classifies new instances based on the majority class among its knearest neighbours in the training dataset. K-Means ClusteringK-means clustering partitions data into k distinct clusters based on feature similarity.
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. The implementation included a provisioned three-node sharded OpenSearch Service cluster.
For more information on managing credentials securely, see the AWS Boto3 documentation. For example: aws s3 cp /Users/username/Documents/training/loafers s3://footwear-dataset/ --recursive Confirm the upload : Go back to the S3 console, open your bucket, and verify that the images have been successfully uploaded to the bucket.
Classification algorithms include logistic regression, k-nearestneighbors and support vector machines (SVMs), among others. K-means clustering is commonly used for market segmentation, documentclustering, image segmentation and image compression.
These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests. This approach allows for tailored responses and processes for different types of user needs, whether its a simple question, a document translation, or a complex inquiry about IDIADAs services.
For example, term frequency–inverse document frequency (TF-IDF) ( Figure 7 ) is a popular text-mining technique in content-based recommendations. Inverse document frequency (IDF) assigns weight inversely proportional to the times the keyword occurs in the whole corpus. Several clustering algorithms (e.g.,
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts natural language text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
OpenSearch Service currently has tens of thousands of active customers with hundreds of thousands of clusters under management processing trillions of requests per month. Solution overview. The key AWS services used to implement this solution are OpenSearch Service, SageMaker, Lambda, and Amazon S3. Prerequisites.
Implementing this unified image and text search application consists of two phases: k-NN reference index – In this phase, you pass a set of corpus documents or product images through a CLIP model to encode them into embeddings. You save those embeddings into a k-NN index in OpenSearch Service.
You will create a connector to SageMaker with Amazon Titan Text Embeddings V2 to create embeddings for a set of documents with population statistics. Alternately, you can follow the Boto 3 documentation to make sure you use the right credentials. Choose your domains dashboard. Examine the code in run_rag.py.
Spotify also establishes a taste profile by grouping the music users often listen into clusters. These clusters are not based on explicit attributes (e.g., In this, each playlist is considered as an ordered ‘document’ of songs. text mining, K-nearestneighbor, clustering, matrix factorization, and neural networks).
Clustering: An unsupervised Machine Learning technique that groups similar data points based on their inherent similarities. D Data Mining : The process of discovering patterns, insights, and knowledge from large datasets using various techniques such as classification, clustering, and association rule learning.
Most dominant colors in an image using KMeans clustering In this blog, we will find the most dominant colors in an image using the K-Means clustering algorithm, this is a very interesting project and personally one of my favorites because of its simplicity and power. So without any further due.
Image classification Text categorization Document sorting Sentiment analysis Medical image diagnosis Advantages Pool-based active learning can leverage relationships between data points through techniques like density-based sampling and cluster analysis. These applications uses large pool of unlabeled dataset.
Xuechen Li, Daogao Liu, Tatsunori Hashimoto, Huseyin A Inan, Janardhan Kulkarni, YinTat Lee, Abhradeep Guha Thakurta End-to-End Learning to Index and Search in Large Output Spaces Nilesh Gupta, Patrick H.
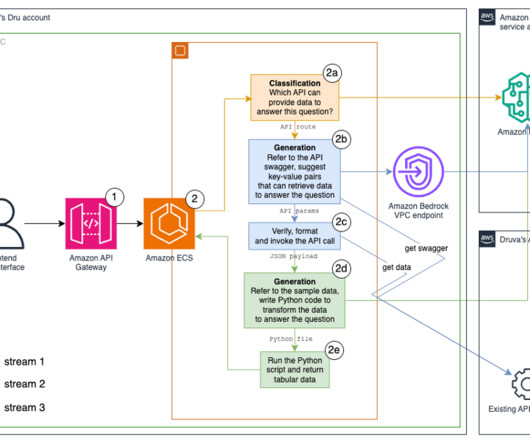
Intelligent responses and a direct conduit to Druva’s documentation – Users can gain in-depth knowledge about product features and functionalities without manual searches or watching training videos. The request arrives at the microservice on our existing Amazon Elastic Container Service (Amazon ECS) cluster.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content