This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By understanding machinelearning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! Predict traffic jams by learning patterns in historical traffic data. Learn in detail about machinelearning algorithms 2.
By Vatsal Saglani This article explores the creation of PDF2Pod, a NotebookLM clone that transforms PDF documents into engaging, multi-speaker podcasts. The method effectively captures both long-term trends and short-term dependencies, providing a more nuanced understanding of dynamic data compared to traditional clustering methods.
Machines, artificial intelligence (AI), and unsupervised learning are reshaping the way businesses vie for a place under the sun. With that being said, let’s have a closer look at how unsupervised machinelearning is omnipresent in all industries. What Is Unsupervised MachineLearning?
As a global leader in agriculture, Syngenta has led the charge in using data science and machinelearning (ML) to elevate customer experiences with an unwavering commitment to innovation. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
Welcome to this comprehensive guide on Azure MachineLearning , Microsoft’s powerful cloud-based platform that’s revolutionizing how organizations build, deploy, and manage machinelearning models. This is where Azure MachineLearning shines by democratizing access to advanced AI capabilities.
10 Python packages for data science and machinelearning In this article, we will highlight some of the top Python packages for data science that aspiring and practicing data scientists should consider adding to their toolbox. Scikit-learn Scikit-learn is a powerful library for machinelearning in Python.
Summary: MachineLearning algorithms enable systems to learn from data and improve over time. Introduction MachineLearning algorithms are transforming the way we interact with technology, making it possible for systems to learn from data and improve over time without explicit programming.
This post is divided into three parts; they are: Building a Semantic Search Engine DocumentClusteringDocument Classification If you want to find a specific document within a collection, you might use a simple keyword search.
Classification in machinelearning involves the intriguing process of assigning labels to new data based on patterns learned from training examples. Machinelearning models have already started to take up a lot of space in our lives, even if we are not consciously aware of it. 0 or 1, yes or no, etc.).
Within seconds of transactional data being written into Amazon Aurora (a fully managed modern relational database service offering performance and high availability at scale), the data is seamlessly made available in Amazon Redshift for analytics and machinelearning. You can review and customize it to suit your needs.
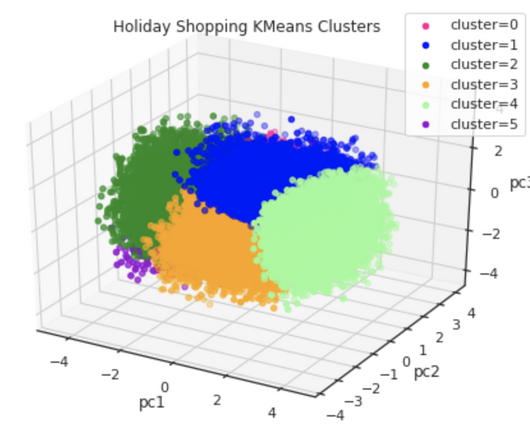
The model then uses a clustering algorithm to group the sentences into clusters. The sentences that are closest to the center of each cluster are selected to form the summary. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks.
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
For modern companies that deal with enormous volumes of documents such as contracts, invoices, resumes, and reports, efficiently processing and retrieving pertinent data is critical to maintaining a competitive edge. What if there was a way to process documents intelligently and make them searchable in with high accuracy?
Machinelearning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. What is machinelearning?
This allows SageMaker Studio users to perform petabyte-scale interactive data preparation, exploration, and machinelearning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure. This same interface is also used for provisioning EMR clusters.
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
Created by the author with DALL E-3 R has become very ideal for GIS, especially for GIS machinelearning as it has topnotch libraries that can perform geospatial computation. R has simplified the most complex task of geospatial machinelearning. Advantages of Using R for MachineLearning 1.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machinelearning (ML) or generative AI. You can view and create EMR clusters directly through the SageMaker notebook. This post is cowritten with Isaac Cameron and Alex Gnibus from Tecton.
MLFlow MachineLearning flow MLflow has unique features and characteristics that differentiate it from other MLOps tools, making it appealing to users with specific requirements or preferences: Modularity : One of MLflow’s most significant advantages is its modular architecture.
For example, imagine a consulting firm that manages documentation for multiple healthcare providerseach customers sensitive patient records and operational documents must remain strictly separated. Using the query embedding and the metadata filter, relevant documents are retrieved from the knowledge base.
With the emergence of ARCGISpro which will replace ArcMap by 2026 mainly focusing on data science and machinelearning, all the signs that machinelearning is the future of GIS and you might have to learn some principles of data science, but where do you start, let us have a look. GIS Random Forest script.
Machinelearning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. For reference, GPT-3, an earlier generation LLM has 175 billion parameters and requires months of non-stop training on a cluster of thousands of accelerated processors.
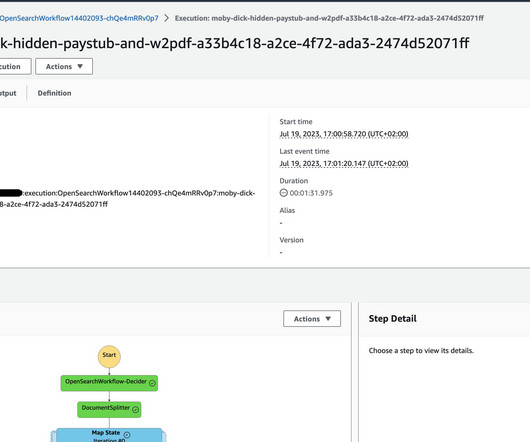
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. For documentation retrieval, Retrieval Augmented Generation (RAG) stands out as a key tool. Virginia) AWS Region. The following diagram illustrates the solution architecture.
Here at Snorkel AI, we devote our time to building and maintaining our machine-learning development platform, Snorkel Flow. Snorkel Flow handles intense machinelearning workloads, and we’ve built our infrastructure on a foundation of Kubernetes—which was not designed with machinelearning in mind.
Here at Snorkel AI, we devote our time to building and maintaining our machine-learning development platform, Snorkel Flow. Snorkel Flow handles intense machinelearning workloads, and we’ve built our infrastructure on a foundation of Kubernetes—which was not designed with machinelearning in mind.
10 Python packages for data science and machinelearning In this article, we will highlight some of the top Python packages for data science that aspiring and practicing data scientists should consider adding to their toolbox. Scikit-learn Scikit-learn is a powerful library for machinelearning in Python.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machinelearning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
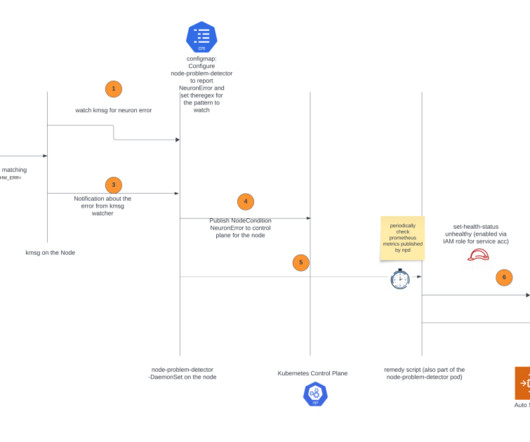
Solution overview The solution is based on the node problem detector and recovery DaemonSet, a powerful tool designed to automatically detect and report various node-level problems in a Kubernetes cluster. Choose Clusters in the navigation pane, open the trainium-inferentia cluster, choose Node groups, and locate your node group. #
State of MachineLearning Survey Results Part One We recently shared a survey about the current state of machinelearning. Tesla’s Automated Driving Documents Have Been Requested by The U.S. In the first of two articles, we’d like to share the results, starting with the technical side of things.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machinelearning (ML) solutions without writing code. Prepare data for machinelearning.
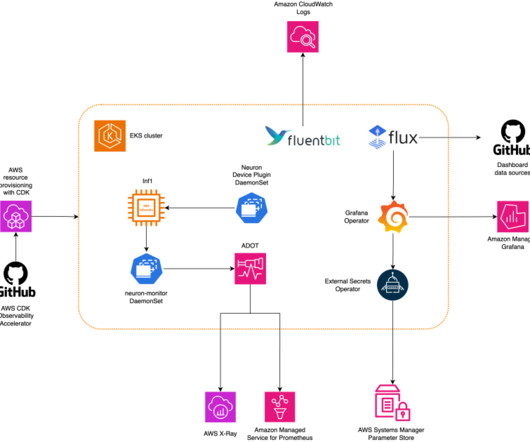
Recent developments in machinelearning (ML) have led to increasingly large models, some of which require hundreds of billions of parameters. The pattern is part of the AWS CDK Observability Accelerator , a set of opinionated modules to help you set observability for Amazon EKS clusters.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. Under Settings , enter a name for your database cluster identifier. Each unit can support up to 20,000 documents. Choose Create database. Choose Next.
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machinelearning (ML) models into vectors (numerical encodings). A right-sized cluster will keep this compressed index in memory.
Data archiving is the systematic process of securely storing and preserving electronic data, including documents, images, videos, and other digital content, for long-term retention and easy retrieval. Lastly, data archiving allows organizations to preserve historical records and documents for future reference.
These longer sequence lengths allow models to better understand long-range dependencies in text, generate more globally coherent outputs, and handle tasks requiring analysis of lengthy documents. After they’re initiated, SageMaker training jobs spin up the cluster, provisioning the specified number and type of compute instances.
But what exactly is distributed learning in machinelearning? In this article, we will explore the concept of distributed learning and its significance in the realm of machinelearning. Why is it so important? This process is often referred to as training or model optimization.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machinelearning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
At the end of the day, why not use an AutoML package (Automated MachineLearning) or an Auto-Forecasting tool and let it do the job for you? However, we already know that: MachineLearning models deliver better results in terms of accuracy when we are dealing with interrelated series and complex patterns in our data.
It is used for machinelearning, natural language processing, and computer vision tasks. Scikit-learn Scikit-learn is an open-source machinelearning library for Python. It is one of the most popular machinelearning libraries in the world, and it is used by a wide range of businesses and organizations.
Have you ever faced the challenge of obtaining high-quality data for fine-tuning your machinelearning (ML) models? For instance, when developing a medical search engine, obtaining a large dataset of real user queries and relevant documents is often infeasible due to privacy concerns surrounding personal health information.
Document Vectors With the success of word embeddings , it’s understood that entire documents can be represented in a similar way. Document Vectors With the success of word embeddings , it’s understood that entire documents can be represented in a similar way. Let’s create a table to hold our document vectors.
Here are some key ways data scientists are leveraging AI tools and technologies: 6 Ways Data Scientists are Leveraging Large Language Models with Examples Advanced MachineLearning Algorithms: Data scientists are utilizing more advanced machinelearning algorithms to derive valuable insights from complex and large datasets.
The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. This event-driven architecture provides immediate processing of new documents.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content