This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Latent Semantic Analysis and its Uses in NaturalLanguageProcessing appeared first on Analytics Vidhya. Textual data, even though very important, vary considerably in lexical and morphological standpoints. Different people express themselves quite differently when it comes to […].
Well, it’s NaturalLanguageProcessing which equips the machines to work like a human. But there is much more to NLP, and in this blog, we are going to dig deeper into the key aspects of NLP, the benefits of NLP and NaturalLanguageProcessing examples. What is NLP?
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. This same interface is also used for provisioning EMR clusters. The following diagram illustrates this solution.
NaturalLanguageProcessing (NLP): Data scientists are incorporating NLP techniques and technologies to analyze and derive insights from unstructured data such as text, audio, and video. This enables them to extract valuable information from diverse sources and enhance the depth of their analysis. H2O.ai: – H2O.ai
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption. This speeds up the PII detection process and also reduces the overall cost.
Hence, acting as a translator it converts human language into a machine-readable form. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings. Their impact on ML tasks has made them a cornerstone of AI advancements.
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis.
Data archiving is the systematic process of securely storing and preserving electronic data, including documents, images, videos, and other digital content, for long-term retention and easy retrieval. Lastly, data archiving allows organizations to preserve historical records and documents for future reference.
Faiss is a library for efficient similarity search and clustering of dense vectors. They are used in a variety of AI applications, such as image search, naturallanguageprocessing, and recommender systems. It is designed for storing and searching for large datasets of embeddings.
Transformers are a type of neural network that are well-suited for naturallanguageprocessing tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language. They are typically trained on clusters of computers or even on cloud computing platforms.
The algorithm learns to find patterns or structure in the data by clustering similar data points together. WHAT IS CLUSTERING? Clustering is an unsupervised machine learning technique that is used to group similar entities. Those groups are referred to as clusters.
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering naturallanguage questions about complex, document-based visual information. For a detailed walkthrough on fine-tuning the Meta Llama 3.2
Hence, acting as a translator it converts human language into a machine-readable form. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings. Their impact on ML tasks has made them a cornerstone of AI advancements.
Its prowess lies in naturallanguageprocessing (NLP) tasks like sentiment analysis, question-answering, and text classification. Boosting efficiency with language summarization Explore how generative AI can revolutionize IT support teams, automating tasks and expediting solutions.
Embeddings capture the information content in bodies of text, allowing naturallanguageprocessing (NLP) models to work with language in a numeric form. Then we use K-Means to identify a set of cluster centers. This allows the LLM to reference more relevant information when generating a response.
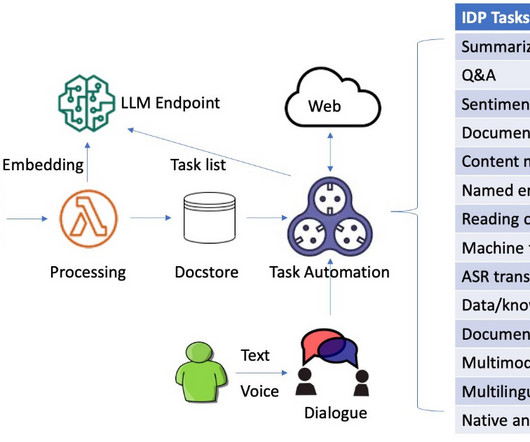
Intelligent documentprocessing (IDP) is a technology that automates the processing of high volumes of unstructured data, including text, images, and videos. Naturallanguageprocessing (NLP) is one of the recent developments in IDP that has improved accuracy and user experience.
They don’t capture the full context of a document, making them less effective in dealing with unstructured data. Embeddings are generated by representational language models that translate text into numerical vectors and encode contextual information in a document.
For reference, GPT-3, an earlier generation LLM has 175 billion parameters and requires months of non-stop training on a cluster of thousands of accelerated processors. The Carbontracker study estimates that training GPT-3 from scratch may emit up to 85 metric tons of CO2 equivalent, using clusters of specialized hardware accelerators.
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. For example, let’s say you had a collection of customer emails or online product reviews.
It is used for machine learning, naturallanguageprocessing, and computer vision tasks. TensorFlow First on the AI tool list, we have TensorFlow which is an open-source software library for numerical computation using data flow graphs.
In this post, we explore the concept of querying data using naturallanguage, eliminating the need for SQL queries or coding skills. NaturalLanguageProcessing (NLP) and advanced AI technologies can allow users to interact with their data intuitively by asking questions in plain language.
Load CSV data using LangChain CSV loader LangChain CSV loader loads csv data with a single row per document. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. read_csv ( dataset.name) return df.
With IBM Watson NLP, IBM introduced a common library for naturallanguageprocessing, document understanding, translation, and trust. This tutorial walks you through the steps to serve pretrained Watson NLP models using Knative Serving in a Red Hat OpenShift cluster. For more information see [link].
And retailers frequently leverage data from chatbots and virtual assistants, in concert with ML and naturallanguageprocessing (NLP) technology, to automate users’ shopping experiences. K-means clustering is commonly used for market segmentation, documentclustering, image segmentation and image compression.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. Clusters are provisioned with the instance type and count of your choice and can be retained across workloads. As a result of this flexibility, you can adapt to various scenarios.
These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests. This approach allows for tailored responses and processes for different types of user needs, whether its a simple question, a document translation, or a complex inquiry about IDIADAs services.
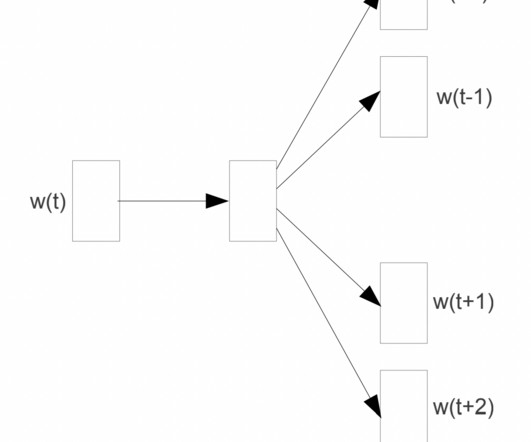
NLP A Comprehensive Guide to Word2Vec, Doc2Vec, and Top2Vec for NaturalLanguageProcessing In recent years, the field of naturallanguageprocessing (NLP) has seen tremendous growth, and one of the most significant developments has been the advent of word embedding techniques. DM Architecture.
Tensor Processing Units (TPUs) Developed by Google, TPUs are optimized for Machine Learning tasks, providing even greater efficiency than traditional GPUs for specific applications. The demand for advanced hardware continues to grow as organisations seek to develop more sophisticated Generative AI applications.
We also demonstrate how you can engineer prompts for Flan-T5 models to perform various naturallanguageprocessing (NLP) tasks. Task Prompt (template in bold) Model output Summarization Briefly summarize this paragraph: Amazon Comprehend uses naturallanguageprocessing (NLP) to extract insights about the content of documents.
LOAD CSV DATA USING LANGCHAIN CSV LOADER LangChain CSV loader loads csv data with a single row per document. Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. Conclusion Deploying DeepSeek models on SageMaker AI provides a robust solution for organizations seeking to use state-of-the-art language models in their applications.
The applications of graph classification are numerous, and they range from determining whether a protein is an enzyme or not in bioinformatics to categorizing documents in naturallanguageprocessing (NLP) or social network analysis, among other things. How do Graph Neural Networks work?
RAG searches documents through large language model (LLM) embedding and vectoring, creates the context from search results through clustering, and uses the context as an augmented prompt to inference a foundation model to get the answer. To address these challenges, we present a new framework with RAG and fine-tuned LLMs.
For example, a health insurance company may want their question answering bot to answer questions using the latest information stored in their enterprise document repository or database, so the answers are accurate and reflect their unique business rules. Identify the top K most relevant documents based on the user query.
Solving Machine Learning Tasks with MLCoPilot: Harnessing Human Expertise for Success Many of us have made use of large language models (LLMs) like ChatGPT to generate not only text and images but also code, including machine learning code.
You can use this tutorial as a starting point for a variety of chatbot-based solutions for customer service, internal support, and question answering systems based on internal and private documents. This makes the models especially powerful at tasks such as clustering for long documents like legal text or product documentation.
image source: stoodnt Time is important in the broad domain of legal discovery, where mountains of documents hide the answers to difficult cases. Every minute spent digesting jargon-filled texts and searching through mountains of legal documents delays justice and incurs significant costs.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
A small number of similar documents (typically three) is added as context along with the user question to the “prompt” provided to another LLM and then that LLM generates an answer to the user question using information provided as context in the prompt. Chunking of knowledge base documents. Implementing the question answering task.
Text representation with Embed – Developers can access endpoints that capture the semantic meaning of text, enabling applications such as vector search engines, text classification and clustering, and more. Cohere Embed comes in two forms, an English language model and a multilingual model, both of which are now available on Amazon Bedrock.
NaturalLanguageProcessing (NLP) : Classification can be applied to text data to categorize messages, emails, or social media posts into different categories, such as spam vs. non-spam, positive vs. negative sentiment, or topic classification.
It optimises decision trees, probabilistic models, clustering, and reinforcement learning. Entropy enhances clustering, federated learning, finance, and bioinformatics. Applications Across Algorithms and Tasks Beyond decision trees, entropy is widely used in clustering, feature selection, and reinforcement learning.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content